概述
什么是Redis
Redis是用C语言开发的一个开源的高性能键值对(key-value)非关系性数据库,官方提供测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s,且Redis通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止Redis支持的键值数据类型如下:
- 字符串类型 string
- 散列类型 hash
- 列表类型 list
- 集合类型 set
- 有序集合类型 sortedset
应用场景
- 缓存
数据查询、短连接、新闻内容、商品内容、对象缓存、全页缓存热点数据等等 - 聊天室的在线好友列表
- 任务队列
秒杀、抢购、12306等等 - 限流
int类型,incr方法;以访问者的ip和其他信息作为key,访问一次增加一次计数,超过次数则返回false - 购物车
String 或hash。所有String可以做的hash都可以做 - 商品标签
- 商品筛选
- 用户关注、推荐模型
- 应用排行榜
- 网站访问统计
- 计数器
int类型,incr方法,例如:文章的阅读量、微博点赞数、允许一定的延迟,先写入Redis再定时同步到数据库 - 位统计
String类型的bitcount(1.6.6的bitmap数据结构),字符是以8位二进制存储的
set k1 a |
例如:在线用户统计,留存用户统计
setbit onlineusers 01 |
支持按位与、按位或等等操作
BITOPANDdestkeykey[key...] ,对一个或多个 key 求逻辑并,并将结果保存到 destkey 。 |
计算出7天都在线的用户
BITOP "AND" "7_days_both_online_users" "day_1_online_users" "day_2_online_users" ... "day_7_online_users" |
- 全局ID
int类型,incrby,利用原子性,分库分表的场景,一次性拿一段。 - 数据过期处理(可以精确到毫秒)
- 分布式集群架构中的session分离
- 分布式锁
String类型setnx方法,只有不存在时才能添加成功,返回true
public static boolean getLock(String key) { |
抽奖
自带一个随机获得值:spop myset点赞、签到、打卡
假如ID是t1001,用户ID是u3001,用 like:t1001 来维护 t1001 这条微博的所有点赞用户
点赞了这条微博:sadd like:t1001 u3001
取消点赞:srem like:t1001 u3001
是否点赞:sismember like:t1001 u3001
点赞的所有用户:smembers like:t1001
点赞数:scard like:t1001
总结,只要希望查询快就可以使用redis,但是mysql中的数据如果频繁的更新,就不建议使用redis了,否则redis会频繁的从mysql不断更新数据,会导致redis慢了。redis适合存储经常查询又不经常更新的数据。
环境搭建
Window
从GitHub上下载window版的Redis(本文Window环境使用Redis-x64-3.2.100版本),下载地址:
Redis 单机
安装
window版的安装及其简单,解压Redis压缩包即可
目录结构
解压Redis压缩包后,见到如下目录机构: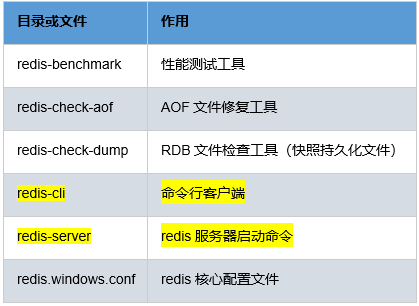
启动与关闭
双击Redis目录中redis-server.exe可以启动redis服务,Redis服务占用的端口是6379
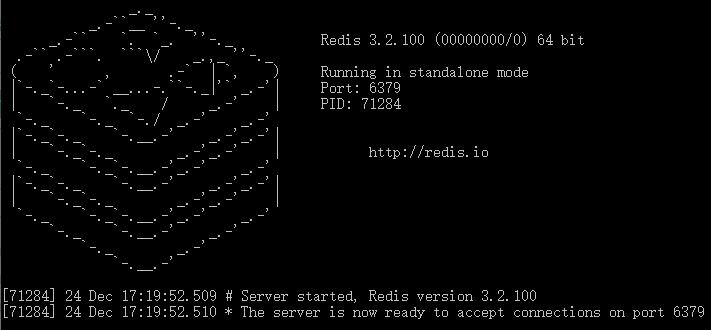
关闭Redis的控制台窗口就可以关闭Redis服务
redis客户端
双击Redis目录中redis-cli.exe,启动redis客户端

注:redis所在的硬盘位置的盘符,硬盘空间必须有20G以上。redis解压到非中文目录里面,目录结构不要太深
Redis 集群
redis-trib.rb是采用Ruby实现的Redis集群管理工具。内部通过Cluster(集群)相关命令帮我们简化集群创建、检查、槽迁移和均衡等常见运维操作,使用之前需要安装 Ruby 依赖环境。
注:redis-trib.rb没有实现哨兵机制,需另配置
环境准备
使用redis-trib.rb工具创建Redis集群,由于该文件是用ruby语言写的,所以需要安装Ruby开发环境,以及驱动redis-xxxx.gem,所以除了Redis安装文件外,还需要下载如上所述三个文件:
- redis-trib.rb文件,下载地址:(
Redis-x64-3.2.100 解压目录中已有redis-trib.rb文件,无需下载,3.0以上版本应该都有)
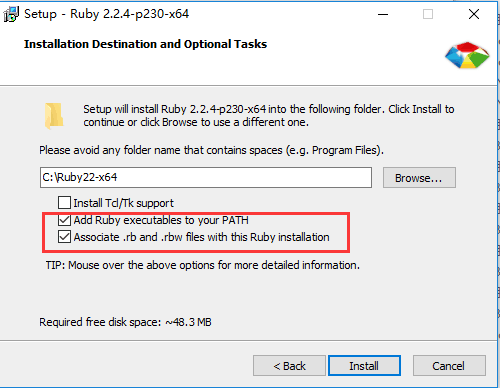
- 安装ruby开发环境(本文使用
rubyinstaller-2.2.4-x64.exe安装版),下载地址:
双击rubyinstaller-2.2.4-x64.exe,选中如图两个选项(意义为将ruby添加到系统环境变量中,在cmd命令中能直接使用ruby命令),之后就是傻瓜式安装啦
- 安装驱动redis-xxxx.gem(本文使用
3.2.2版本),下载地址:
将驱动redis-xxxx.gem拷贝到Ruby安装根目录下,在此目录执行cmd命令安装
gem install --local path_to_gem/filename.gem |
准备6个实例
配置文件
在Redis安装根目录下,创建编码格式为utf-8的配置文件:redis.6380.conf、redis.6381.conf、redis.6382.conf、redis.6383.conf、redis.6384.conf、redis.6385.conf。(Redis默认端口为6379,这里使用6380-6385六个端口)
# 以redis.6380.conf |
属性解析:
- 其他配置文件
只需将port、logfile、appendfilename、cluster-config-file中的6380修改为相应的端口号即可- loglevel:日志的记录级别,
notice是适合生产环境的- logfile:指定log的保存路径(默认是创建在Redis安装目录下),此处手动创建Logs目录
- appendonly:
持久化模式为aof格式- appendfilename:持久化文件
- cluster-config-file:节点配置文件
- cluster-enabled:
是否开启集群
安装redis服务
使用完整路径,避免集群出现问题
E:/Redis-Cluster/Redis-x64-3.2.100/redis-server.exe --service-install E:/Redis-Cluster/Redis-x64-3.2.100/redis.6380.conf --service-name redis6380 |
卸载redis服务
只需把安装命令中的--service-install修改为--service-uninstall即可,如下
E:/Redis-Cluster/Redis-x64-3.2.100/redis-server.exe --service-uninstall E:/Redis-Cluster/Redis-x64-3.2.100/redis.6380.conf --service-name redis6380 |
启动redis服务
使用完整路径,避免集群出现问题
E:/Redis-Cluster/Redis-x64-3.2.100/redis-server.exe --service-start --service-name redis6380 |
注:如果服务状态在正在运行时执行了卸载命令,这时服务窗口的Redis服务还是会显示,只有当服务停止后才不会再显示
停止redis服务
只需把安装命令中的--service-start修改为--service-stop即可,如下
E:/Redis-Cluster/Redis-x64-3.2.100/redis-server.exe --service-stop --service-name redis6380 |
redis-trib.rb创建集群
将redis-trib.rb文件拷贝到Redis安装目录下,在此目录执行cmd命令创建集群(若解压目录中有redis-trib.rb文件,可直接执行cmd命令创建集群)
E:/Redis-Cluster/Redis-x64-3.2.100/redis-trib.rb create --replicas 1 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6385 |
