简介
在后端开发日常工作中,定位排查问题或是了解系统某些方面的情况时,会遇到以下的场景:
- 查询接口请求的日志。
- 查询服务的日志。
- 统计接口的每日调用数量以及时间分布。
- 统计接口每日的用户数量。
ELK(Elasticsearch + Logstash + Kibana)平台很好的完成了上述工作,并且提供了友好便利的用户界面,普遍应用于生产日志的查询分析中。ELK一句话概括:用Logstash收集日志或者数据到Elasticsearch存储起来并建立相关索引,再利用Kibana查询界面到Elasticsearch上提供的索引进行查询和统计。
- Logstash
Logstash 主要用于收集服务器日志,它是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到所选择的目的地。
Logstash 收集数据的过程主要分为以下三个部分:
输入(input):数据往往都是以不同的形式、格式存储在不同的系统中,而Logstash支持从多种数据源中收集数据(File、Syslog、MySQL、消息中间件等等)。过滤器(filter):实时解析和转换数据,识别已命名的字段以构建结构,并将它们转换成通用格式。输出(output):Elasticsearch并非存储的唯一选择,Logstash提供很多输出选择。
- Elasticsearch
Elasticsearch (ES)是一个分布式Restful风格的搜索和数据分析引擎,它具有以下特点:
查询:允许执行和合并多种类型的搜索 (结构化、非结构化、地理位置、度量指标),搜索方式随心而变。分析:Elasticsearch聚合让您能够从大处着眼,探索数据的趋势和模式。速度:很快,可以做到亿万级的数据,毫秒级返回。可扩展性:可以在笔记本电脑上运行,也可以在承载了 PB 级数据的成百上千台服务器上运行。弹性:运行在一个分布式的环境中,从设计之初就考虑到了这一点。灵活性:具备多个案例场景。支持数字、文本、地理位置、结构化、非结构化,所有的数据类型都欢迎。
- Kibana
基于浏览器的界面便于快速创建和分享动态数据仪表板来追踪 Elasticsearch 的实时数据变化。其搭建过程也十分简单,您可以分分钟完成 Kibana 的安装,并开始探索 Elasticsearch 的索引数据,没有代码、不需要额外的基础设施。
- Filebeat
ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,基于 Logstash-Forwarder 源代码开发,是对它的替代。在需要采集日志数据的服务器上安装 Filebeat,并指定·日志目录·或·日志文件·后,Filebeat 就能读取数据,迅速发送到 Logstash 进行解析,亦或直接发送到 Elasticsearch (日志不需要Logstash过滤拆分时)进行集中式存储和分析。
这四者都是开源软件,通常配合使用,而且又先后归于 Elastic.co 公司名下,所以被简称为 ELK Stack。根据 Google Trend 的信息显示,ELK Stack 已经成为目前最流行的集中式日志解决方案。
常用架构
Logstash架构
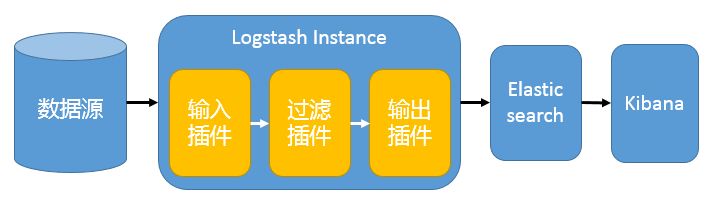
单服务
只有一个 Logstash、Elasticsearch 和 Kibana 实例。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示。
多服务
把一个 Logstash 数据搜集节点扩展到多个,分布于多台机器,将解析好的数据发送到 Elasticsearch server 进行存储,最后在 Kibana 查询、生成日志报表等。
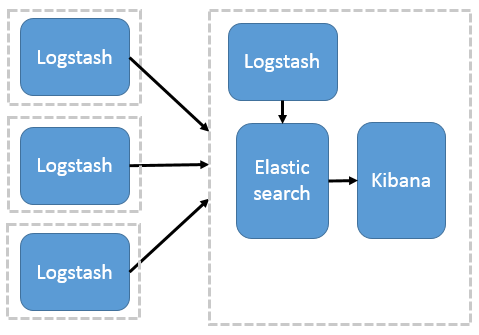
这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
Beats架构
这种架构引入 Beats 作为日志搜集器。目前 Beats 包括四种:
- Packetbeat(搜集
网络流量数据)- Topbeat(搜集
系统、进程和文件,系统级别的CPU和内存使用情况等数据)- Filebeat(搜集
文件数据)- Winlogbeat(搜集
Windows 事件日志数据)
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户。
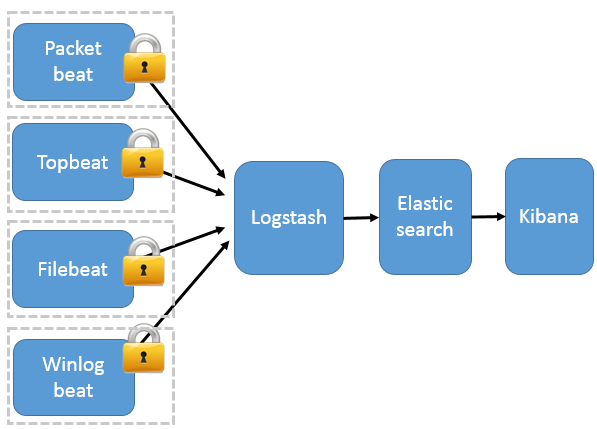
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。
消息队列架构
Beats 还不支持输出到消息队列,所以在消息队列两端只能是 Logstash 实例。这种架构使用 Logstash 从各个数据源搜集数据,然后经消息队列输出插件输出到消息队列中。目前 Logstash 支持 Kafka、Redis、RabbitMQ 等常见消息队列。然后 Logstash 通过消息队列输入插件从队列中获取数据,分析过滤后经输出插件发送到 Elasticsearch,最后通过 Kibana 展示。
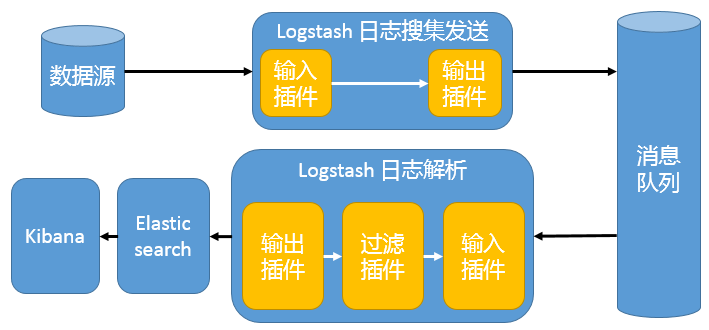
这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题。
案例实操
elastic 官网下载地址:https://www.elastic.co/cn/downloads/
安装环境及版本:
- 操作系统:虚拟机 Centos7