./redis-trib.rb create –replicas X
X:指定集群中每个主节点配备几个从节点,这里设置为1
启动信息(中间会提示是否设置配置,输入yes),每个主节点分配的哈希槽信息和主从分配信息在此都可查看
>>> Creating cluster |
redis-trib.rb工具的使用
#创建集群 |
sentinel哨兵配置
创建sentinel.conf
在Redis安装根目录下,创建sentinel6380.conf文件,然后复制5份sentinel6381.conf、sentinel6382.conf、sentinel6383.conf、sentinel6384.conf、sentinel6385.conf
port 6380 |
port 6381 |
port 6382 |
port 6383 |
port 6384 |
port 6385 |
启动哨兵服务
redis-server.exe sentinel6380.conf --sentinel |
查看主从变化
自主关闭或启动服务,进入Redis安装根目录下,在cmd窗口中执行命令,查看主从变化,如下查看6379
redis-cli.exe -h 127.0.0.1 -p 6379 |
Linux
本文使用的环境
Linux:CentOS7
Jdk:1.7以上版本
官网提供了Linux版的Redis下载,官网下载地址:
Redis 单机
环境准备
Redis安装在Linux上,redis是c语言开发的,需要依赖gcc-c++环境。
yum -y install cpp binutils glibc glibc-kernheaders glibc-common glibc-devel gcc make gcc-c++ libstdc++-devel tcl |
如果安装过则不会执行
make gcc-c++ libstdc++-devel tcl |
安装
在安装之前可以先查看是否已经启动了redis,执行ps –ef | grep redis命令,再使用kill -9 redis进程号杀进程;删除已经安装的redis文件
cd /usr/local/redis && rm –rf bin |
进入root目录,并上传压缩包redis-3.2.4.tar.gz
cd /root/software |
解压安装包,并进入解压的文件夹
tar -zxvf redis-3.2.4.tar.gz && cd redis-3.2.4 |
执行安装,并指定安装路径
make install PREFIX=/usr/local/redis |
查看安装目录
cd /usr/local/redis/bin/ |
常用的是客户端和服务端:redis-cli 是客户端;redis-server 是服务端
启动
前端启动(不推荐)
这里的前端启动,指的是系统的操作界面
./redis-server |
确认redis安装正常,效果:
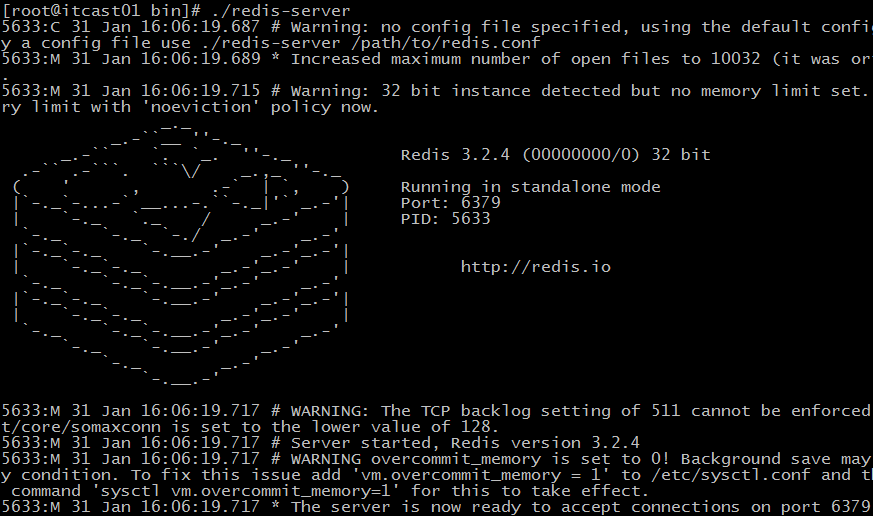
后台启动
从安装包中复制redis.conf文件到/usr/local/redis/bin中
cp /root/software/redis-3.2.4/redis.conf ./ |
修改redis.conf配置文件
vi redis.conf |
设置后台启动redis,修改如下,默认为no
daemonize yes |
设置不仅限制本地访问,注释掉
bind 127.0.0.1 |
禁用保护模式,默认无密码的情况下redis的安全模式protected-mode是开启的,不禁用保护模式的话,必须给redis设置一个访问密码
把 `protected-mode yes` 改为 `protected-mode no ` |
小技巧:vim打开文件中查找内容的方式为底行模式按 /,然后输入要查找的内容即可(shift + n下一个)。如果被选中了后不想被选中则可以随意输入查找来消除选中效果
启动
./redis-server redis.conf |
查看启动
ps -ef | grep redis |
连接
使用redis-cli客户端连接
./redis-cli |
输入ping ,返回pong

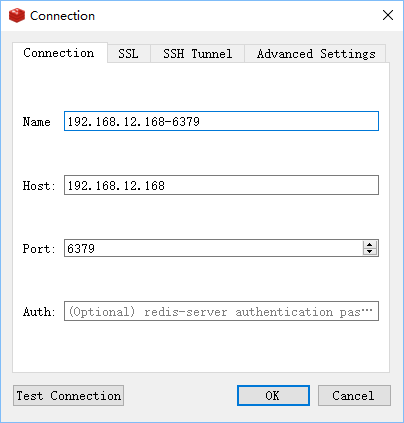
图形化界面连接
使用图形化界面测试访问192.168.12.168为例,redis默认端口为6379;示例图工具是Redis Desktop Manager
Redis 集群(重点)
准备6个实例
为了保证可以进行投票,至少需要3个主节点。每个主节点都需要至少一个从节点,所以需要至少3个从节点。一共需要6台redis服务器;可以使用6个redis实例。6个redis实例的端口号:7001~7006
复制实例
如果有安装过单机版,那么先停止单机版redis
./redis-cli shutdown |
如果有安装过集群版,那么先停止集群版redis;使用命令找出当前的所有redis进程,然后kill
ps -ef | grep redis |
把bin目录里面的rdb和aof持久文件删除,准备干净的redis
cd /usr/local/redis/bin |
删除原有的redis-cluster
rm –rf redis-cluster |
创建redis-cluster目录
mkdir redis-cluster |
把bin复制6份
cp -r bin redis-cluster/redis1 && cp -r bin redis-cluster/redis2 && cp -r bin redis-cluster/redis3 |

修改端口号
依次修改端口号为7001~7006
cd redis1 |
修改第84行,端口6379为7001,其它5个一样修改

同时启动6个实例
cd /usr/local/redis/redis-cluster |
编写启动脚本
vi start-all.sh |
在文件中输入如下内容:
cd redis1 |
设置脚本启动权限
chmod u+x start-all.sh |
执行脚本启动6个实例
./start-all.sh |
查看启动是否正常
ps -ef | grep redis |

停止6个redis,后续使用redis-trib.rb集群管理工具启动集群
ps -ef | grep redis |
安装环境
redis集群的管理工具使用的是ruby脚本语言,安装集群需要ruby环境
yum install ruby |
安装Ruby的打包系统
yum install rubygems |
使用工具上传redis-3.2.1.gem到/root/software后,安装redis的ruby驱动
gem install redis-3.2.1.gem |

创建redis集群
配置集群节点
需要修改每个实例的redis.conf配置文件,开启redis-cluster
cd /usr/local/redis/redis-cluster/ |
开启集群(记得修改6个节点)
cluster-enabled yes |
重启redis实例
./start-all.sh |
集群启动
集群管理工具redis-trib.rb在redis解压文件 src 文件夹中;使用redis-cluster的集群管理工具启动集群。先进入集群管理工具所在的路径
cd /root/software/redis-3.2.4/src/ |
启动命令(如下连接中的ip最好不用127.0.0.1和默认端口)
./redis-trib.rb create --replicas 1 192.168.12.168:7001 192.168.12.168:7002 192.168.12.168:7003 192.168.12.168:7004 192.168.12.168:7005 192.168.12.168:7006 |
./redis-trib.rb create –replicas X
X:指定集群中每个主节点配备几个从节点,这里设置为1
redis-trib.rb 启动信息和工具的使用,与 Windows 集群版的一致,在此不再累述
节点的增删查改
增加主节点
- 增加节点
增加节点7007,把bin复制一份到redis-cluster目录下,如上述修改配置文件端口,再启动
cp -r bin redis-cluster/redis7 |
命令:
# 前面一个[ip]:[port]是新建需要加入的服务节点(7007),后面一个是目标服务节点(7001) |
>>> Adding node 192.168.12.168:7007 to cluster 192.168.12.168:7001 |
- 查看节点信息
命令:
cluster nodes |
可以看到7007已经加入集群,但是还没有分配哈希槽
28b8be6f285e363a957a275143das56da161z4ca 192.168.12.168:7007 master - 0 1481537186131 0 connected |
- 分配哈希槽
命令,redis安装目录src文件夹下执行
#./redis-trib.rb reshard [ip]:[port] |
执行命令后,第一步确认分哈希槽数量(2000),第二步确认目标节点的ID(28b8be6f285e363a957a275143das56da161z4ca),第三步确认是否节点均分(#1:all);所有确认完成开始节点调整
>>> Performing Cluster Check (using node 192.168.12.168:7001) |
- 再次查看节点信息
命令:
cluster nodes |
可以看到7007已经加入集群,并且分配哈希槽
28b8be6f285e363a957a275143das56da161z4ca 192.168.12.168:7007 master - 0 1481537186131 7 connected 0-665 5461-6127 10923-11588 |
增加从节点
上述已增加7007新节点,至此无需分配哈希槽,直接让7007新节点成为192.168.12.168:7001的从节点,[nodeid]为192.168.12.168:7001的节点ID(28b8be6f285e363a957a275143dc6c5a16640d27),命令
# redis-cli -c -p [port] cluster replicate [nodeid] |
查看7007是否已经成为7001的从节点
redis-cli -p 7007 cluster nodes | grep slave | grep 28b8be6f285e363a957a275143dc6c5a16640d27 |
删除主节点
- 回收哈希槽
命令,redis安装目录src文件夹下执行
#./redis-trib.rb reshard [ip]:[port] |
执行命令后,第一步确认回收哈希槽数量(2000),第二步确认接收哈希槽的节点ID(28b8be6f285e363a957a275143dc6c5a16640d27),第三步确认会被回收哈希槽的节点ID(28b8be6f285e363a957a275143das56da161z4ca),第四步输入 done 表示输入完毕;所有确认完成开始节点调整
>>> Performing Cluster Check (using node 192.168.12.168:7001) |
- 删除节点
命令,需要删除节点的ip和端口,nodeid是该节点的id
#./redis-trib.rb del-node [ip]:[port] [nodeid] |
>>> Removing node 28b8be6f285e363a957a275143das56da161z4ca from cluster 192.168.12.168:7007 |
- 查看节点信息
命令,可以看到7007节点已经被删除了,哈希槽已经被分配到7001节点
cluster nodes |
可以看到7007节点的哈希槽已经被分配到7001节点
28b8be6f285e363a957a275143das56da161z4ca 192.168.12.168:7007 master - 0 1481537186131 0 connected |
删除从节点
无需回收哈希槽,直接删除,[ip]:[port]为需删除从节点的主节点(192.168.12.168:7001),[nodeid]为需删除的从节点ID(28b8be6f285e363a957a275143das56da161z4ca)
# ./redis-trib.rb del-node [ip]:[port] [nodeid] |
sentinel哨兵配置
实现主从自动切换,sentinel.conf在redis安装目录下
修改文件配置
- 除sentinel默认端口
26379可不用修改,其它没有注释的选项全注释掉
- 添加监控的master信息
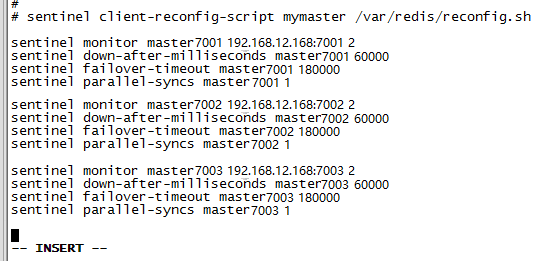
启动sentinel
在redis安装目录下src文件夹下执行命令
./redis-sentinel ../sentinel.conf |
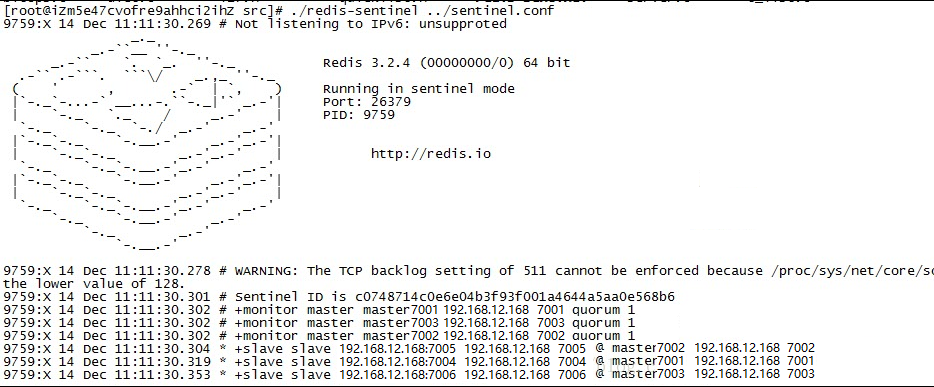
可以测试当7001节点shutdown后,7004会变成主节点,并继承7001的哈希槽。再次启动7001,会发现7001变成了7004的从节点。并且sentinel.conf会自动修改
Redis集群连接
工具连接
redis的单机版,默认是16个数据库,但是redis-Cluster集群版,有多少个主节点,就有多少个数据库(整个集群才是一个完整的数据库)。
- 使用redis命令行客户端连接
cd /usr/local/redis/bin |

注:一定要加 -c 参数,节点之间则可以互相跳转,不然get key的时候会报错
- 使用图形客户端连接
因为有3台主redis数据库,所以需要连接3台。如上述linux单机图形化界面连接
代码连接
public class JedisClusterTest { |
配置详情
redis.conf
- Redis
默认不是以守护进程的方式运行,可修改daemonize为yes启用守护进程
daemonize no |
- 当Redis以守护进程方式运行时,Redis
默认会把pid(进程ID)写入/var/run/redis.pid文件,可以通过pidfile指定
pidfile /var/run/redis.pid |
- 指定Redis监听端口,默认端口为6379
port 6379 |
- 绑定的主机地址
bind 127.0.0.1 |
- 当客户端闲置多长时间后关闭连接,如果
指定为0,表示关闭该功能
timeout 300 |
- 指定
日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
loglevel verbose |
日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
logfile stdout |
- 设置数据库,
默认数据库为0,可以使用SELECT [dbid]命令在连接上指定数据库id
SELECT 9 |
- 指定在多长时间内,有多少次更新操作,就
将数据同步到数据文件,可以多个条件配合
save <seconds> <changes> |
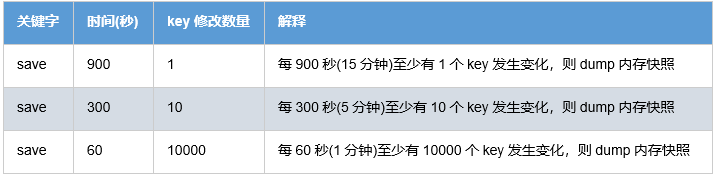
Redis默认配置文件中提供了三个条件:
save 900 1 |
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
- 指定存储至本地数据库时
是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes |
- 指定本地
数据库文件名,默认值为dump.rdb
dbfilename dump.rdb |
- 指定本地数据库
存放目录
dir ./ |
- 设置当本机为slave服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof <masterip> <masterport> |
当master服务设置了密码保护时,slave服务连接master的密码
masterauth <master-password> |
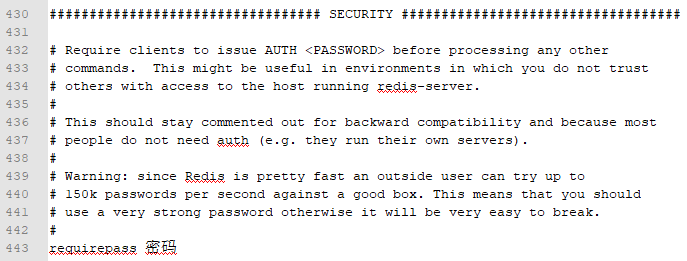
- 设置
Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH命令提供密码, 默认关闭
requirepass 密码 |
方式一:redis.conf配置文件设置(永久方式)
找到# requirepass foobared,去掉#注释,配置密码(或者干脆另起一行,照着写就是),需要重启Redis服务
方式二:命令设置(临时方式)
密码信息保存在服务器内存中,不需要重启Redis服务,但服务器重启后将失效
config set requirepass 密码 #设置密码 |
设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
maxclients 128 |
指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory <bytes> |
- 指定是否在每次更新操作后进行日志记录,
Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