- JDK:1.8
- ElasticSearch:7.3.0
- Logstash:7.3.0
- Kibana:7.3.0
- filebeat :7.3.0
本案例中的软件均在
同一台服务器部署,所以host配置部分都为localhost,若是远程服务器,修改为具体ip地址即可
下面以Logstash单服务和Beats两个架构为例来进行实操详解
软件安装
JDK安装
- 下载
JDK 官网下载地址,本文使用:
jdk-8u131-linux-x64.tar.gz
- 解压安装
将JDK安装包上传到服务器,进行解压
tar -zxvf jdk-8u131-linux-x64.tar.gz |
- 修改环境变量
通过命令编辑profile文件,在文件末尾(按大写"G"移至文件末尾)添加以下内容(按"i"进入编辑):
vi /etc/profile |
路径需与安装路径相符
export JAVA_HOME=/usr/local/java |
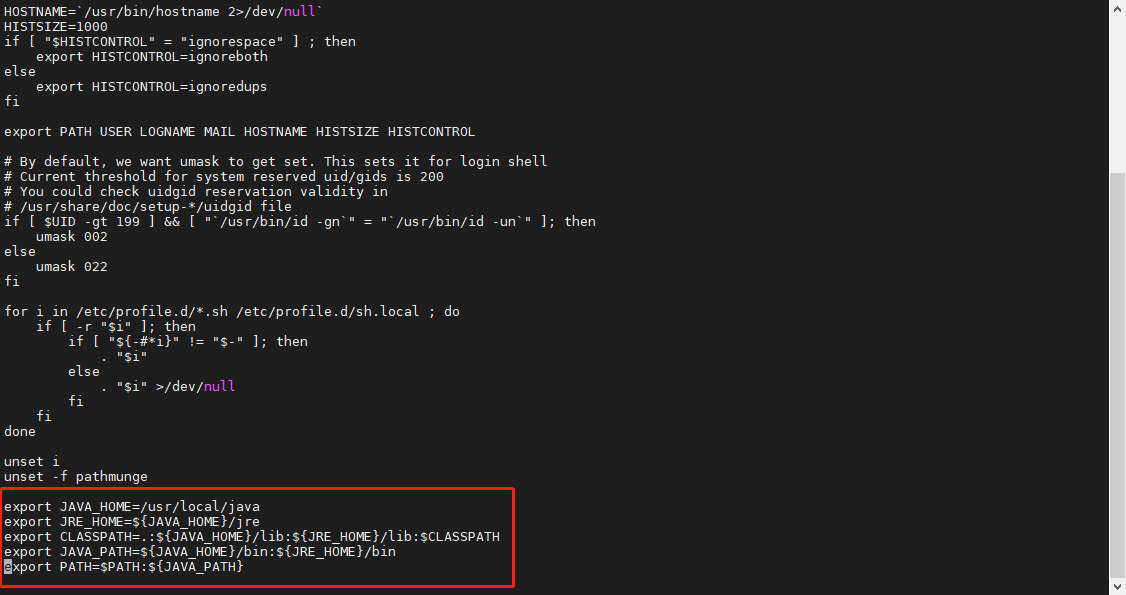
按左上方"esc"键退出编辑模式,按wq!强制保存;再通过命令source /etc/profile重载profile文件,使其生效
- 验证
通过javac和java -version命令验证,如下图所示即为安装成功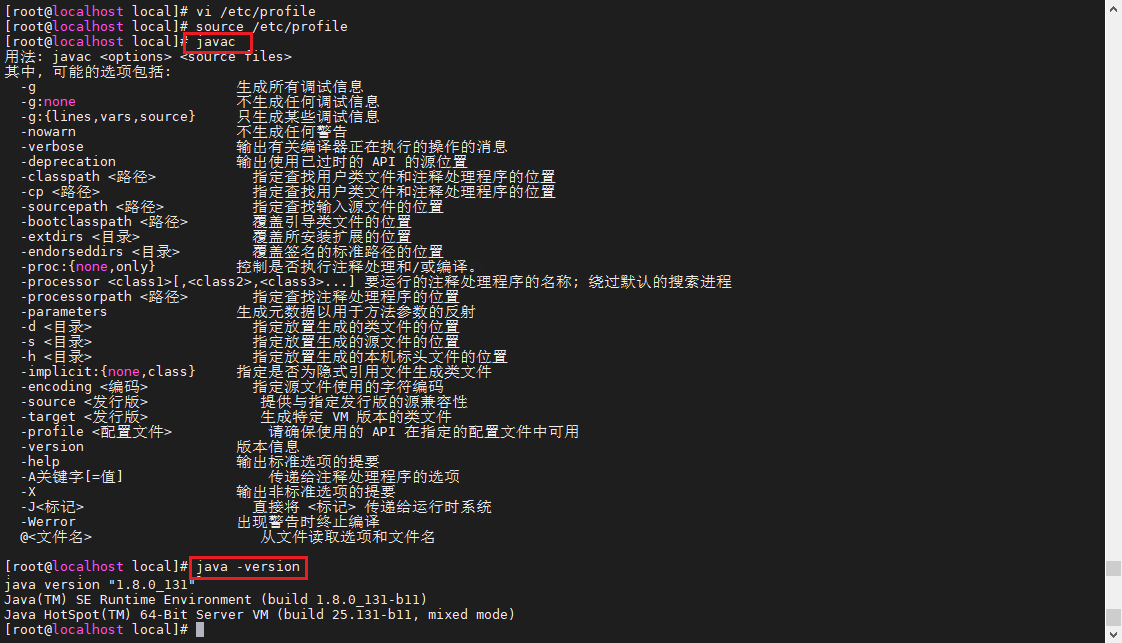
项目部署
用IDEA将Spring Boot项目打包,并部署到服务器上。进入项目jar包所在路径,执行启动命令
java -jar 包名称.jar |
本项目log4j日志配置如下,log4j基础教程
|
Logstash安装
- 解压安装
将logstash安装包上传到服务器,进行解压
tar -zxvf logstash-7.3.0.tar.gz |
- 验证
执行以下命令,验证是否安装成功
cd logstash-7.3.0 |
在控制台输入 HelloWorld ,看到如下效果代表 Logstash 安装成功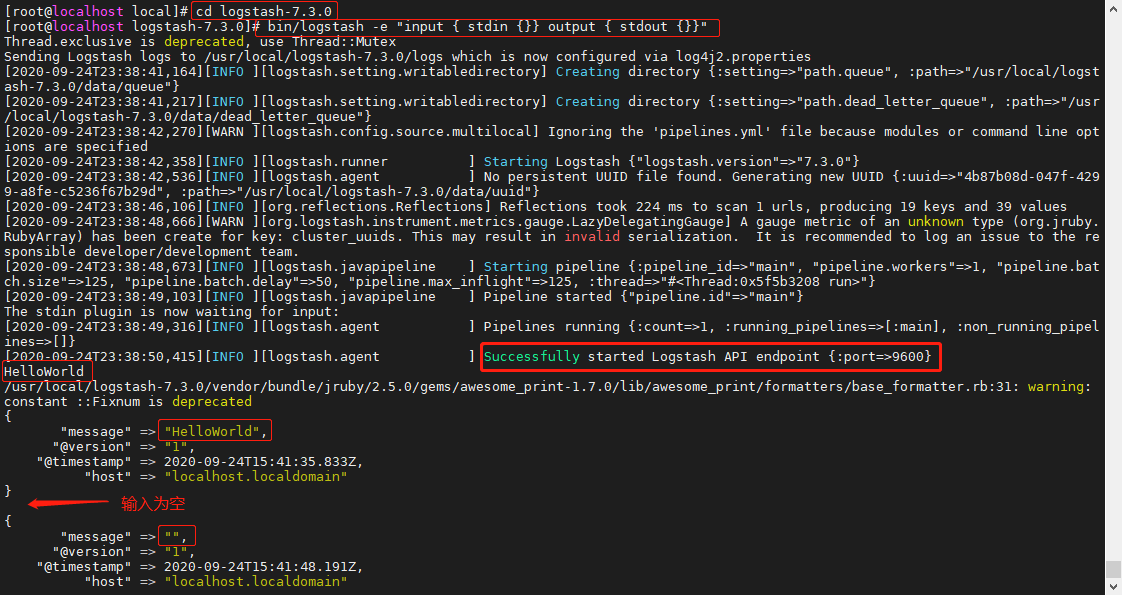
也可通过进程命令,检查logstash是否启动
ps -ef|grep logstash |
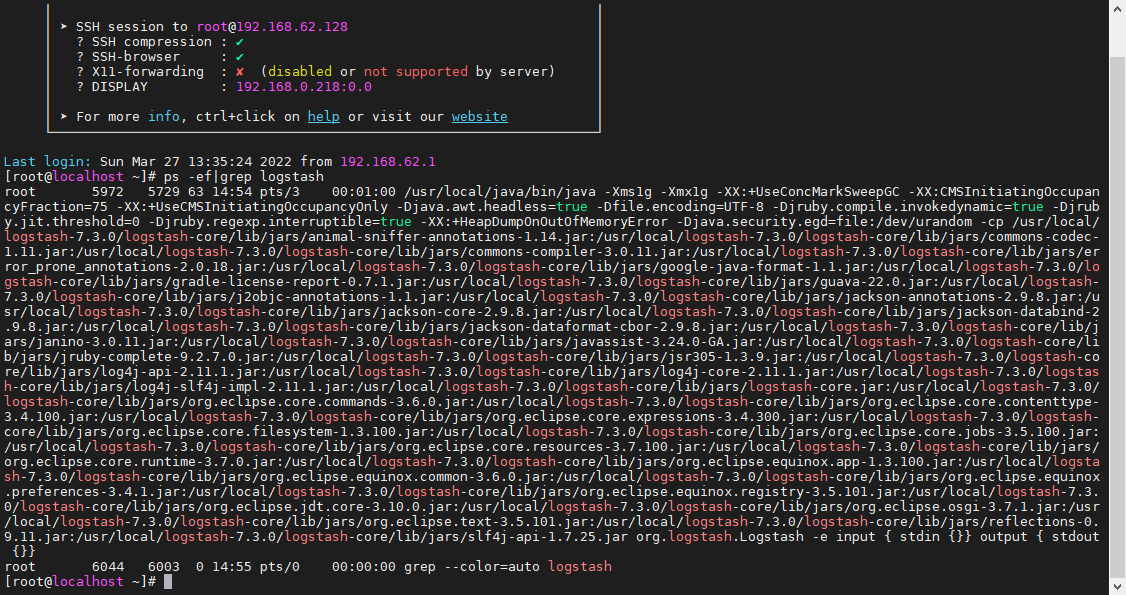
Elasticsearch安装
- 解压安装
将Elasticsearch安装包上传到服务器,进行解压
tar -zxvf elasticsearch-7.3.0-linux-x86_64.tar.gz |
- 创建用户
Elasticsearch不能用root用户启动,创建一个用户(名称随意),并赋予此用户与root同组(因为用root用户解压的包)
useradd nicky |
- 启动
启动Elasticsearch,会遇到如下两个报错问题
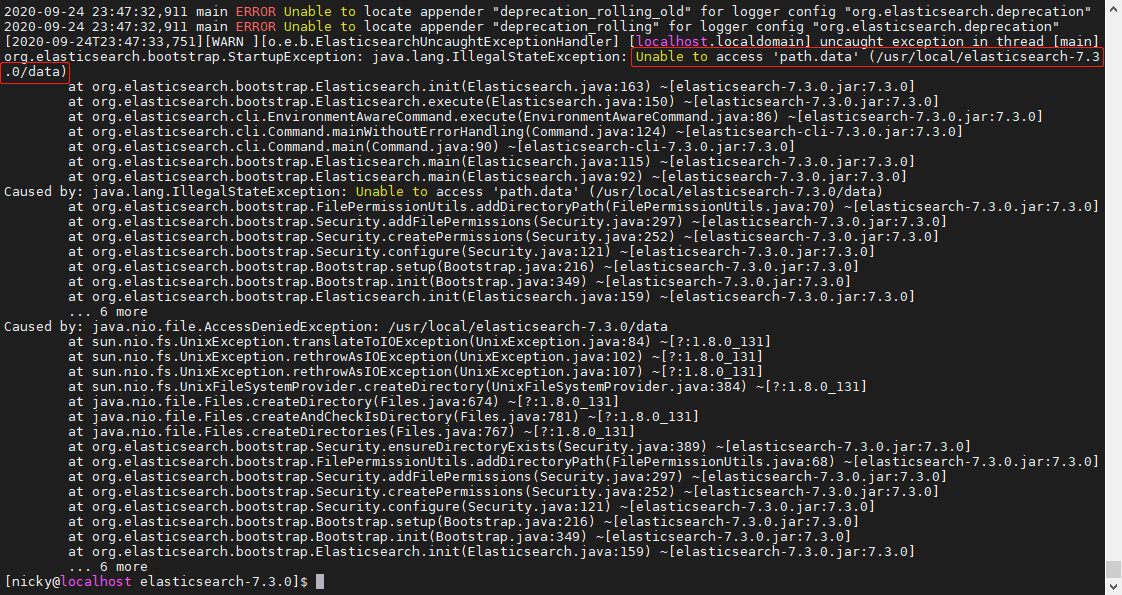

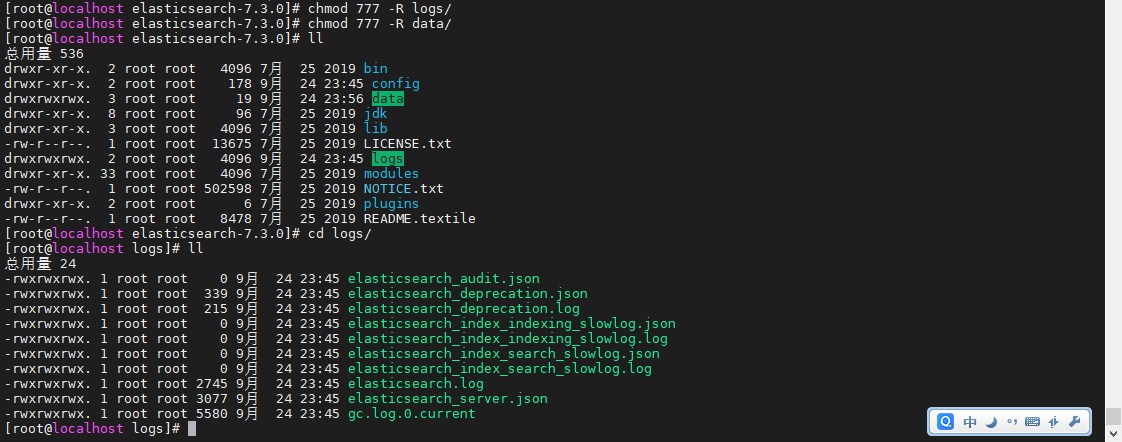
elasticsearch需在data目录和logs目录中存放与修改数据文件,因此在安装目录下创建data目录,再赋予data目录和logs目录及其子文件的读写权限
mkdir data |
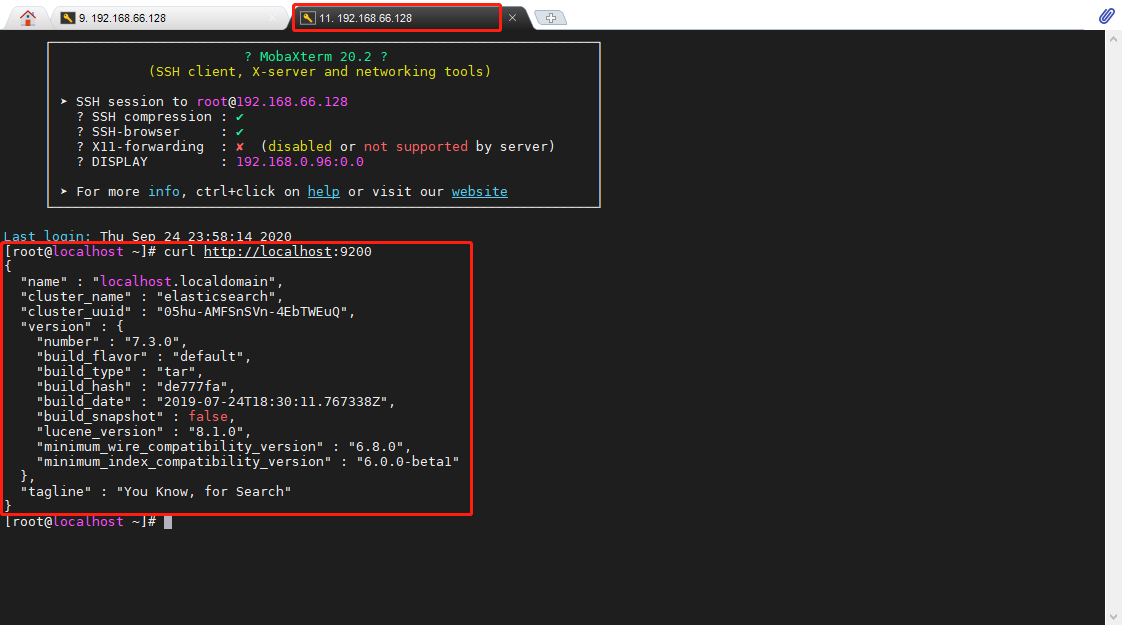
再次启动Elasticsearch,另起会话窗口执行 curl http://localhost:9200 命令,如出现如下效果,则 Elasticsearch 安装成功。
su - nicky |

Kibana安装
- 解压安装
将Kibana安装包上传到服务器,进行解压
tar -zxvf kibana-7.3.0-linux-x86_64.tar.gz |
- 启动
使用上述新建nicky用户启动 Kibana (Kibana解压安装情况下,不能使用root用户启动)
su - nicky |
在浏览器中访问 http://ip:5601(可使用hostname - I命令查询IP)
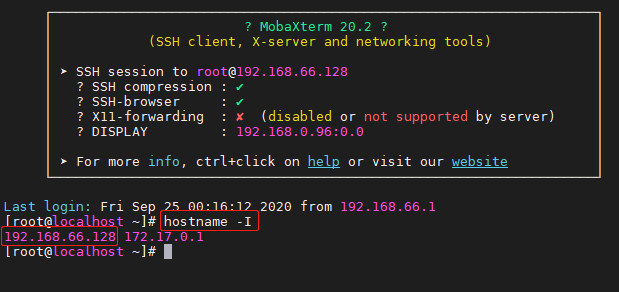
若出现以下界面,则表示 Kibana 安装成功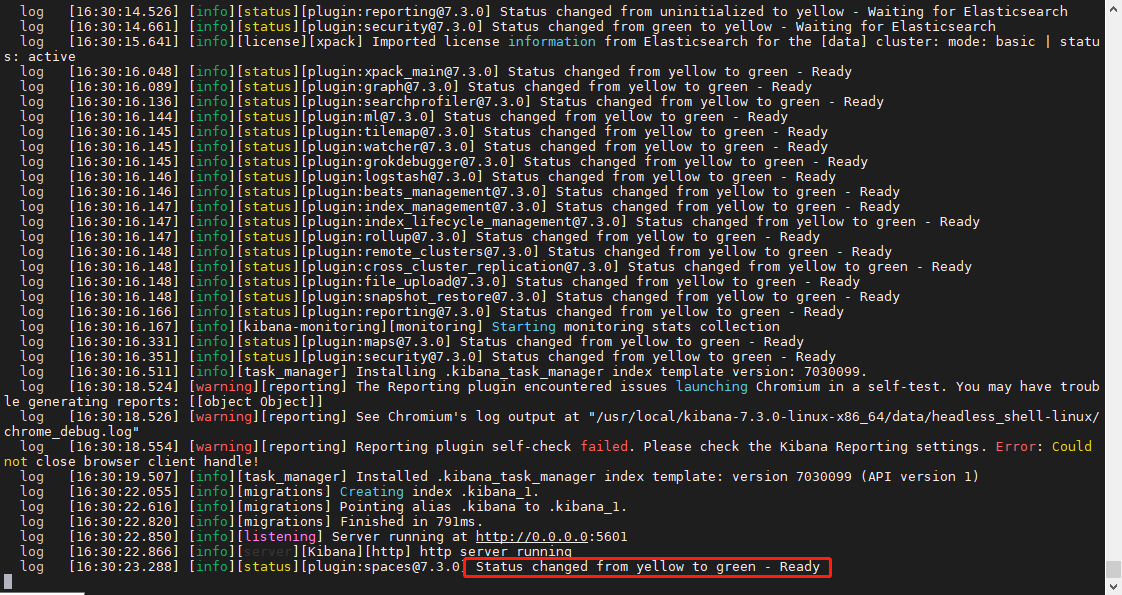
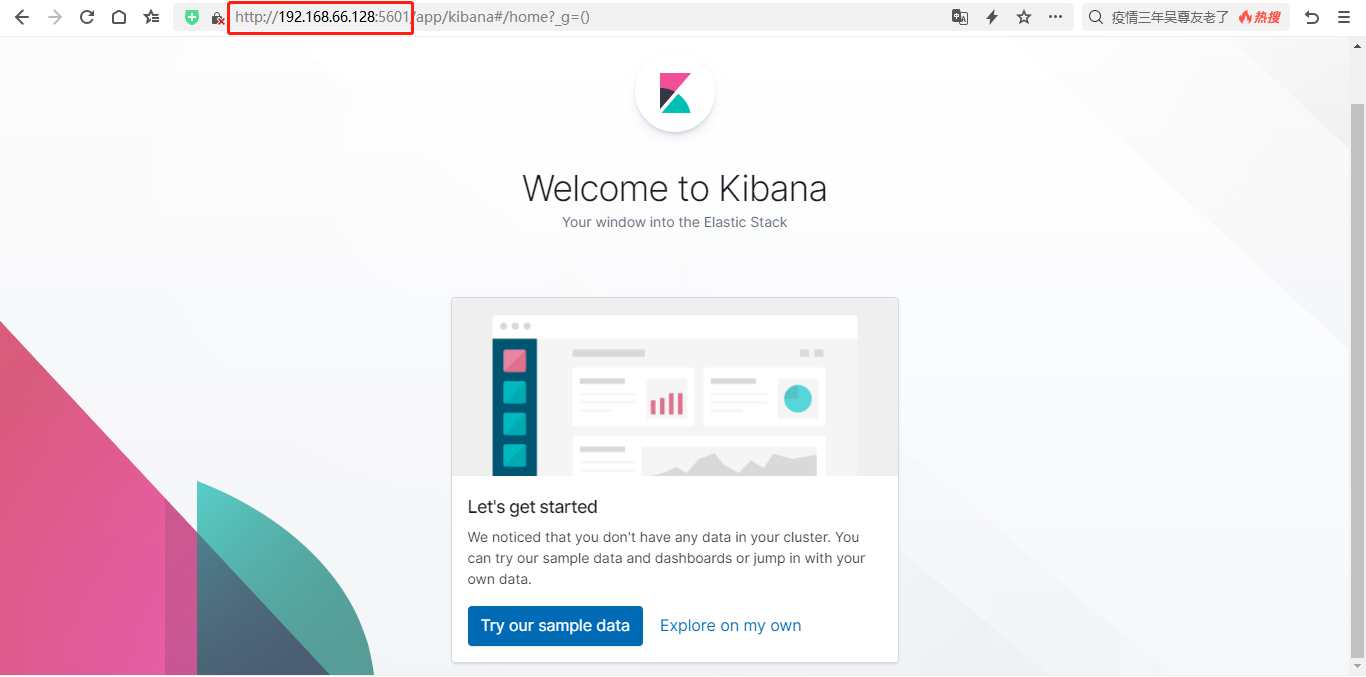
filebeat安装
- 解压安装
进入安装包所在位置,进行解压
tar -zxvf filebeat-7.3.0-linux-x86_64.tar.gz |
- 添加filebeat命令
先将filebeat命令加入到环境
# ln -s 安装路径/filebeat /usr/bin/ |
- 启动
cd filebeat-7.3.0-linux-x86_64 |
Supervisor安装
上述ELK的启动是在前台启动的,意味着如果关闭会话窗口,该组件就会停止导致整个 ELK 平台无法使用,至此使用Supervisor来管理 ELK 的启停。首先需要在服务器上安装 Supervisor (安装教程) 。安装成功后,还需要在 Supervisor 的配置文件中配置 ELK 三大组件(其配置文件默认为 /etc/supervisor/supervisord.conf 文件)。
[program:elasticsearch] |
执行sudo supervisorctl reload即可完成整个 ELK 的启动,而且其默认是开机后台自启。当然,也可以使用sudo supervisorctl start/stop program_name来管理单独的应用.