appendonly no |
- 指定更新日志文件名,默认为appendonly.aof
appendfilename appendonly.aof |
- 指定更新日志条件
共有3个可选值:
no:表示等操作系统进行数据缓存同步到磁盘(快)always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)everysec:表示每秒同步一次(折衷,默认值)
appendfsync everysec |
- 指定
是否启用虚拟内存机制,默认值为no,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中
vm-enabled no |
- 虚拟
内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-swap-file /tmp/redis.swap |
- 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,
当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0
vm-max-memory 0 |
- Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,建议如果存储很多小对象,
page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不确定,就使用默认值
vm-page-size 32 |
设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,在磁盘上每8个pages将消耗1byte的内存。
vm-pages 134217728 |
设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
vm-max-threads 4 |
- 设置在向客户端应答时,是否把较小的包合并为一个包发送,
默认为开启
glueoutputbuf yes |
- 指定
在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-zipmap-entries 64 |
- 指定
是否激活重置哈希,默认为开启
activerehashing yes |
- 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
include /path/to/local.conf |
redis-sentinel.conf
- sentinel监听端口,
默认是26379,可以修改。
port 26379 |
sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel去监听地址为 ip:port 的一个master,master-name可自定义,quorum是一个数字,指明当有多少个sentinel认为一个master失效时,master才算真正失效。
sentinel monitor mymaster 192.168.0.5 6379 2 |
master-name:只能包含
英文字母,数字,和“.-_”这三个字符,
master-ip:要写真实的ip地址,而不要用回环地址(127.0.0.1)。
sentinel auth-pass <master-name> <password>
设置连接master和slave时的密码,注意的是sentinel不能分别为master和slave设置不同的密码,因此master和slave的密码必须设置相同。
sentinel auth-pass mymaster 0123passw0rd |
sentinel down-after-milliseconds <master-name> <milliseconds>
指定需要多少失效时间,一个master才会被这个sentinel主观地认为是不可用的。 单位是毫秒,默认为30秒
sentinel down-after-milliseconds mymaster 30000 |
sentinel parallel-syncs <master-name> <numslaves>
指定在发生failover主备切换时最多可以有多少个slave同时对新的master进行同步,数字越小,完成failover所需的时间就越长,数字越大,就意味着越多的slave因为replication而不可用。将值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
sentinel parallel-syncs mymaster 1 |
sentinel failover-timeout <master-name> <milliseconds>
failover-timeout 可以用在以下这些方面:
- 同一个sentinel对同一个master两次failover之间的间隔时间。
- 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
- 当想要取消一个正在进行的failover所需要的时间。
- 当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了。
sentinel failover-timeout mymaster1 20000 |
- sentinel的
notification-script和reconfig-script是用来配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。对于脚本的运行结果有以下规则:
- 若脚本执行后
返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10 - 若脚本执行后
返回2或者比2更高的一个返回值,脚本将不会重复执行。 - 如果脚本在执行过程中由于收到系统中断信号被
终止了,则同返回值为1时的行为相同。 - 一个脚本的
最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
sentinel notification-script <master-name> <script-path>
通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,一个是事件的类型,一个是事件的描述。如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。
sentinel notification-script mymaster /var/redis/notify.sh |
sentinel client-reconfig-script <master-name> <script-path>
当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。以下参数将会在调用脚本时传给脚本:
<master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port> |
目前<role>是“leader”或者“observer”中的一个,<state>总是“failover”。 参数from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的。这个脚本应该是通用的,能被多次调用,不是针对性的。
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh |
高可用
高可用有两个含义:一是数据尽量不丢失,二是服务尽可能提供服务。AOF和RDB保证了数据持久化尽量不丢失,而主从复制就是增加副本,一份数据保存到多个实例上。即使有一个实例宕机,其他实例依然可以提供服务。
主从复制
概述
Redis提供了主从模式,通过主从复制,将数据冗余一份复制到其他Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
数据如何保证一致性
为了保证副本数据的一致性,主从架构采用了读写分离的方式。
- 读操作:主、从库都可以执行;
- 写操作:主库先执行,之后将写操作同步到从库;
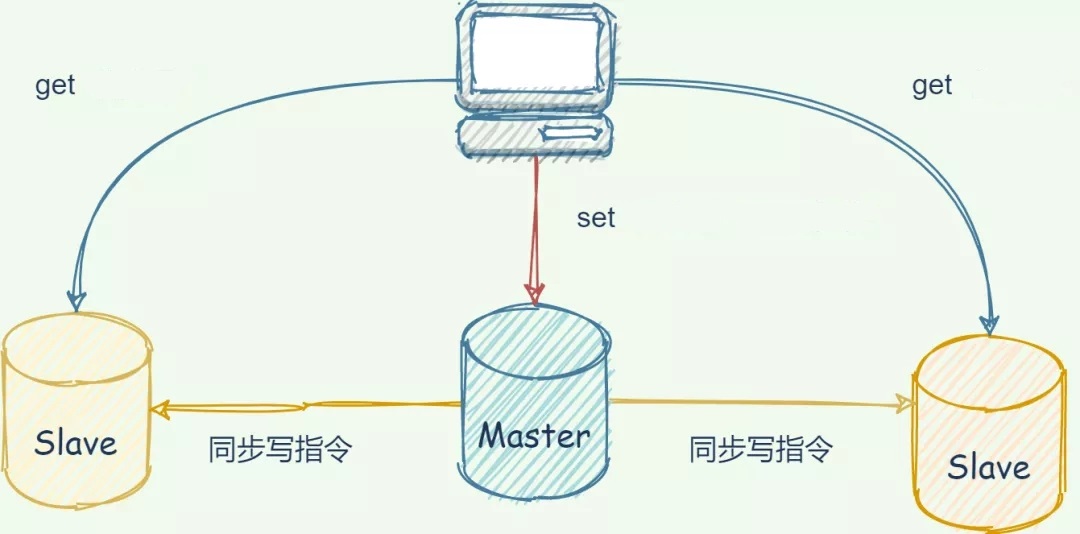
为何要采用读写分离的方式
可以假设主从库都可以执行写指令,假如对同一份数据分别修改了多次,每次修改发送到不同的主从实例上,就导致是实例的副本数据不一致了。
如果为了保证数据一致,Redis 需要加锁,协调多个实例的修改,Redis 自然不会这么干!