Logstash单服务部署
- 修改Logstash配置
在config/目录下创建配置文件(名称随意),并使用bin/logstash -f config/配置文件名.conf 命令启动
配置内容如下:
input { |
- 修改Kibana配置
修改配置文件 config/kibana.yml ,指定 Elasticsearch 的信息 。
如果elasticsearch没有设置密码,密码配置可去掉;
elasticsearch.hosts: "http://localhost:9200" |

- 测试
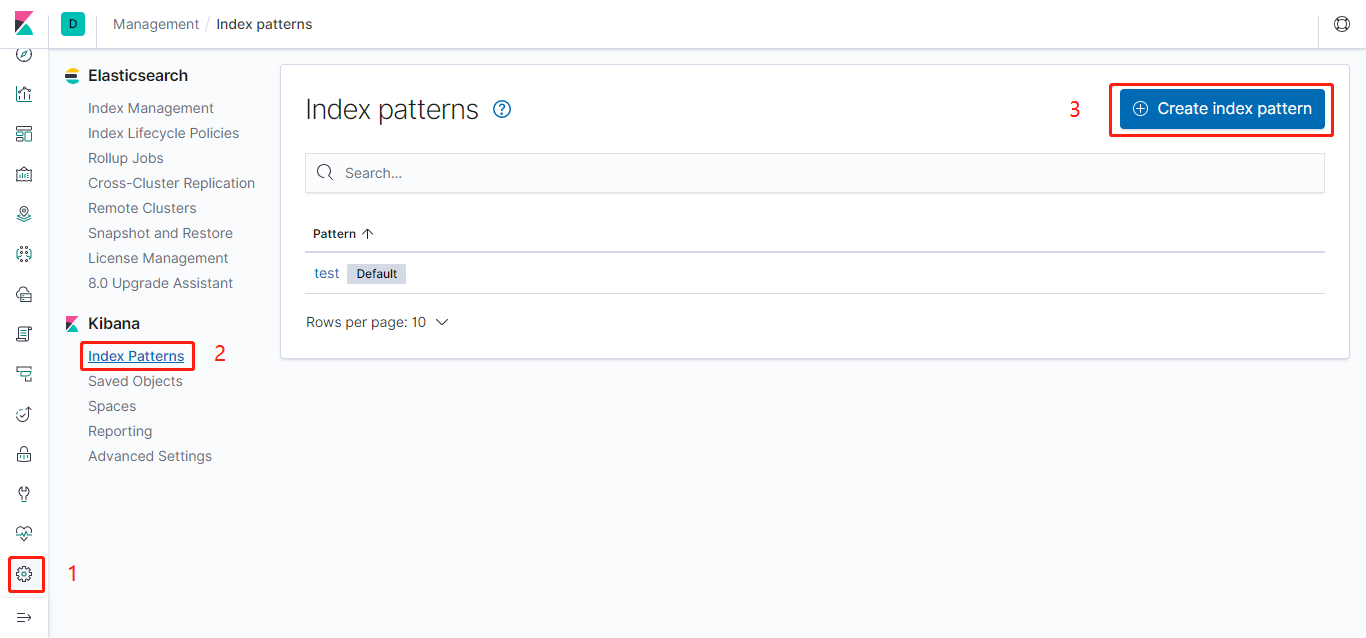
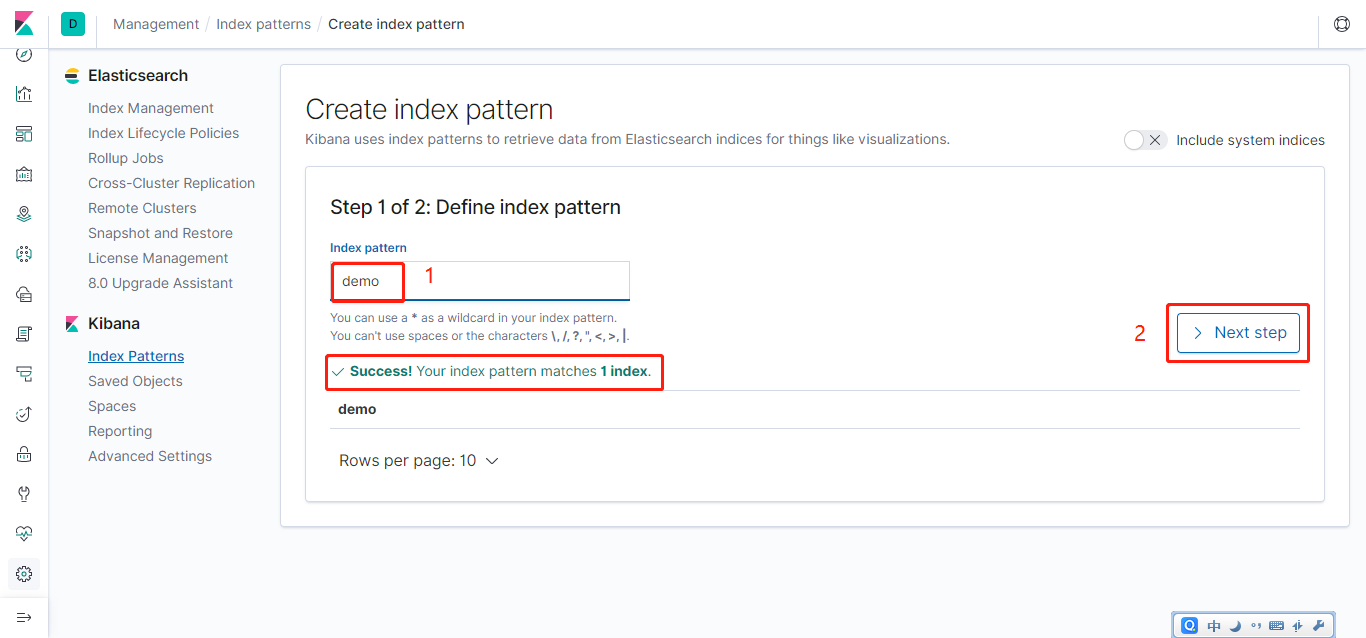
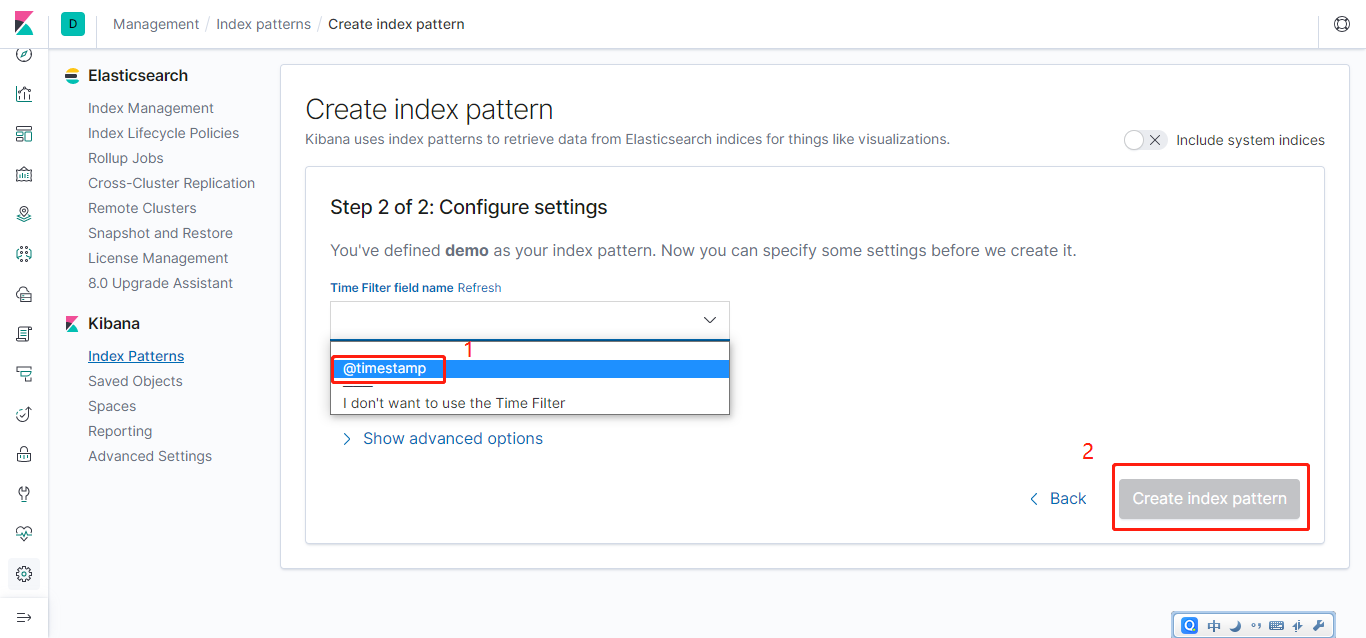
Elasticsearch默认配置即可;ELK与项目启动后,登录Kibana的web界面,关联Elasticsearch索引
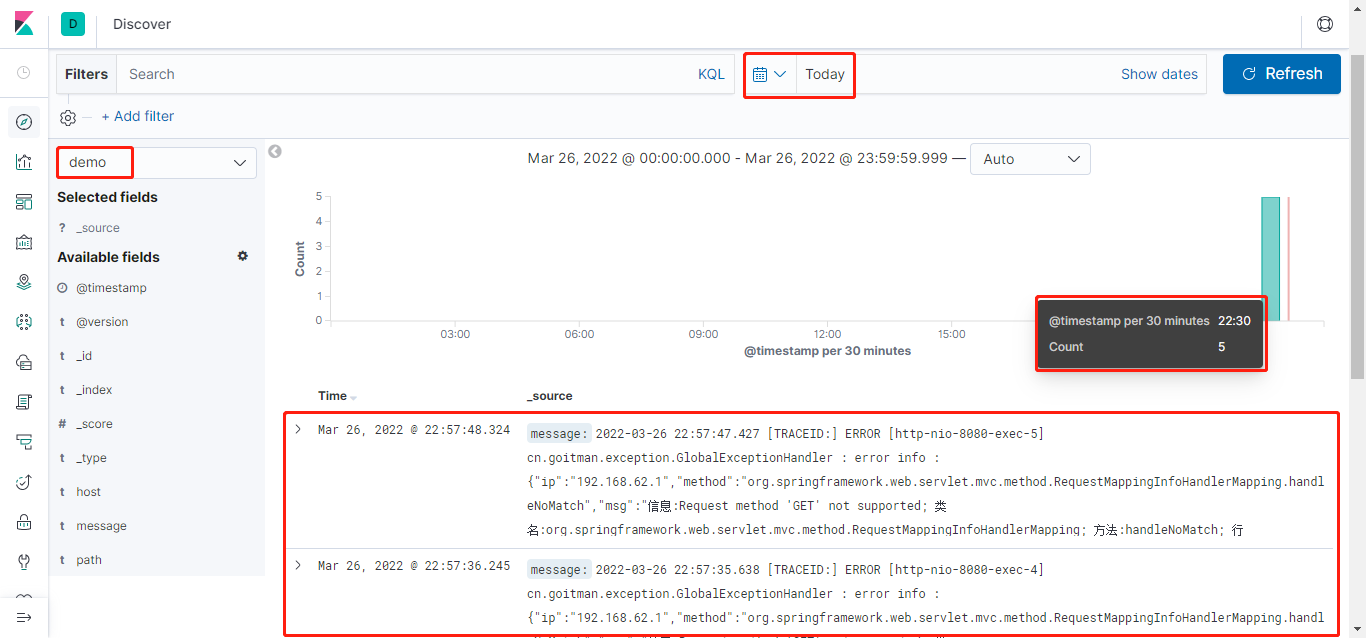
使用Postman请求接口,查看日志(环境内没有安装数据库,让其报个错吧)
项目控制台输出日志(如下三张截图,并非同一时期所截,不影响正常流程)
logstash控制台输出日志
Beats部署
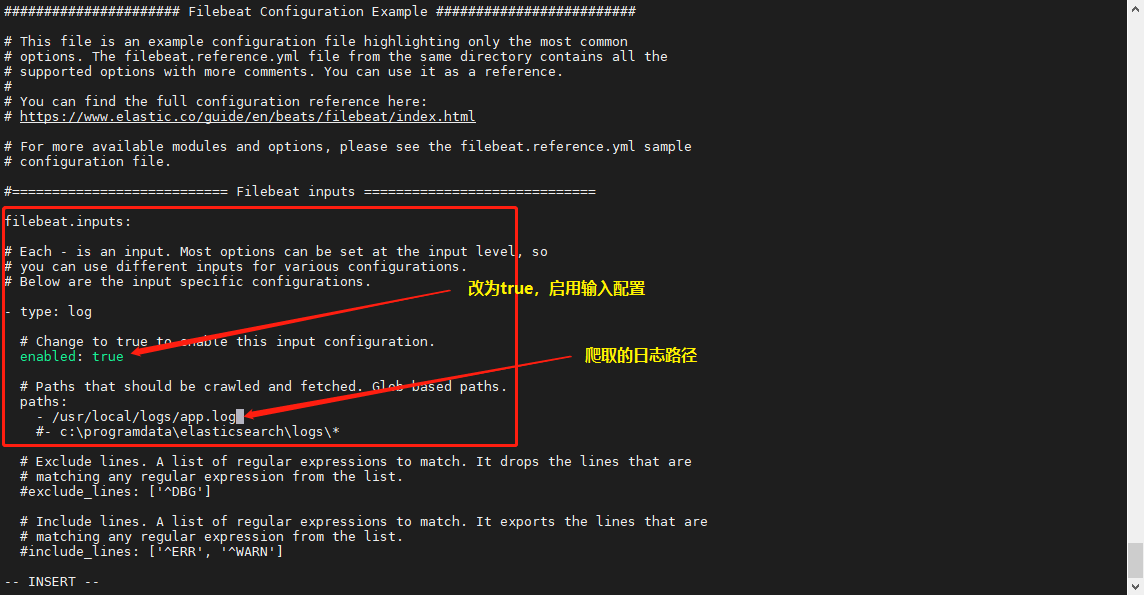
- 修改filebeat配置
filebeat安装目录下,修改filebeat.yml配置文件
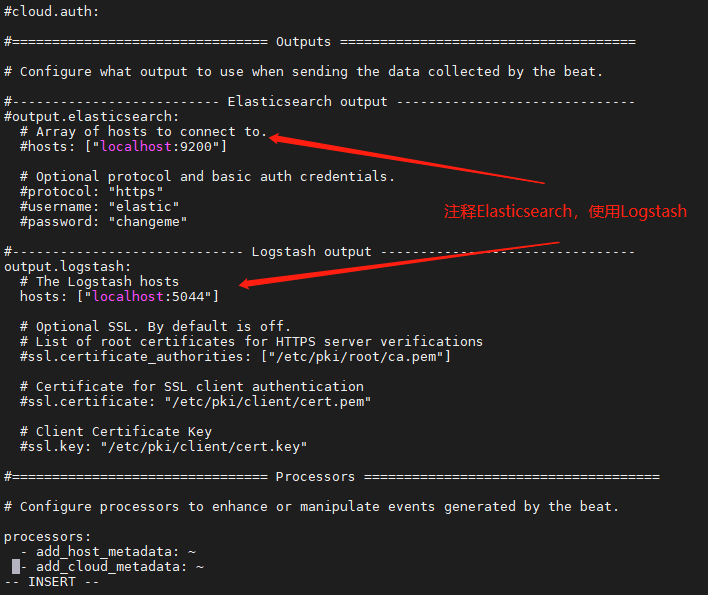
- 修改Logstash配置
配置内容如下:
input { |
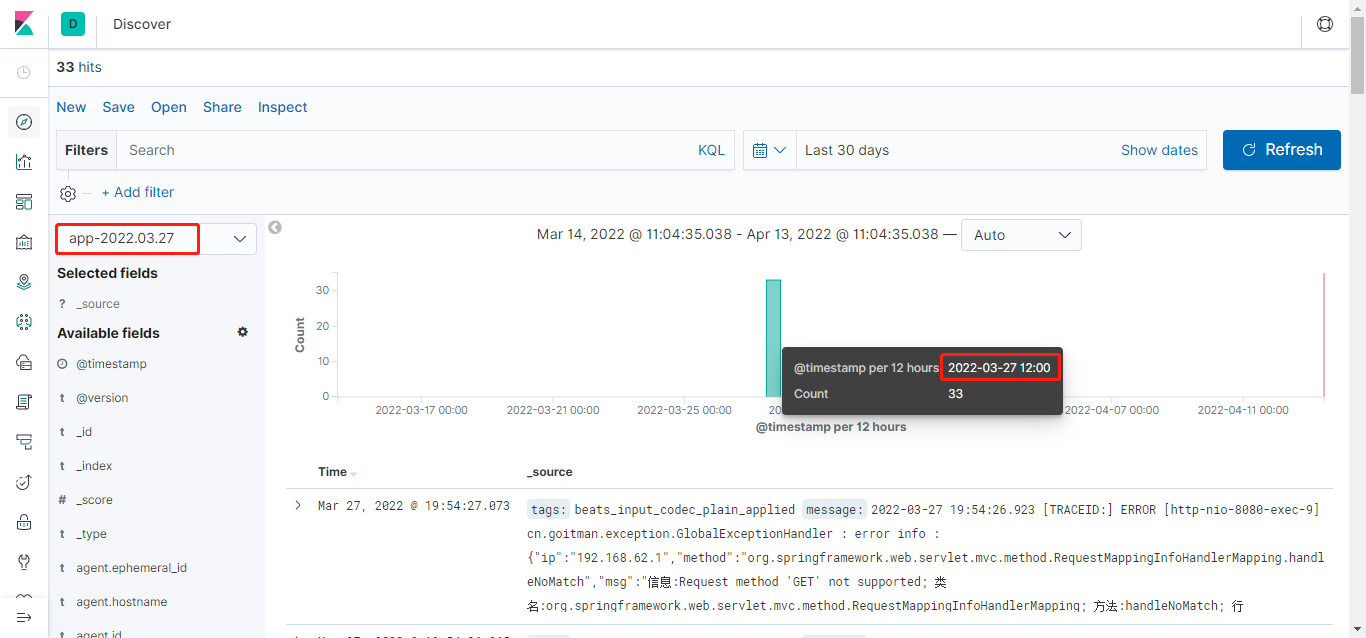
- 测试
ELK与项目启动后,关联Elasticsearch (Elasticsearch默认配置即可) 索引,查询结果如下
Nginx代理
ELK配置完之后,有些情况下外网无法连接Kibana,则需要使用Nginx代理到Kibana进行访问
- 安装nginx和http用户认证工具
yum -y install epel-release |
- 修改nginx配置
先备份nginx.conf文件,以防错改
cp /etc/nginx/nginx.conf /etc/nginx/nginx.conf.bak |
将location配置部分,注释掉
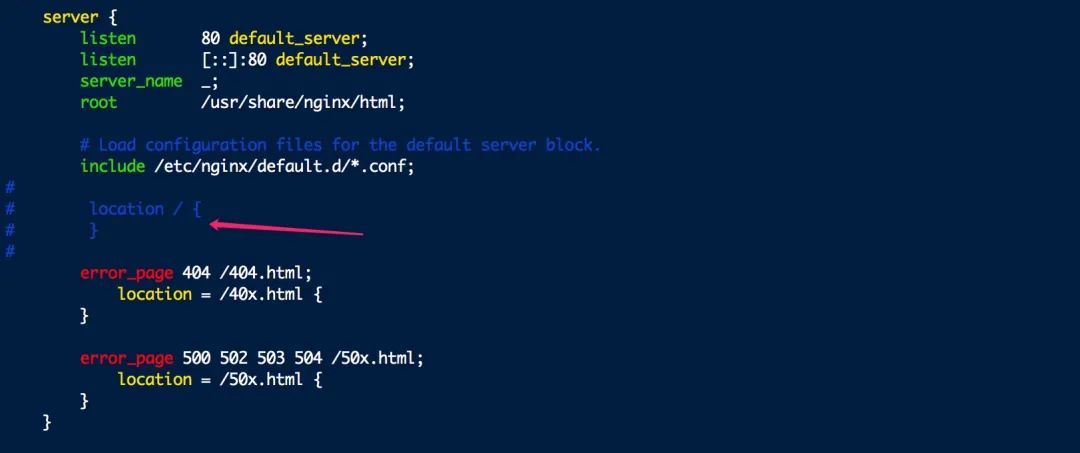
创建并编辑kibana.conf配置文件
mkdir /etc/nginx/conf.d/kibana.conf |
内容如下:
server { |
重新加载配置文件,并重启服务
systemctl reload nginx |
在浏览器输入http://nginx服务器ip:8000, 就可以访问了kibana
基础使用
Filebeat
配置多个日志路径
如需要获取多个日志文件路径(如tomcat、nginx等等),只需修改filebeat和logstash配置文件即可