主从复制还有其他作用么
故障恢复:当主节点宕机,其他节点依然可以提供服务;负载均衡:Master 节点提供写服务,Slave节点提供读服务,分担压力;高可用基石:是哨兵和集群(cluster)实施的基础,是高可用的基石。
搭建
主从复制的开启,完全是在从节点发起的,不需要我们在主节点做任何事情。可以通过replicaof(Redis5.0之前使用slaveof)命令形成主库和从库的关系。
在从节点开启主从复制,有 3 种方式:
- 配置文件
在从服务器的配置文件中加入replicaof [masterip] [masterport]- 启动命令
redis-server 启动命令后面加入--replicaof [masterip] [masterport]- 客户端命令
启动多个 Redis 实例后,直接通过客户端执行命令:replicaof [masterip] [masterport],则该 Redis 实例成为从节点。
比如假设现在有实例 1(172.16.88.1)、实例 2(172.16.88.2)和实例 3 (172.16.88.3),在实例 2 和实例 3 上分别执行以下命令,实例 2 和 实例 3 就成为了实例 1 的从库,实例 1 成为 Master。
replicaof 172.16.88.1 6379 |
原理
主从库模式一旦采用了读写分离,所有数据的写操作只会在主库上进行,不用协调三个实例。主库有了最新的数据后,会同步给从库,这样,主从库的数据就是一致的。
- 主从库同步是如何完成的呢?主库数据是一次性传给从库,还是分批同步?正常运行中又怎么同步呢?要是主从库间的网络断连了,重新连接后数据还能保持一致吗?
同步分为三种情况:
- 第一次主从库全量复制;
- 主从库间网络断开重连同步。
- 主从正常运行期间的同步;
主从库第一次全量复制
主从库第一次复制过程大体可以分为3个阶段:连接建立阶段(即准备阶段)、主库同步数据到从库阶段、发送同步期间新写命令到从库阶段;
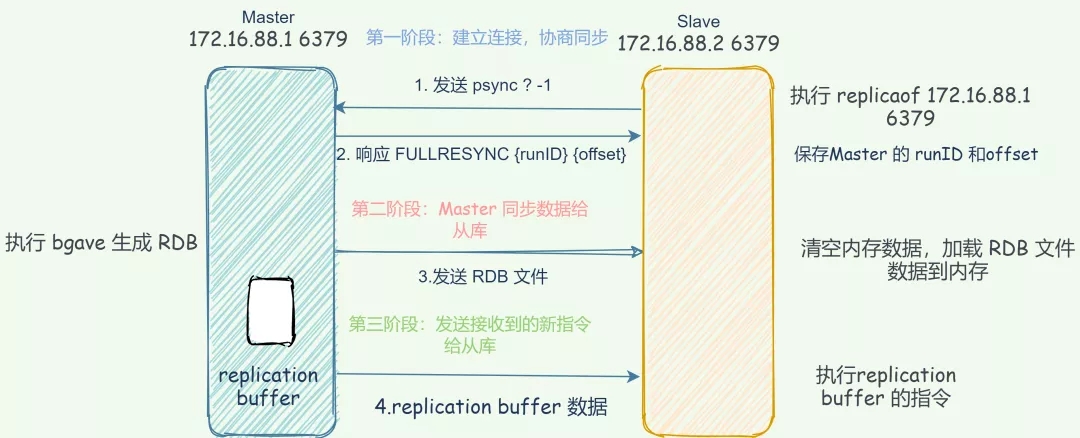
建立连接
该阶段的主要作用是在主从节点之间建立连接,为数据全量同步做好准备。从库会和主库建立连接,从库执行replicaof并发送psync命令并告诉主库即将进行同步,主库确认回复后,主从库间就开始同步了。
从库怎么知道主库信息并建立连接的呢?
- 在
从节点的配置文件中的 replicaof 配置项中配置了主节点的 IP 和 port 后,从节点就知道自己要和那个主节点进行连接了。- 从节点内部维护了两个字段,
masterhost 和 masterport,用于存储主节点的 IP 和 port 信息。- 从库执行
replicaof并发送psync 命令,表示要执行数据同步,主库收到命令后根据参数启动复制。命令包含了主库的 runID和复制进度 offset两个参数。
runID:每个 Redis 实例启动都会自动生成一个 唯一标识 ID,第一次主从复制,还不知道主库 runID,参数设置为 「?」。offset:第一次复制设置为 -1,表示第一次复制,记录复制进度偏移量。
主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。从库收到响应后,会记录下这两个参数。
FULLRESYNC 响应表示第一次复制采用的全量复制,也就是说,主库会把当前所有的数据都复制给从库。
主库同步数据给从库
master 执行 bgsave命令生成 RDB 文件,并将文件发送给从库,同时主库为每一个 slave(从库) 开辟一块replication buffer缓冲区记录从生成RDB文件开始收到的所有写命令。
从库收到 RDB 文件后保存到磁盘,并清空当前数据库的数据,再加载 RDB 文件数据到内存中。
主库将数据同步到从库过程中,可以正常接受请求么?
主库不会被阻塞,在生成 RDB 文件之后的写操作并没有记录到刚刚的 RDB 文件中,为了保证主从库数据的一致性,所以主库会在内存中使用一个叫 replication buffer 记录 RDB 文件生成后的所有写操作。
为啥从库收到 RDB 文件后要清空当前数据库?
因为从库在通过 replcaof命令开始和主库同步前可能保存了其他数据,防止主从数据之间的影响。
replication buffer 到底是什么玩意?