- 修改filebeat配置文件
vi 路径/filebeat.yml |
模版内容如下:
filebeat.prospectors: |
- 修改logstash配置文件
以elastic.conf配置文件为例
vi 路径/elastic.conf |
模版内容如下:
input{ |
Logstash
input
input模块支持从多个源收集数据,以下列举几个常用配置
文件
input { |
缓存
Redis 模式
input { |
Kafka 模式
input { |
消息队列
Rabbitmq 模式
input { |
数据库
# MySQL数据库 |
filter
filter模块是非必须的,input接收到的数据如果需要类型转换、过滤判断、增减字段等操作就需要用到filter模块。如果input得到的数据不需要二次加工可以不使用filter,直接output到一个输出端。
合理的拆分字段和字段的数据类型转换是制作统计图表的基础,统计图表的制作直接依赖filter处理所产生的字段。
正则处理插件grok堪称Logstash中的神器组件,grok内置了丰富的预定义pattern,能够简单方便的匹配复杂的正则目标数据。
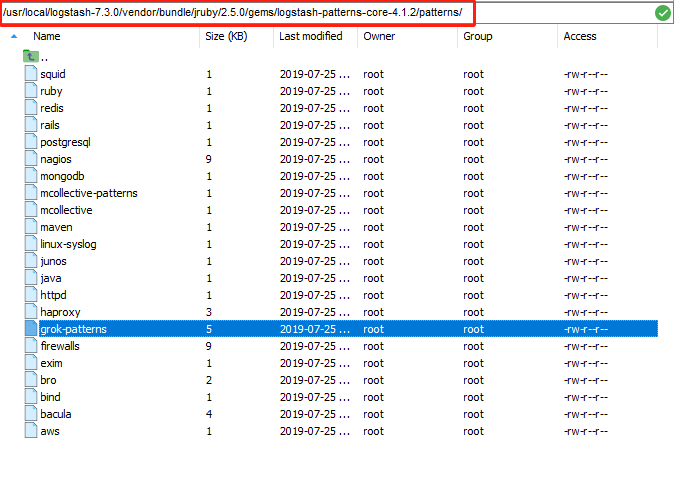
grok内置正则表达式文件路径:
/logstash安装路径\vendor\bundle\jruby\x.x\gems\logstash-patterns-core-x.x.x\patterns\grok-patterns
- 基本语法
用%{} 表示一组正则匹配规则,SYNTAX 是指grok里已经预定义好的正则表达式匹配别名,SEMANTIC 是指匹配之后准备输出的字段名称。
%{SYNTAX:SEMANTIC} |
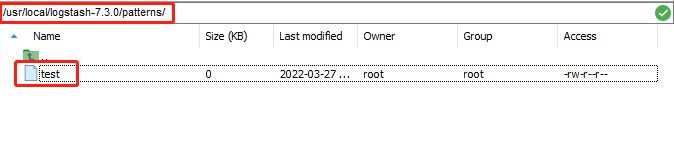
- 自定义
grok组件可以将多组复杂的pattern放到一个文件中,方便修改和管理,比如在/usr/local/logstash-7.3.0/patterns/目录下,创建一个为test(文件名随意)的文件。
以nginx日志为例:
23/May/2019:14:40:10 +0800,1558593610.753,1660,0.028,"0.028",647,200,10.16.172.20-"123.126.70.235",POST /330000/v6/feeds/detail/query HTTP/1.1,"app_key_vs=2.6.0&appid=330000&feed_count=10&feed_id=507297347911306752&flyer=1558593610700&idfa=A6719238-5AF6-4B57-B4B6-676B0905704D&log_user_id=248137098937342464&query_type=6&sig=28d2c189144c5380113afff158ea257d&since_time_comment=3000-01-01%2001%3A01%3A01.000&since_time_pure=3000-01-01%2001%3A01%3A01.000",UPS/"10.18.76.18:8080","sns/2.6.0 (com.sohu.sns; build:3; iOS 12.1.4) Alamofire/1.0",-,cs-ol.sns.sohu.com,"01374622096363527552","248137098937342464","872289029629325312@sohu.com","110501" |
nginx 配置的日志格式:
log_format nginx_nobody_log '$time_local,$msec,$request_length,$request_time,"$upstream_response_time",$body_bytes_sent,$status,$remote_addr-"$http_x_forwarded_for",$request,"$request_body",UPS/"$upstream_addr","$http_user_agent",$http_referer,$host,"$http_s_cid","$http_s_pid","$http_s_ppid","$http_p_appid"'; |
编辑test文件如下:
SNS_NGINX_ACCESS %{HTTPDATE:time_local},%{NUMBER:msec},%{INT:request_length},%{BASE16FLOAT:request_time},"(?:-|%{BASE16FLOAT:upstream_response_time})(,%{NUMBER:upstream_response_time2})?",%{INT:body_bytes_sent},%{INT:status},%{IPORHOST:remote_addr}-"%{DATA:http_x_forwarded_for}(, %{DATA:http_x_forwarded_for2})?",%{WORD:method} %{URIPATH:interface}(?:%{DATA:uri_param})? HTTP/%{NUMBER:http_version},"%{DATA:request_body}",UPS/"%{DATA:upstream_addr}(, %{DATA:upstream_addr2})?","%{DATA:http_user_agent}",%{DATA:http_referer},%{IPORHOST:host},"%{DATA:http_s_cid}","%{DATA:http_s_pid}","%{DATA:http_s_ppid}","%{DATA:http_p_appid}" |
引用pattern文件:
# SNS_NGINX_ACCESS 自定义的pattern别名 |
在线调试grok规则匹配地址
从Kibana 6.4.0版本开始,Dev Tools自带了grok调试功能
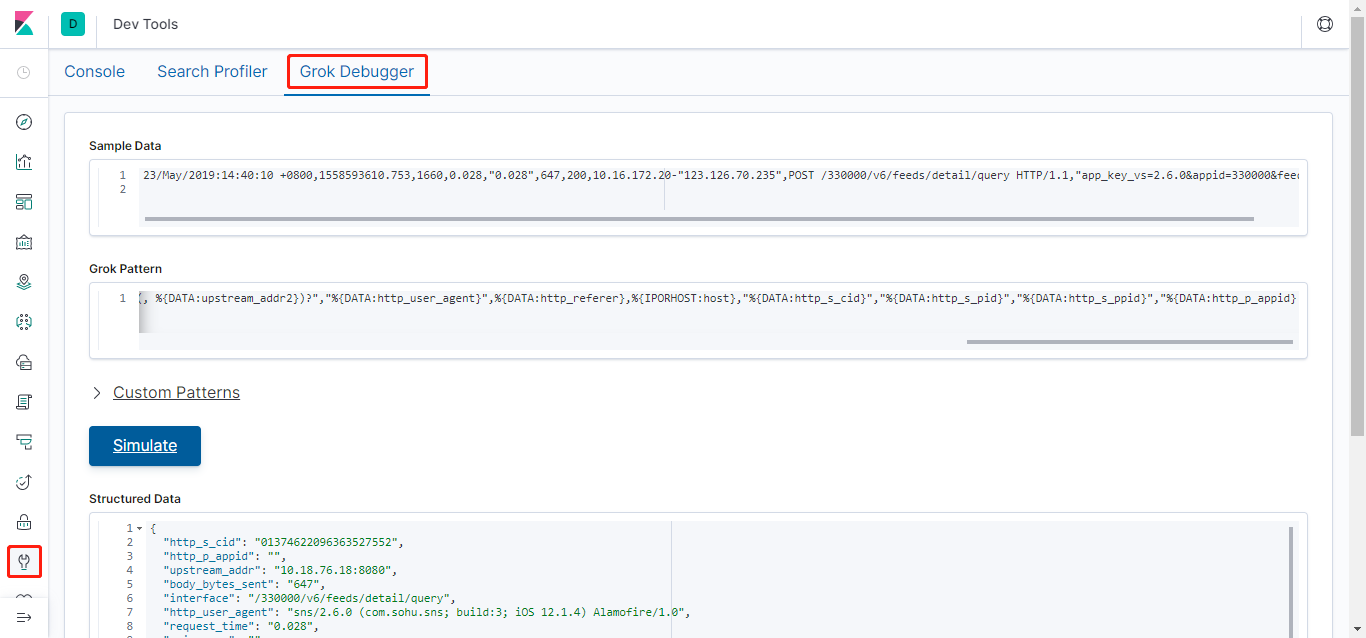
- 其他配置