一个在 master 端上创建的缓冲区,存放的数据是下面三个时间内所有的 master 数据写操作。
master 执行 bgsave产生 RDB 的期间的写操作;master 发送 RDB 到 slave网络传输期间的写操作;slave load RDB文件把数据恢复到内存的期间的写操作。
Redis 和客户端通信也好,和从库通信也好,Redis 都分配一个内存 buffer 进行数据交互,客户端就是一个 client,从库也是一个 client,我们每个 client 连上 Redis 后,Redis 都会分配一个专有 client buffer,所有数据交互都是通过这个 buffer 进行的。
Master 先把数据写到这个 buffer 中,然后再通过网络发送出去,这样就完成了数据交互。
不管是主从在增量同步还是全量同步时,master 会为其分配一个 buffer ,只不过这个 buffer 专门用来传播写命令到从库,保证主从数据一致,我们通常把它叫做 replication buffer。
replication buffer 太小会引发的问题?replication buffer由client-output-buffer-limit slave设置,当这个值太小会导致主从复制连接断开。
- 当 master-slave 复制连接断开,master 会释放连接相关的数据。replication buffer 中的数据也就丢失了,此时主从之间重新开始复制过程。
- 还有个更严重的问题,
主从复制连接断开,导致主从上出现重新执行 bgsave 和 rdb 重传操作无限循环。
当主节点数据量较大,或者主从节点之间网络延迟较大时,可能导致该缓冲区的大小超过了限制,此时主节点会断开与从节点之间的连接;
这种情况可能引起全量复制 -> replication buffer 溢出导致连接中断 -> 重连 -> 全量复制 -> replication buffer 缓冲区溢出导致连接中断……的循环。
因而推荐把 replication buffer 的 hard/soft limit 设置成 512M
config set client-output-buffer-limit "slave 536870912 536870912 0" |
主从库复制为何不使用 AOF 呢?相比 RDB 来说,丢失的数据更少。
- RDB 文件是二进制文件,
网络传输 RDB 和写入磁盘的 IO 效率都要比 AOF 高。- 从库进行数据恢复的时候,
RDB 的恢复效率也要高于 AOF。
发送新写命令到从库
从节点加载 RDB 完成后,主节点将 replication buffer 缓冲区的数据发送到从节点,Slave 接收并执行,从节点同步至主节点相同的状态。
增量复制
在 Redis 2.8 之前,如果主从库在命令传播时出现了网络闪断,那么,从库就会和主库重新进行一次全量复制,开销非常大。从 Redis 2.8 开始,网络断了之后,主从库会采用增量复制的方式继续同步。
增量复制:
用于网络中断等情况后的复制,只将中断期间主节点执行的写命令发送给从节点,与全量复制相比更加高效。
repl_backlog_buffer断开重连增量复制的实现奥秘就是
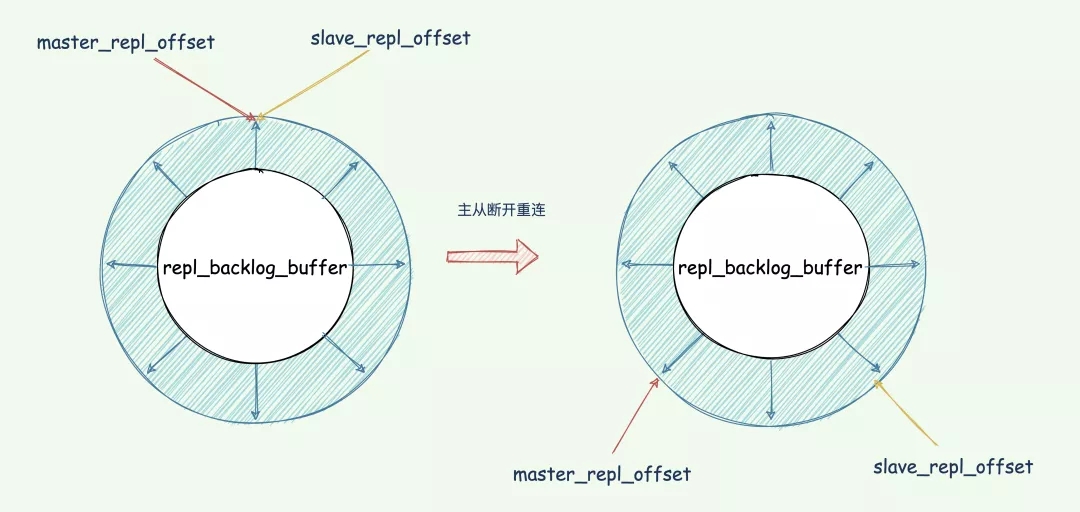
repl_backlog_buffer缓冲区,不管在什么时候 master 都会将写指令操作记录在repl_backlog_buffer中,因为内存有限,repl_backlog_buffer是一个定长的环形数组,如果数组内容满了,就会从头开始覆盖前面的内容。
master 使用 master_repl_offset记录自己写到的位置偏移量,slave 则使用 slave_repl_offset记录已经读取到的偏移量。
master 收到写操作,偏移量则会增加。从库持续执行同步的写指令后,在 repl_backlog_buffer 的已复制的偏移量 slave_repl_offset 也在不断增加。
正常情况下,这两个偏移量基本相等。在网络断连阶段,主库可能会收到新的写操作命令,所以 master_repl_offset会大于 slave_repl_offset。
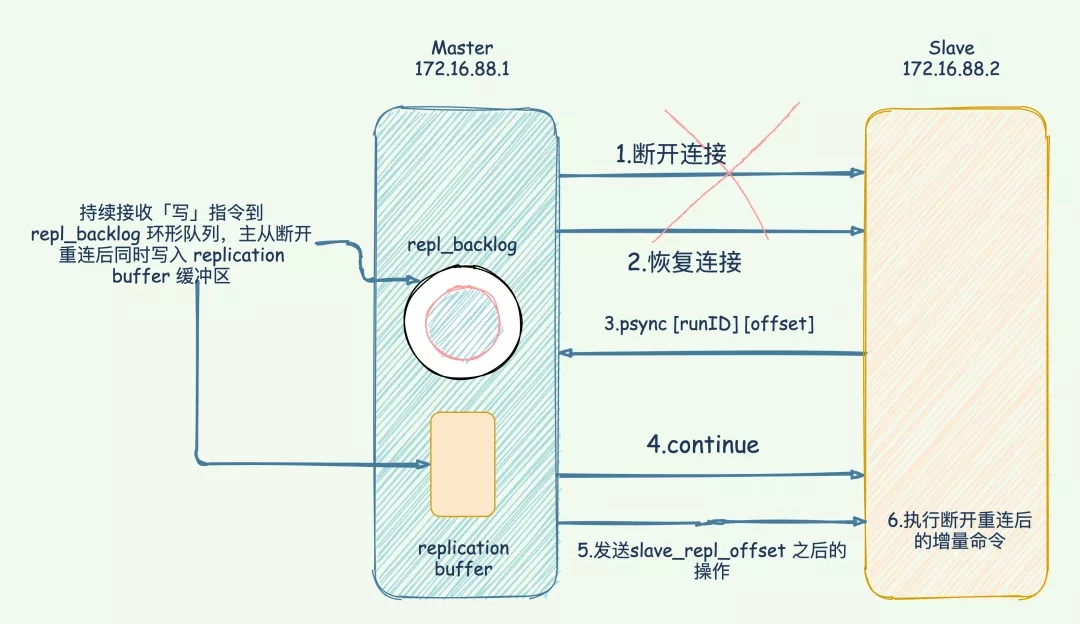
当主从断开重连后,slave 会先发送 psync 命令给 master,同时将自己的 runID,slave_repl_offset发送给 master。
master 只需要把 master_repl_offset与 slave_repl_offset之间的命令同步给从库即可。
增量复制执行流程如下图:
repl_backlog_buffer 太小的话从库还没读取到就被 Master 的新写操作覆盖了咋办?要想办法避免这个情况,一旦被覆盖就会执行全量复制。可以
调整 repl_backlog_size 这个参数用于控制缓冲区大小。计算公式:repl_backlog_buffer = second * write_size_per_second
second:从服务器断开重连主服务器所需的平均时间;write_size_per_second:master 平均每秒产生的命令数据量大小(写命令和数据大小总和);
例如,如果主服务器平均每秒产生 1 MB 的写数据,而从服务器断线之后平均要 5 秒才能重新连接上主服务器,那么复制积压缓冲区的大小就不能低于 5 MB。
为了安全起见,可以将复制积压缓冲区的大小设为2 * second * write_size_per_second,这样可以保证绝大部分断线情况都能用部分重同步来处理。
基于长连接的命令传播
当主从库完成了全量复制,它们之间就会一直维护一个网络连接,主库会通过这个连接将后续陆续收到的命令操作再同步给从库,这个过程也称为基于长连接的命令传播,使用长连接的目的就是避免频繁建立连接导致的开销。
在命令传播阶段,除了发送写命令,主从节点还维持着心跳机制:PING 和 REPLCONF ACK。
主->从:PING
每隔指定的时间,主节点会向从节点发送 PING 命令,这个 PING 命令的作用,主要是为了让从节点进行超时判断。
从->主:REPLCONF ACK
在命令传播阶段,从服务器默认会以每秒一次的频率,向主服务器发送命令
# replication_offset 是从服务器当前的复制偏移量 |
- 发送
REPLCONF ACK命令对于主从服务器有三个作用:
- 检测主从服务器的
网络连接状态。- 辅助实现
min-slaves选项。- 检测命令丢失, 从节点发送了自身的 slave_replication_offset,主节点会用自己的 master_replication_offset 对比,如果从节点数据缺失,主节点会从 repl_backlog_buffer缓冲区中找到并推送缺失的数据。
注意,offset 和 repl_backlog_buffer 缓冲区,不仅可以用于部分复制,也可以用于处理命令丢失等情形;区别在于前者是在断线重连后进行的,而后者是在主从节点没有断线的情况下进行的。
相关问题
如何确定执行全量同步还是部分同步?