filter { |
output
output内输出配置与input内输入配置大同小异,其他中间件配置在此不再累述
output { |
Elasticsearch
Elasticsearch提供了众多的api和丰富的功能;常用的API分为如下几类
- Document APIs :es的文档的CRUD操作相关API
- Search APIs:查询检索相关的API
- Indices APIs:索引管理相关API
- cat APIs:集群健康状态、索引信息、分片信息等等,输出的是在命令行界面下更友好的制表信息
- Cluster APIs:es集群查看和管理配置相关API
以下借助Kibana的Dev Tools工具来了解一下常用的API使用
获取es信息
- 查看es的基本信息(包括版本号、集群名称、lucene版本号等)
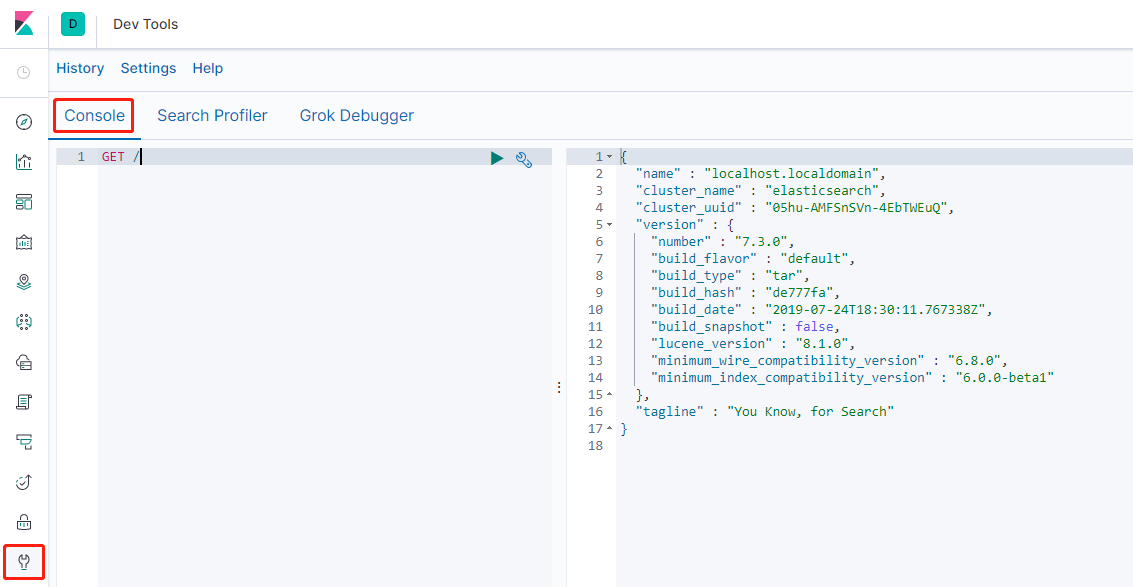
- 查看es对应index的aliases、mappings、settings信息
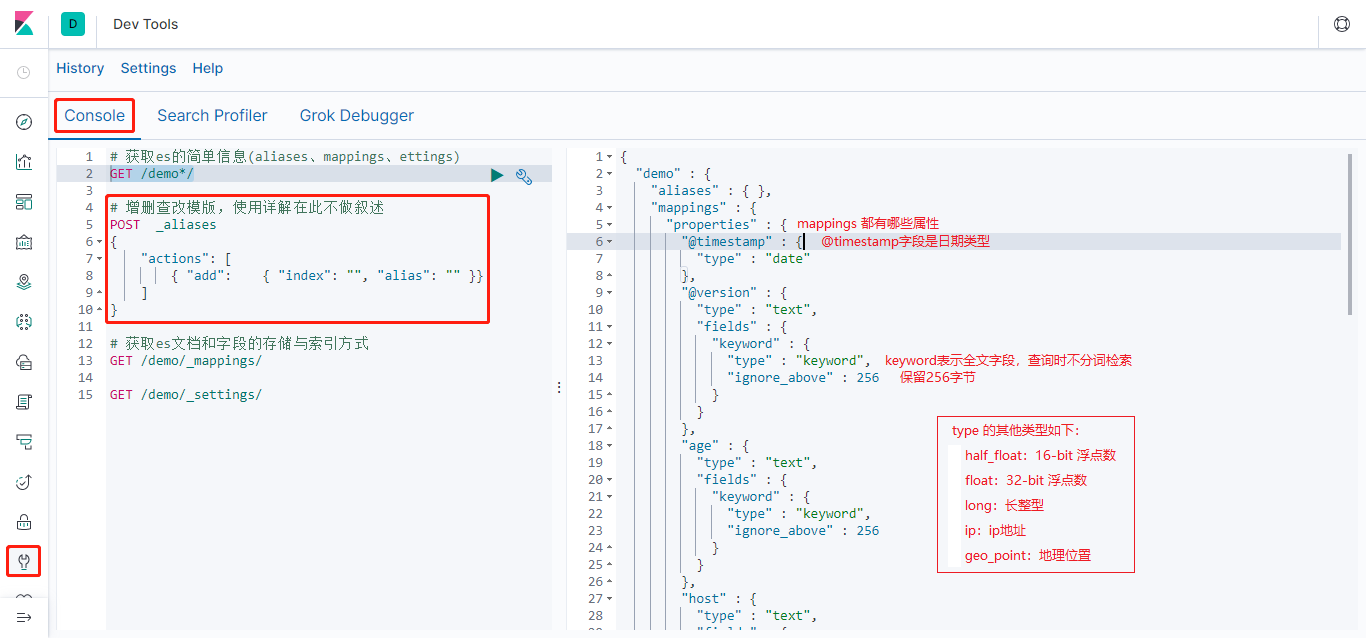
搜索(Search)
查询可以分别使用URI search和Request body两种查询方式
URI search查询方式,语法参考 search-uri-requestrequest body查询方式,语法参考 search-request-body
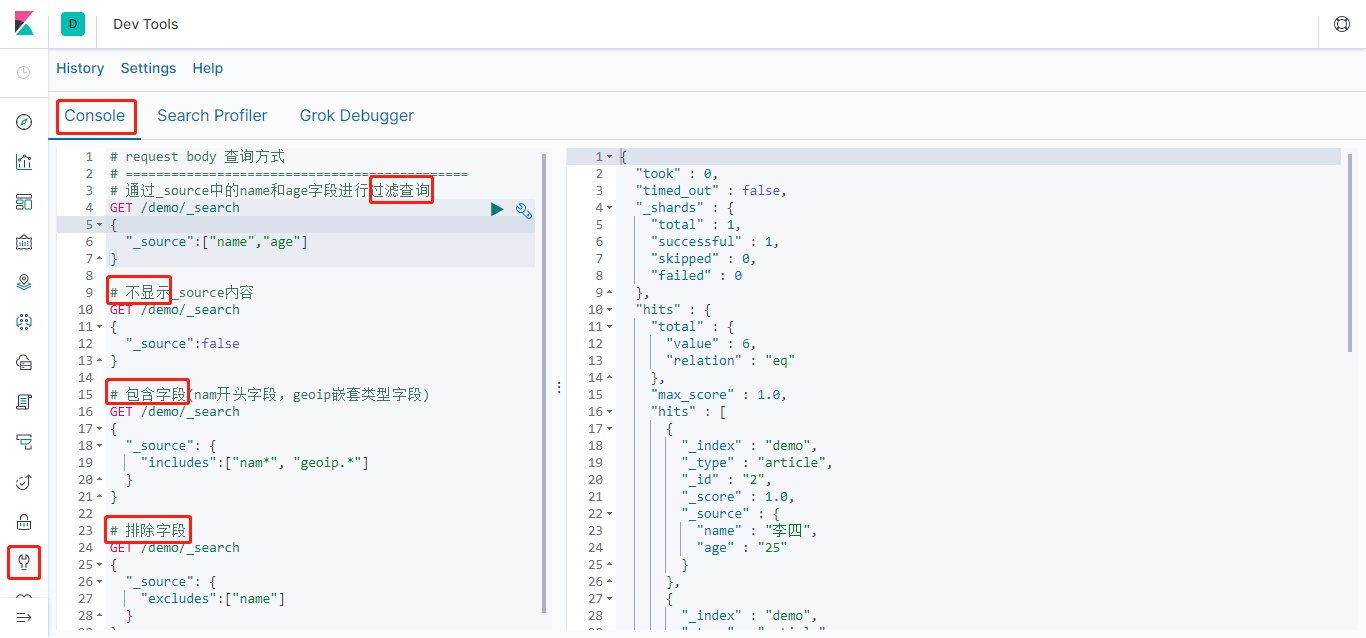
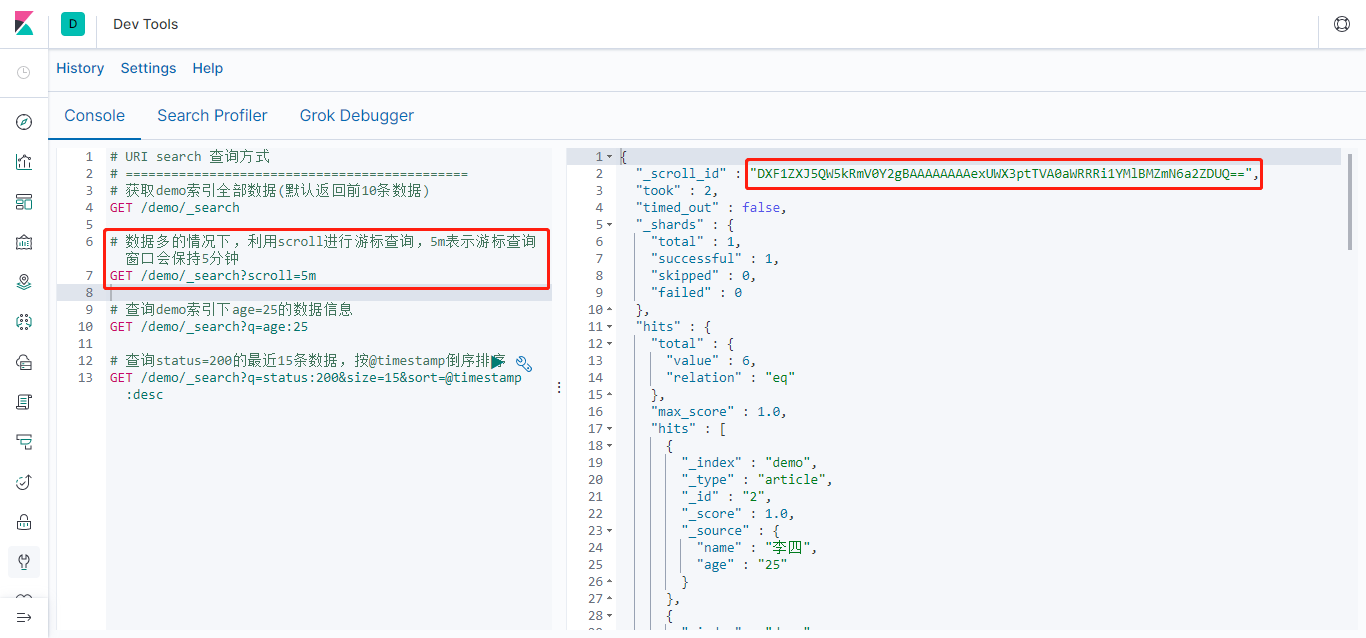
上图返回结果中有一个 _scroll_id 字段,要基于这个游标继续遍历数据只需要像下面这样,调用 /_search/scroll接口,将前面返回结果的_scroll_id作为scroll_id参数值;scroll:5m表示将当前的scroll_id查询窗口再次延长5分钟。
GET /_search/scroll |
游标超过时间窗口会自动清理,也可以通过 DELETE /_search/scroll 来清理一个游标
DELETE /_search/scroll |
统计(Count)
统计数量可使用 Count;下右图count表示查询命中的数量
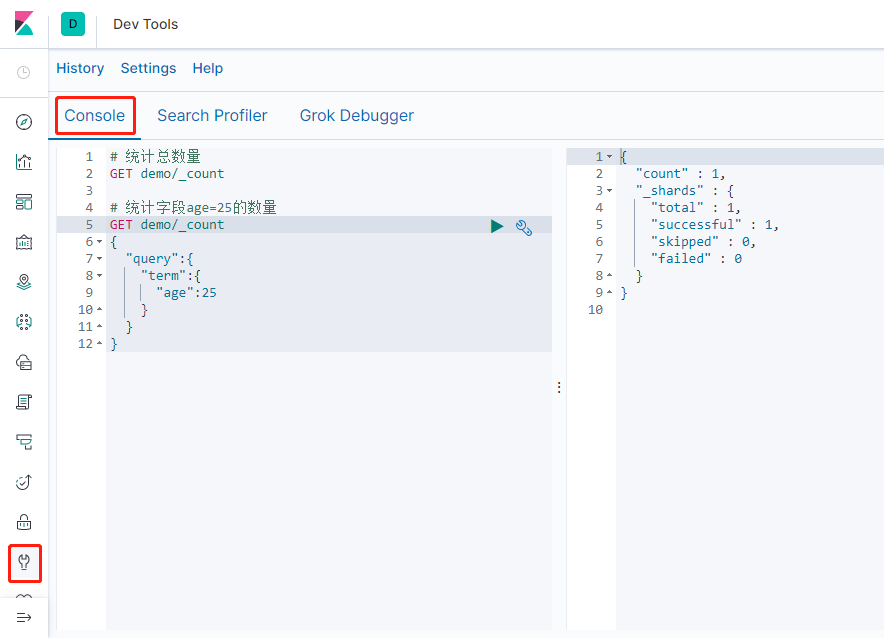
query部分es提供了Query DSL查询语法,语法参考 query-dsl
聚合(Aggregation)
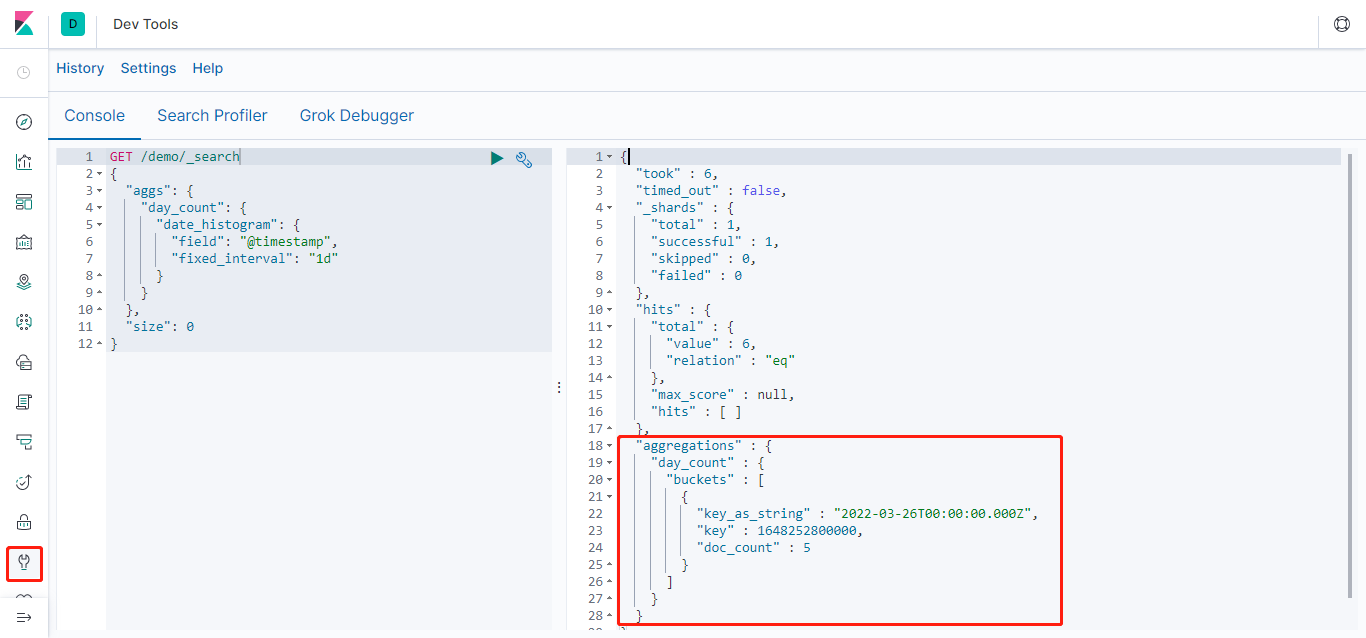
统计某索引每天(每小时)的数量、按照某个字段计数等,类似的查询就要用到aggregation聚合查询
- 查询每天请求数量
aggs:表示聚合查询;day_count:自定义的一个聚合的名称(aggs可以有多个和多层,所以需要指定一个名称);date_histogram:表示是一个日期分布器,是按照"@timestamp"这个日期字段按照1d(1天)的时间间隔进行分布的;size:0:表示不返回具体的记录,hits部分是空数组
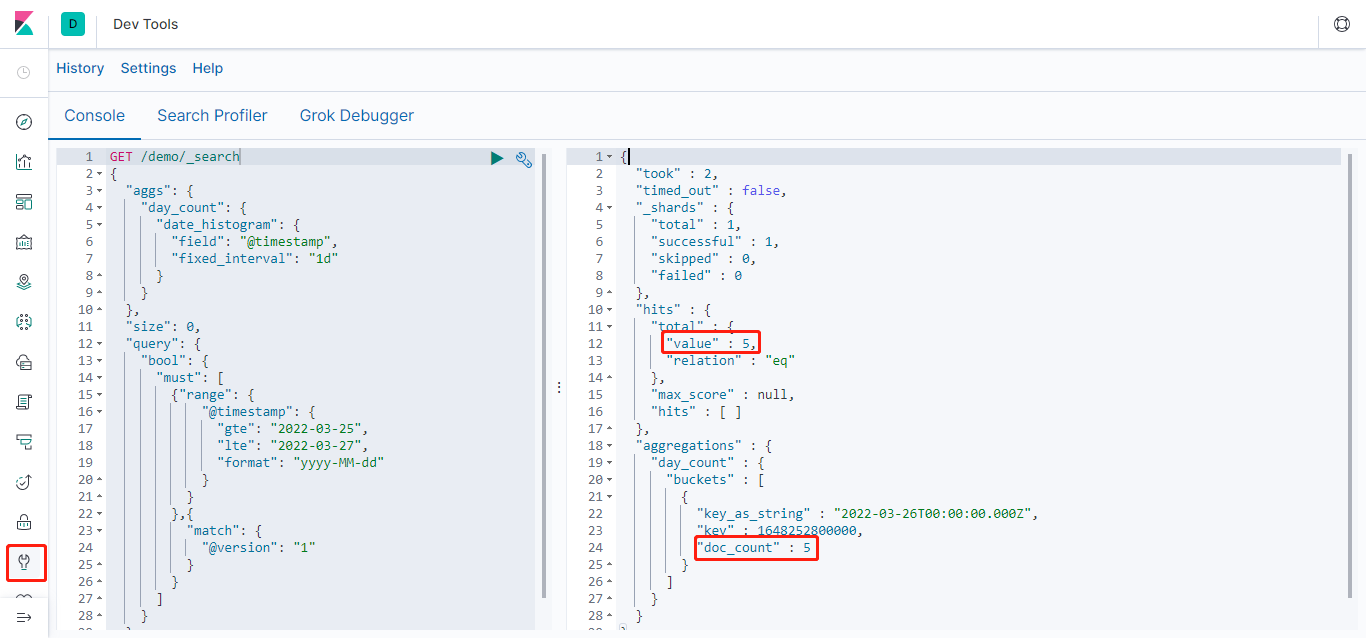
- 查询日期范围
查询的日期范围,并且只查询@version=1的数量,可以在查询增加query部分,如下
- 查询一天内接口调用次数
使用terms进行聚合,将aggs部分修改成如下,interface.keyword 就是接口路径(这里的interface.keyword是经过grok插件过滤后的字段),size:5 表示只展示前面5个(默认是按照doc_count倒序排序)
{ |

- 查询一天内每小时接口调用次数
"aggs": { |

Kibana
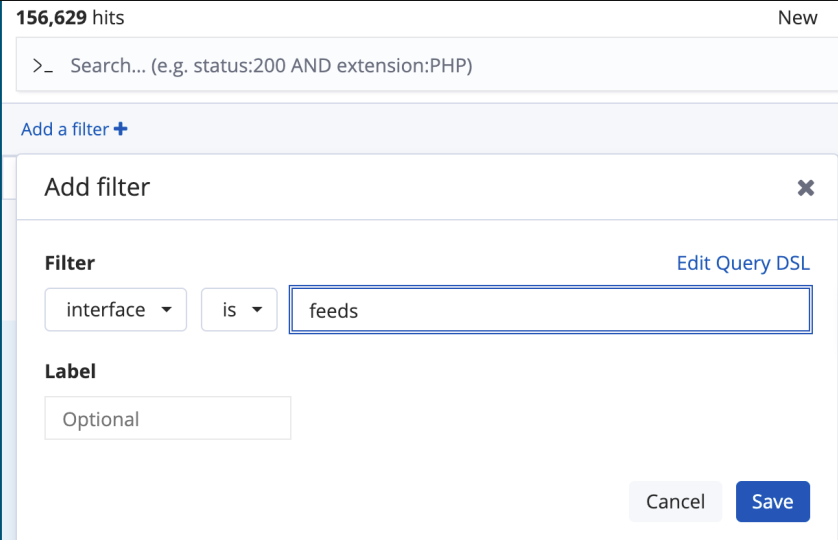
通过grok匹配存储在Elasticsearch中的字段,都是可以使用Kibana的 Discover菜单的中 “Add a filter” 进行查询
基础查询
两种过滤方式
"字段名":可以进行分词查询,如下图中interface字段存储的是/330003/v7/feeds/profile/template的内容,那么每一个"/"之间的字符串都可以单独查询,因为"/"是一个默认的分词符号"字段名.keyword":使用interface整体进行查询不支持分词,使用时Kibana时也会弹出下拉列表。
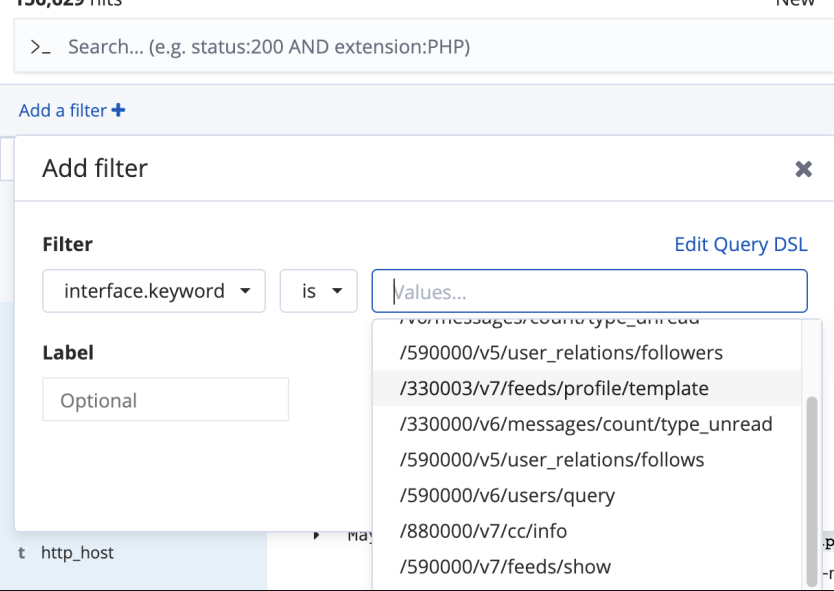
单字段多词查询
查询一个字段的多个值可以使用“is one of”或者 “is not one of” ,用来表示要查询的分词在其中或者不在其中:
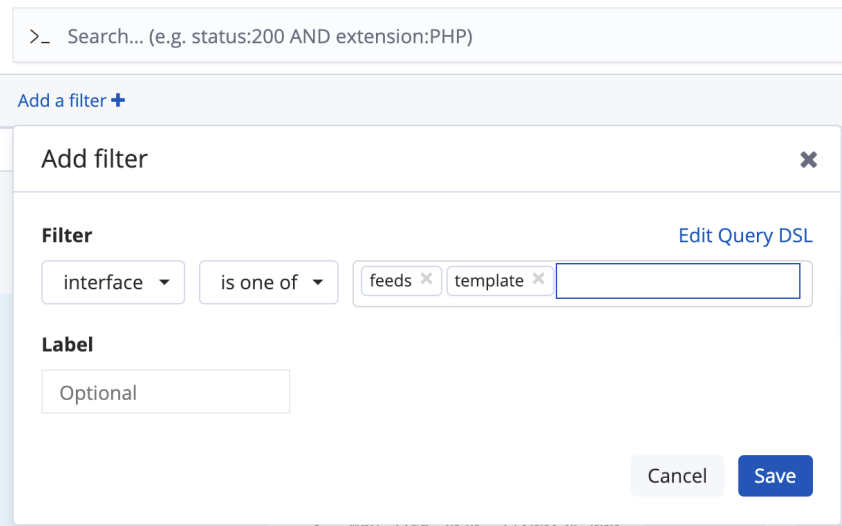
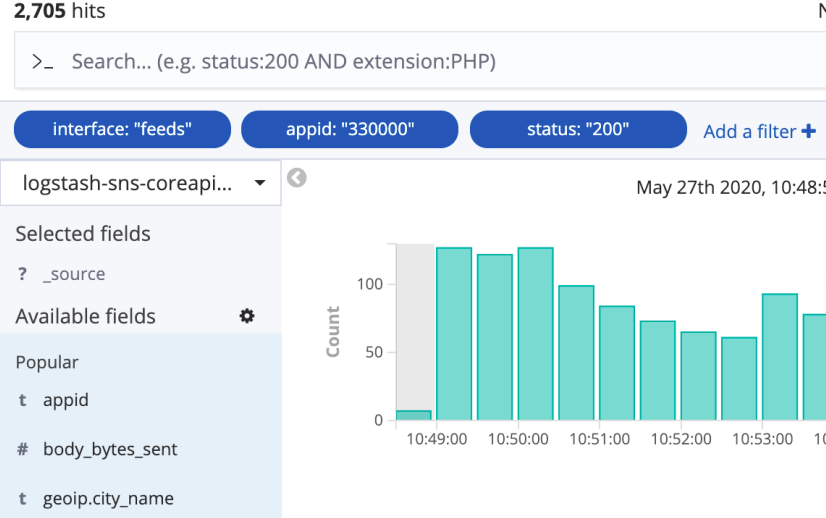
多过滤条件查询
进行多个字段查询之间的关系是 and 关系,如下 查询的是“interface包含feeds关键字的并且 appid=330000 并且 status是200的 ”
高级查询
全文搜索
直接搜索框输入查询内容:content 或 "${content}",如果不写引号,那么搜索内容将按照分词处理,不区分内容顺序
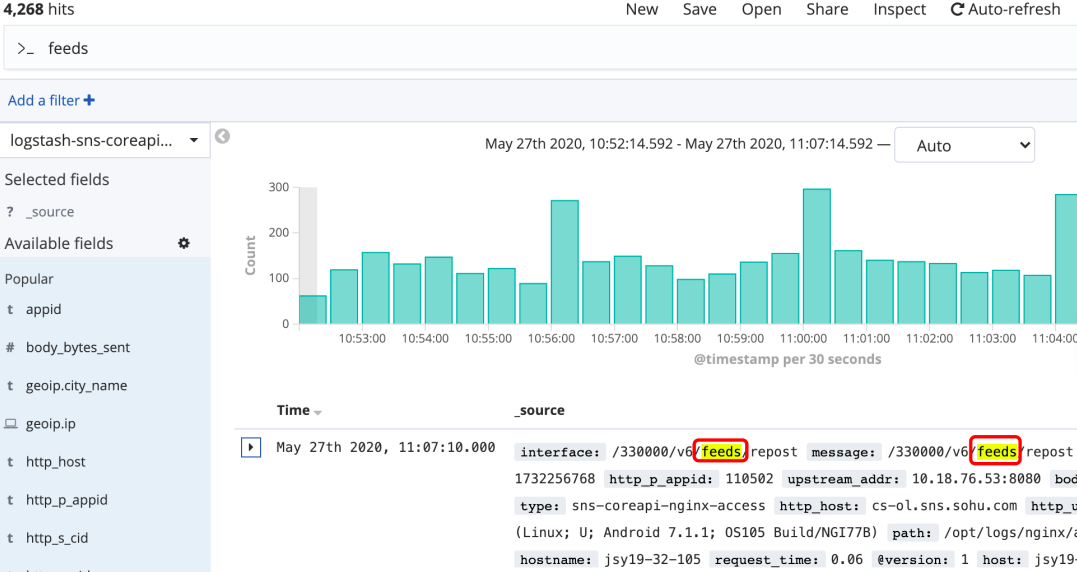
字段搜索
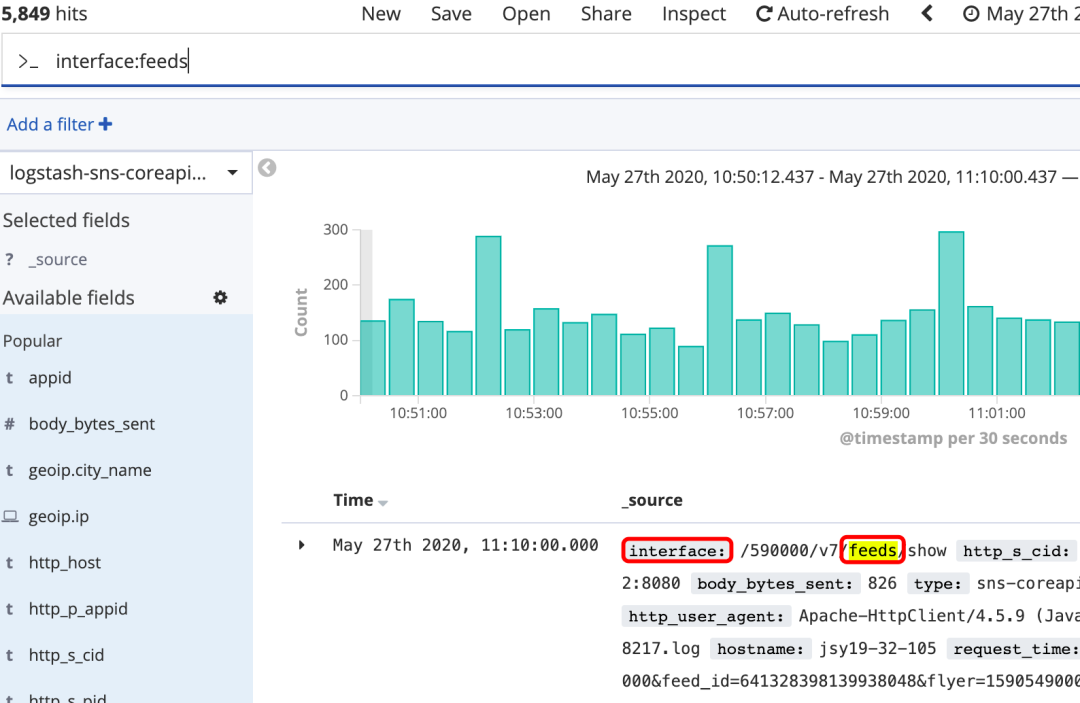
通配符
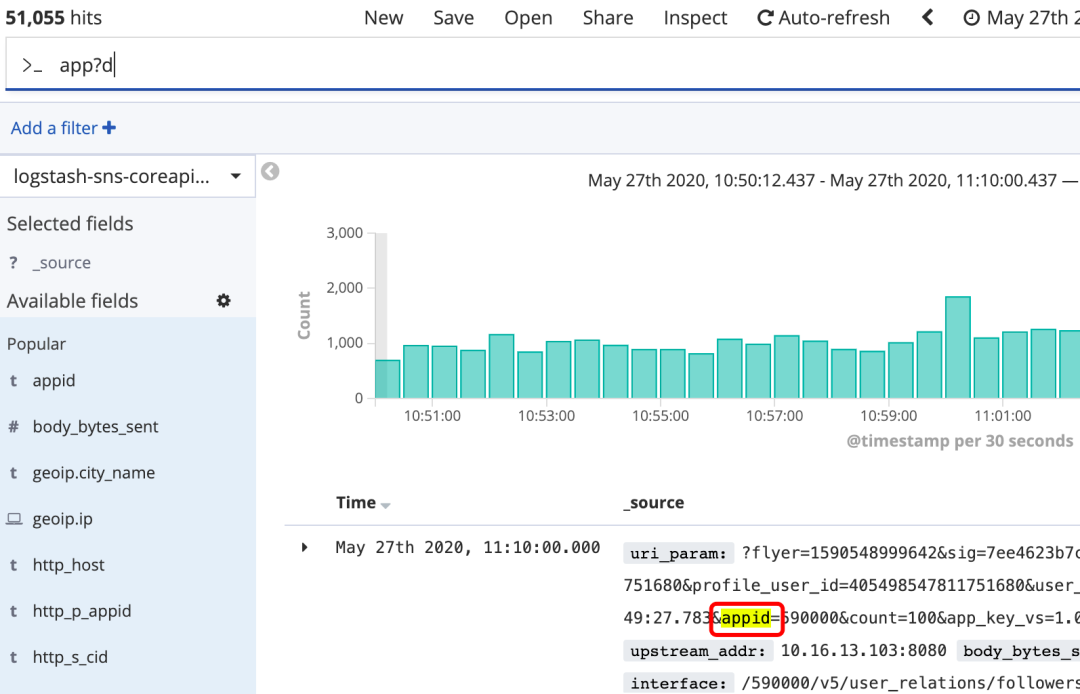
?:匹配单个字符,如app?d*:匹配0到多个字符,如searc*h
通配符不能做为第一个字符,如*test,?test
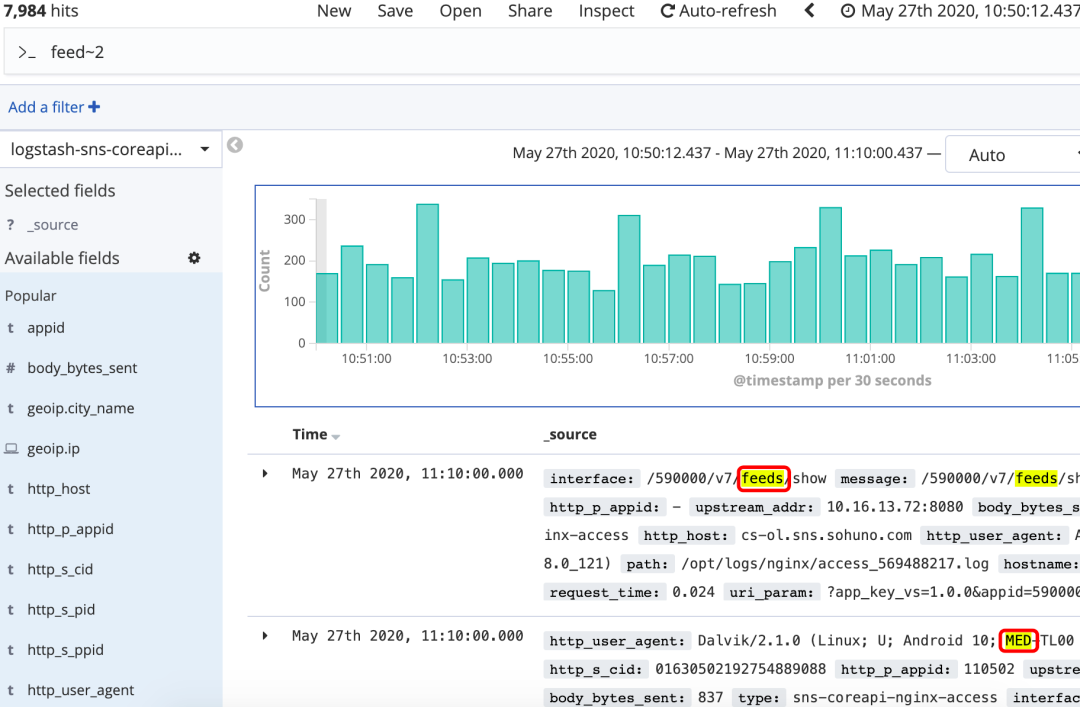
模糊搜索
~:在单词后面加上~启用模糊搜索,可搜到近似单词;还可指定相似度cromm~1(默认2),越大值越接近搜索的原始值
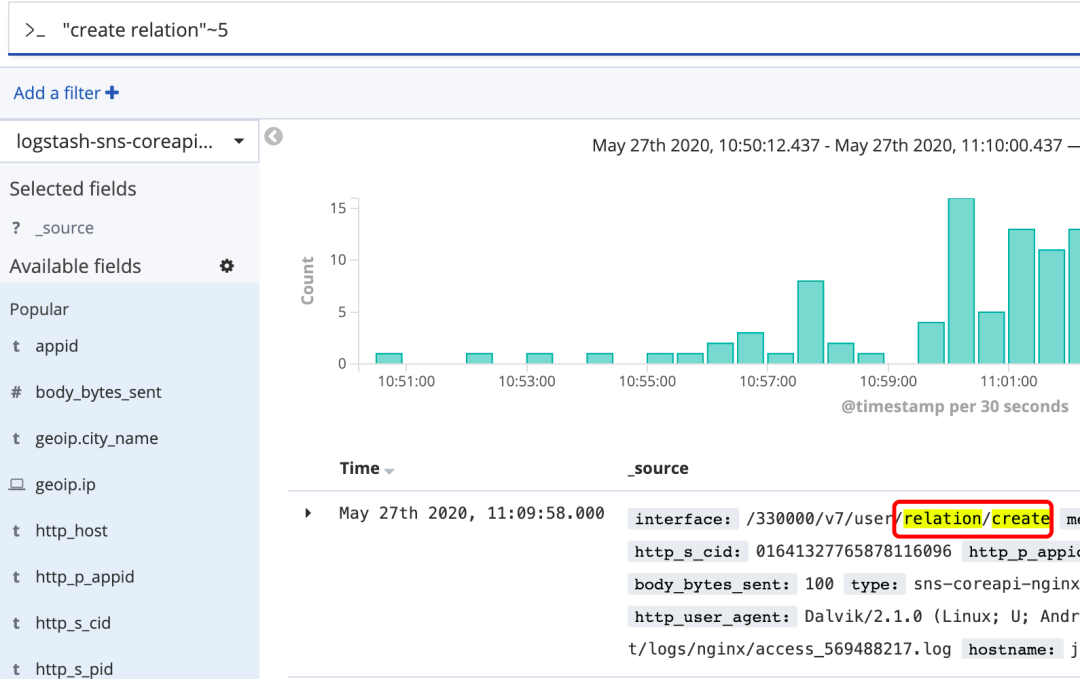
近似搜索
在短语后加上~,可以搜到被隔开或顺序不同的单词
逻辑操作
逻辑符 +、-
- +:搜索结果中必须包含此项
- -:不能含有此项,如
+appid -s-ppid aaa bbb ccc结果中必须存在appid,不能有s-ppid,剩余部分尽量都匹配到
逻辑符 AND、OR
((quick AND fox) OR (brown AND fox) OR fox) AND NOT news
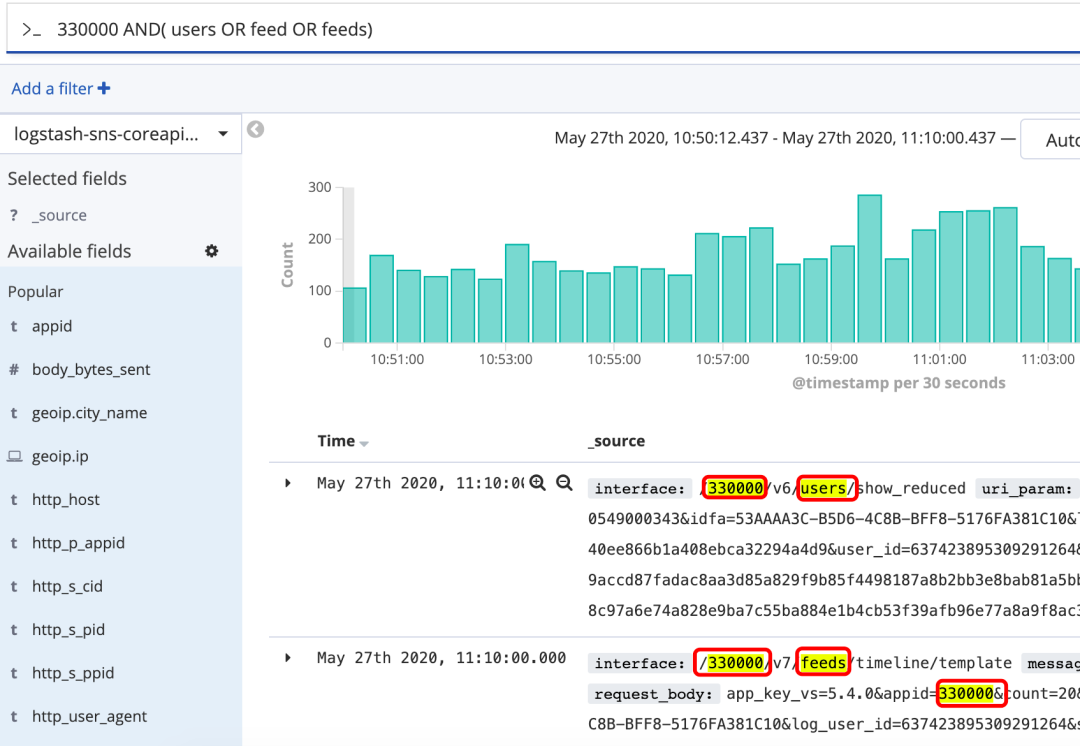
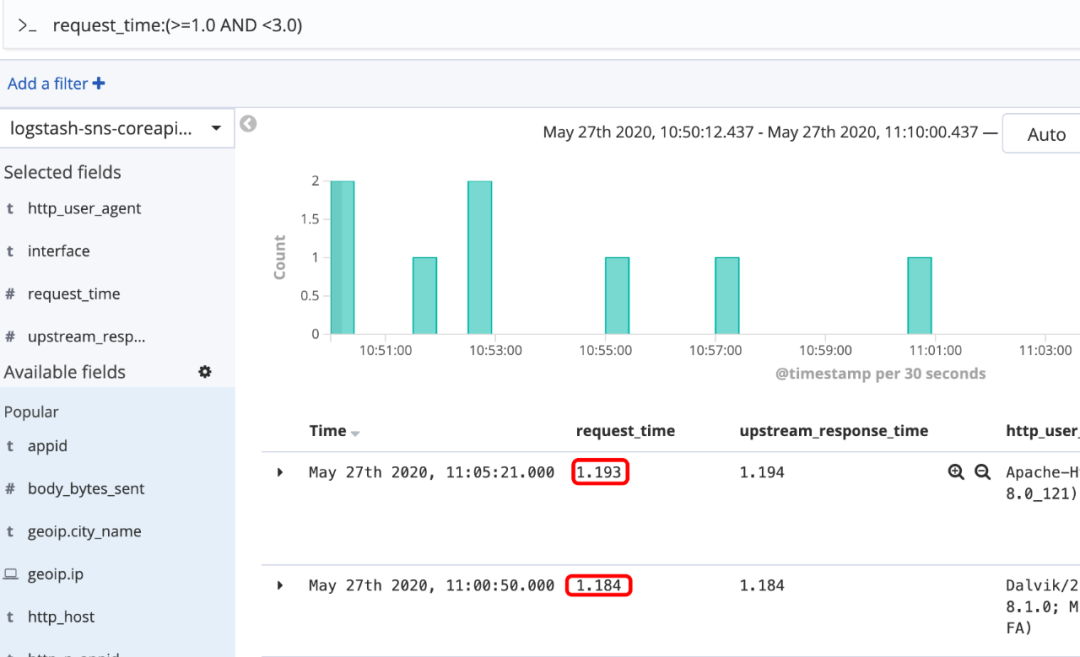
范围搜索
有如下写法:
- [1,5},含1但不含5
- age:>10
- age:<=10
- age:(>=10 AND <20)
- age:(+>=10 +<20)
转义特殊字符
以下字符搜索时需用\转义
+ - = && || > < ! ( ) { } [ ] ^ " ~ * ? : \ / |
数据统计
若想清楚某个接口最近1小时都有哪些用户和都来自哪些城市。这里就用到了Kibana Visualize。
选择 Data Table 数据表视图,它可以下载成csv格式的文件。
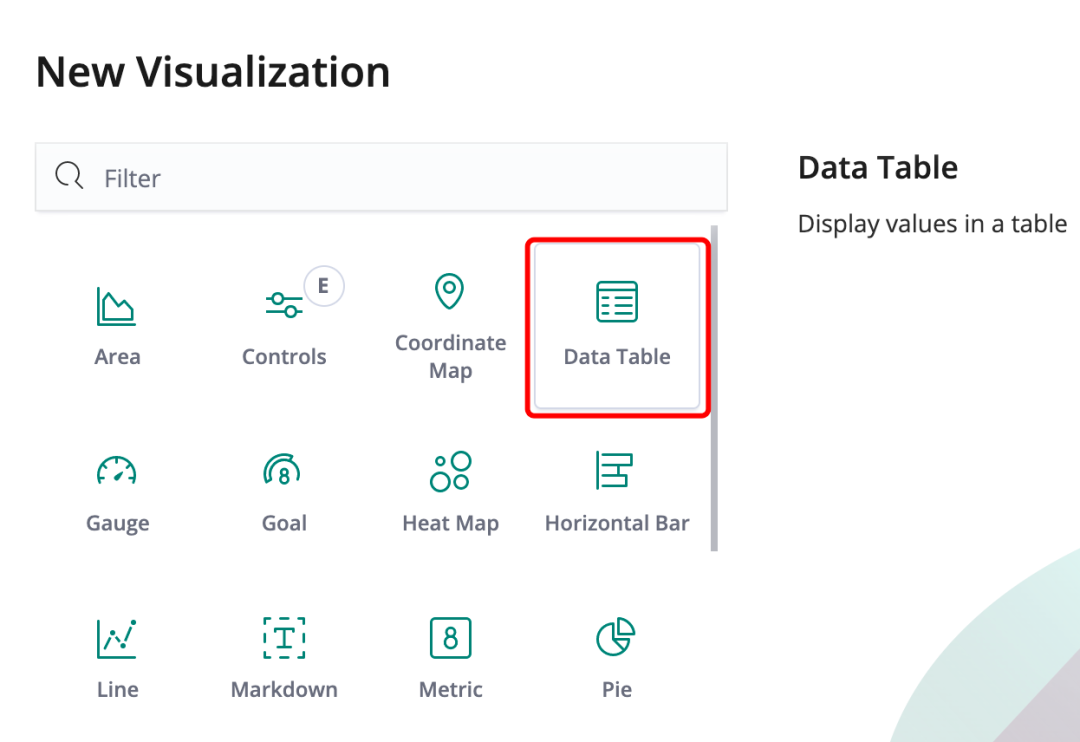
选择想要查询的索引
趋势图表和数据表都分为Metrics和Buckets两部分:
- Metrics:对Buckets里面的值做什么统计操作
- Buckets:对值的设置
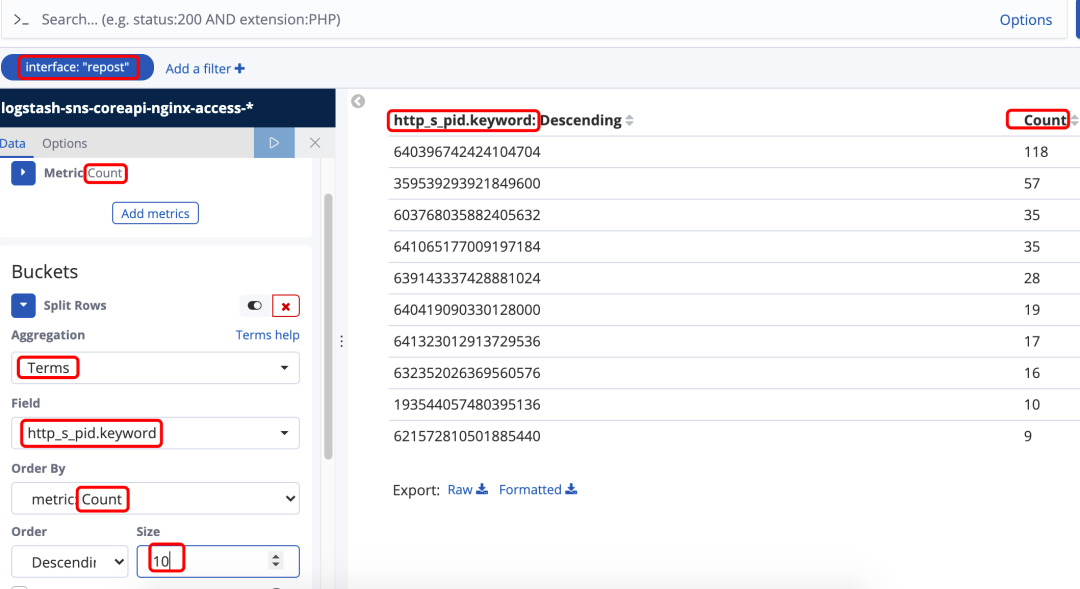
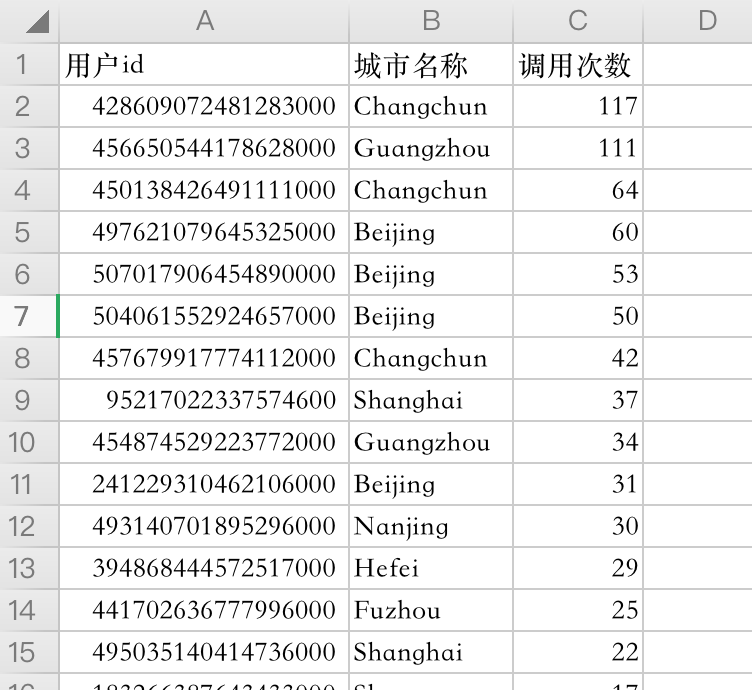
下图的DataTable为查询接口包含"repost"字段,最近15分钟内 前10个调用最多的用户id。
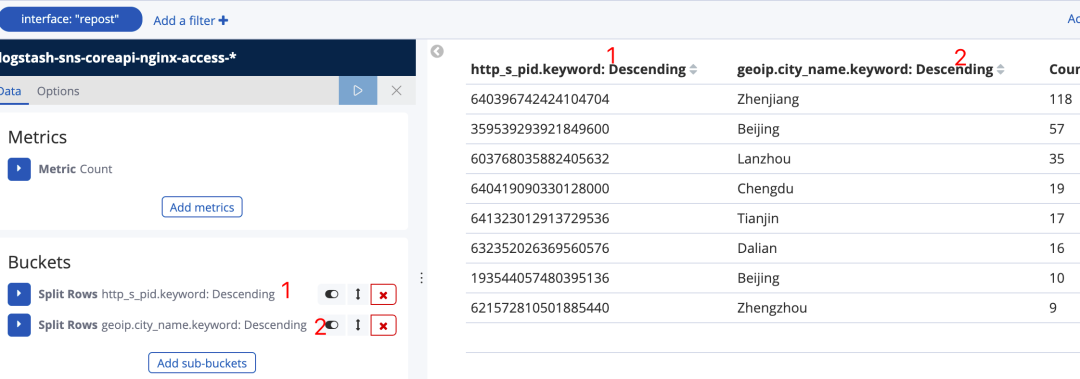
在Bucket上增加http_s_pid.keyword和geoip.city_name, 数据表 2 列是在 1 列的前提下查询出来的城市名称
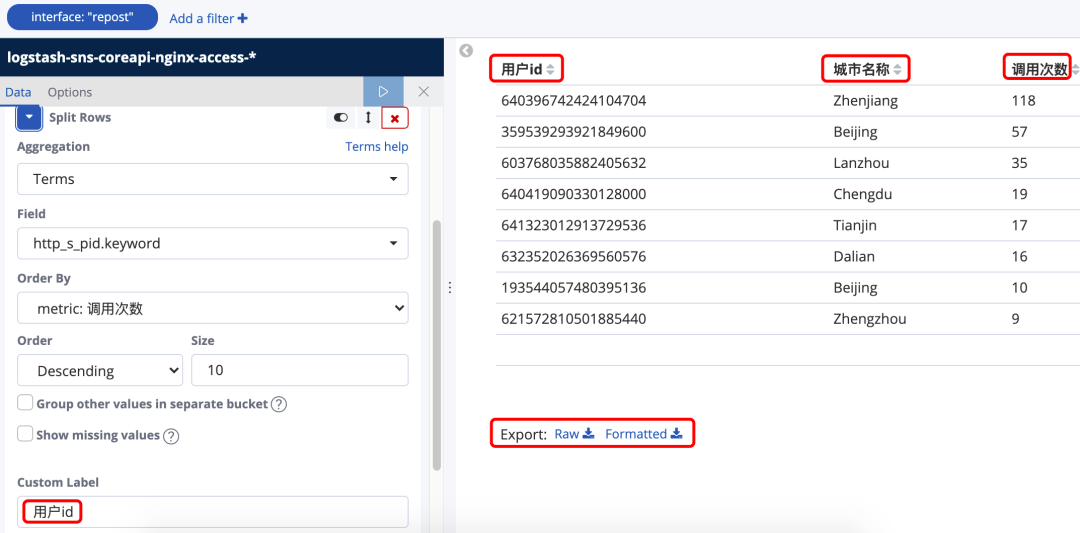
给每个metric和bucket起别名,然后点击Raw或者Formatted将查询到的数据下载成csv文件
趋势图绘制
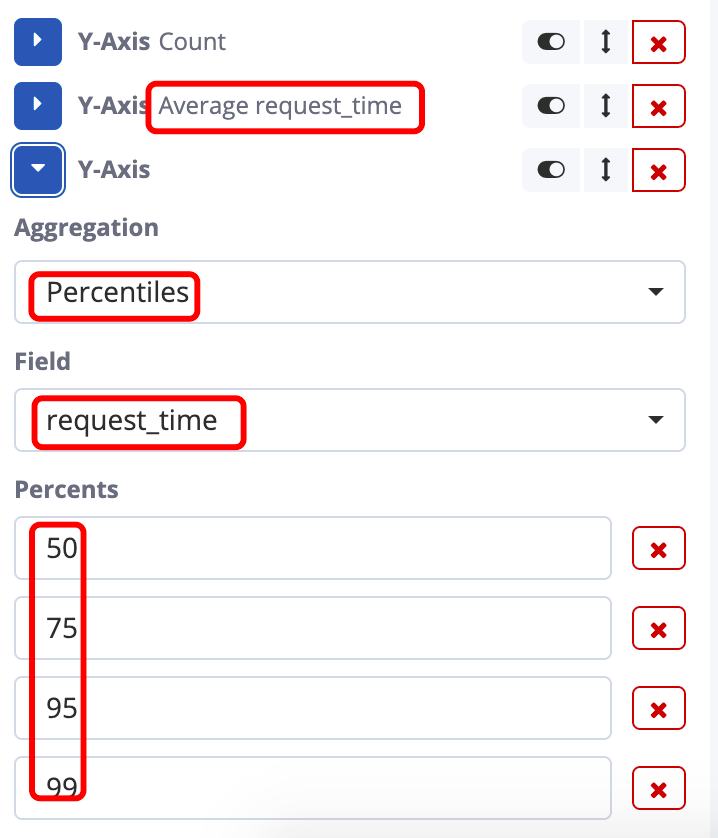
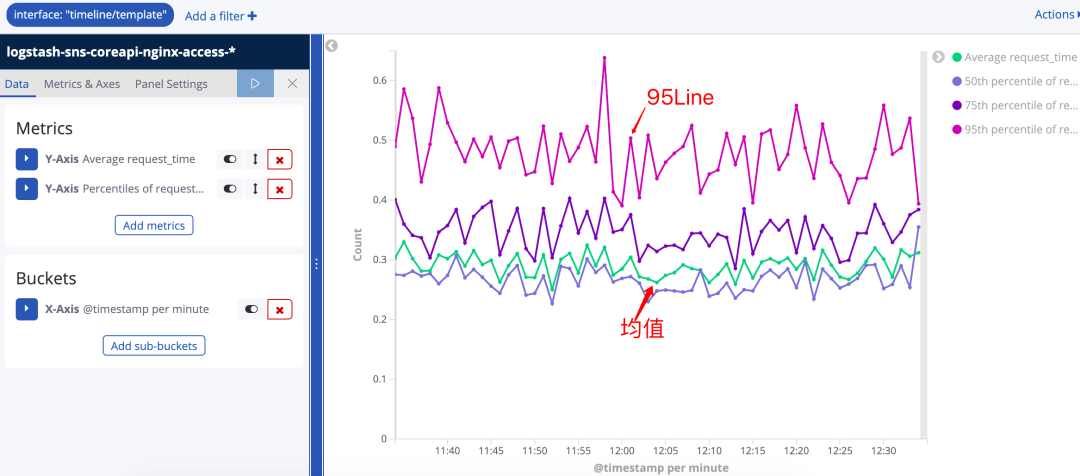
比如想要了解某些接口平均响应时间和50%,75%,95%的响应时间走向。就可以使用Line视图
想要进行均值,最大,最小,百分比分布等这些统计,必须得有
Number类型的字段,如果前期logstash没有进行合适的数据类型转换,就需要在Kibana对应索引下的Script Field来实现基于某个字段的类型转换(Script Field中需要编写Script语句,在此不做详解)
统计最近1小时包含timeline/template的接口调用数量折线图。想要统计响应时间,就要先修改Metric的统计方式。
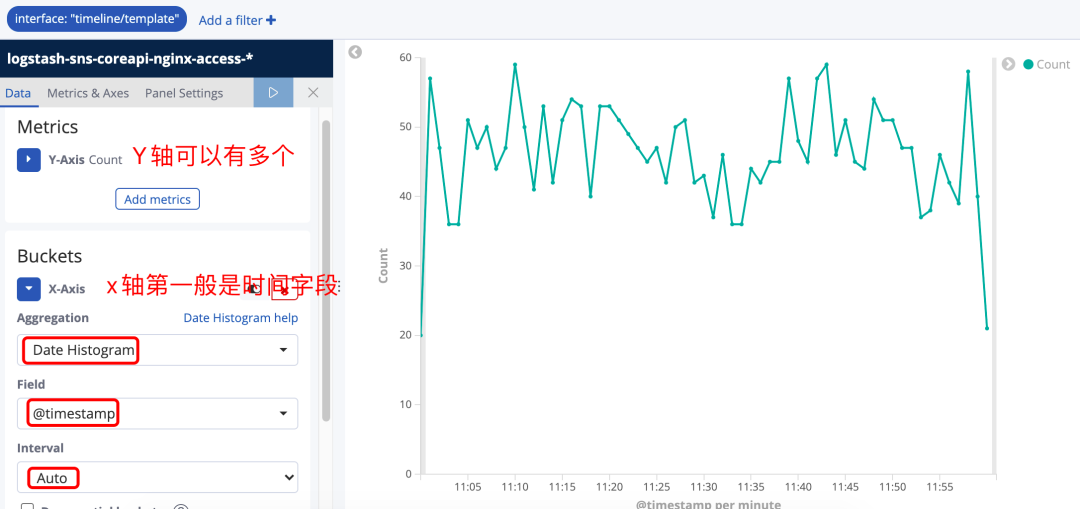
增加两个Y-Axis的metric,分别是对 request_time 求均值和对 request_time 求百分比分布