在 Redis 2.8 及以后,从节点可以发送 psync 命令请求同步数据,此时根据主从节点当前状态的不同,同步方式可能是全量复制或部分复制。关键就是 psync的执行
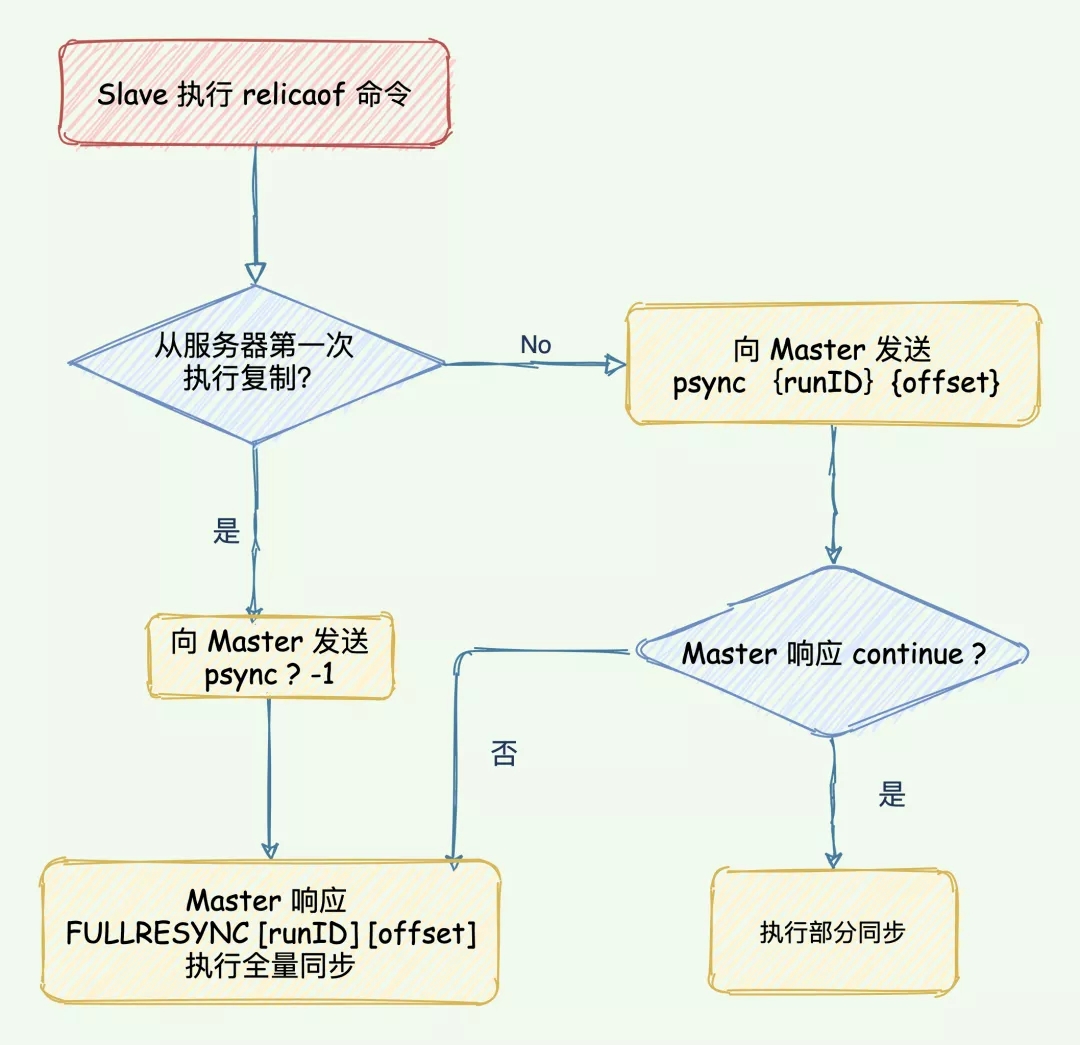
- 从节点根据当前状态,发送
psync命令给 master:
- 如果从节点
从未执行过 replicaof,则从节点发送psync ? -1,向主节点发送全量复制请求;- 如果从节点之前
执行过 replicaof则发送psync [runID] [offset], runID 是上次复制保存的主节点 runID,offset 是上次复制截至时从节点保存的复制偏移量。
- 主节点根据接受到的psync命令和当前服务器状态,决定执行全量复制还是部分复制:
- runID 与从节点发送的 runID 相同,且从节点发送的 slave_repl_offset之后的数据在 repl_backlog_buffer缓冲区中都存在,则回复 CONTINUE,表示将进行部分复制,从节点等待主节点发送其缺少的数据即可;
- runID 与从节点发送的 runID 不同,或者从节点发送的 slave_repl_offset 之后的数据已不在主节点的 repl_backlog_buffer缓冲区中 (在队列中被挤出了),则回复从节点 FULLRESYNC
,表示要进行全量复制,其中 runID 表示主节点当前的 runID,offset 表示主节点当前的 offset,从节点保存这两个值,以备使用。
一个从库如果和主库断连时间过长,造成它在主库 repl_backlog_buffer的 slave_repl_offset 位置上的数据已经被覆盖掉了,此时从库和主库间将进行全量复制。
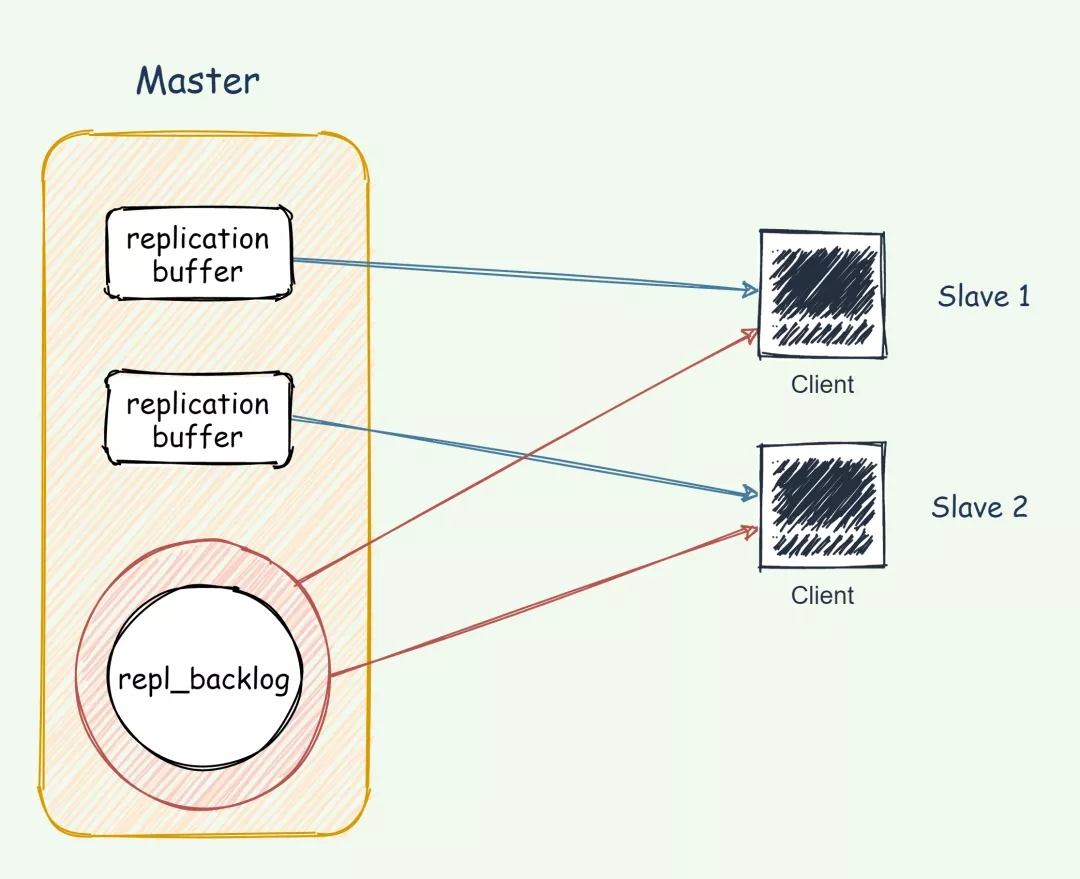
replication buffer 和 repl_backlog_buffer
- replication buffer 对应于每个 slave,通过
config set client-output-buffer-limit slave设置。repl_backlog_buffer是一个环形缓冲区,整个 master 进程中只会存在一个,所有的 slave 公用。repl_backlog 的大小通过repl-backlog-size参数设置,默认大小是 1M,其大小可以根据每秒产生的命令、(master 执行 rdb bgsave) +( master 发送 rdb 到 slave) + (slave load rdb 文件)时间之和来估算积压缓冲区的大小,repl-backlog-size 值不小于这两者的乘积。
replication buffer 是主从库在进行全量复制时,主库上用于和从库连接的客户端的 bufferrepl_backlog_buffer 是为了支持从库增量复制,主库上用于持续保存写操作的一块专用 buffer。
repl_backlog_buffer是一块专用 buffer,在 Redis 服务器启动后,开始一直接收写操作命令,这是所有从库共享的。主库和从库会各自记录自己的复制进度,所以,不同的从库在进行恢复时,会把自己的复制进度(slave_repl_offset)发给主库,主库就可以和它独立同步。
主从复制的场景下,从节点会删除过期数据么?
为了主从节点的数据一致性,从节点不会主动删除数据。Redis有两种删除策略:
- 惰性删除:当客户端查询对应的数据时,Redis判断该数据是否过期,过期则删除。
- 定期删除:Redis 通过定时任务删除过期数据。
那客户端通过从节点读取数据会不会读取到过期数据?
Redis 3.2 开始,通过从节点读取数据时,先判断数据是否已过期。如果过期则不返回客户端,并且删除数据。
单机内存大小限制
如果 Redis 单机内存达到 10GB,一个从节点的同步时间在几分钟的级别;如果从节点较多,恢复的速度会更慢。如果系统的读负载很高,而这段时间从节点无法提供服务,会对系统造成很大的压力。
如果数据量过大,全量复制阶段主节点 fork + 保存 RDB 文件耗时过大,从节点长时间接收不到数据触发超时,主从节点的数据同步同样可能陷入全量复制->超时导致复制中断->重连->全量复制->超时导致复制中断……的循环。
此外,主节点单机内存除了绝对量不能太大,其占用主机内存的比例也不应过大:最好只使用 50% - 65% 的内存,留下 30%-45% 的内存用于执行 bgsave 命令和创建复制缓冲区等。
结论
- 主从复制的
作用:AOF 和 RDB 二进制文件保证了宕机快速恢复数据,尽可能的防止丢失数据。但是宕机后依然无法提供服务,所以便演化出主从架构、读写分离。 - 主从复制
原理:连接建立阶段、数据同步阶段、命令传播阶段;数据同步阶段又分为 全量复制和部分复制;命令传播阶段主从节点之间有 PING 和 REPLCONF ACK 命令互相进行心跳检测。 - 主从复制
虽然解决或缓解了数据冗余、故障恢复、读负载均衡等问题,但其缺陷仍很明显:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制;这些问题的解决,需要哨兵和集群的帮助
哨兵机制
什么是哨兵(Sentinel)
Redis 主从架构就好比一个武当,掌门人就是 Master。掌门人如果挂了,需要从武当七侠里面选举能人担当掌门人。这就需要一个部门能监控掌门人的生死和武当其他弟子的生命状态,并且能够通过投票从武当弟子中选举一个能者担任新掌门,接着再举行新闻发布会向世界宣布新掌门的信息。这个「部门」就是哨兵。
哨兵在选举新掌门会遇到以下几个问题:
- 如何判断掌门真的挂了,有可能假死;
- 到底选择哪一个武当子弟作为新掌门?
- 通过新闻发布会将新掌门的相关信息通知到所有武当弟子(slave 和 master)和整个武林(客户端)。
哨兵部门主要负责的任务是:监控整个武当、选择新掌门,通知整个武当和整个武林。
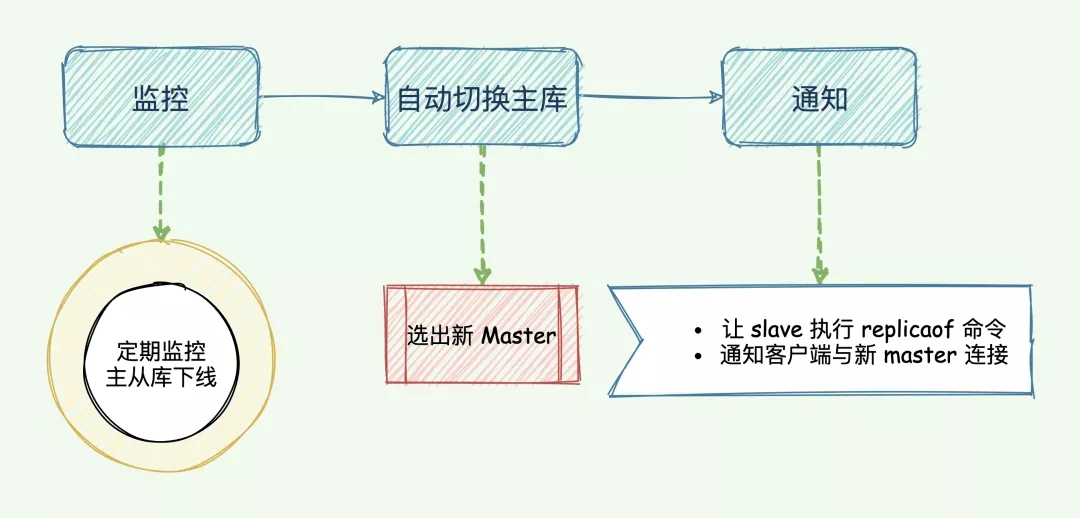
主要任务
哨兵是 Redis 的一种运行模式,它专注于对 Redis 实例(主节点、从节点)运行状态的监控,并能够在主节点发生故障时通过一系列的机制实现选主及主从切换,实现故障转移,确保整个 Redis 系统的可用性。可以知道 Redis 哨兵具备的能力有如下几个:
监控:持续监控 master 、slave 是否处于预期工作状态。自动切换主库:当 Master 运行故障,哨兵启动自动故障恢复流程:从 slave 中选择一台作为新 master。通知:让 slave 执行 replicaof ,与新的 master 同步;并且通知客户端与新 master 建立连接。
哨兵也是一个 Redis进程,只是不对外提供读写服务,通常哨兵要配置成单数
监控
Sentinel 只是武当弟子中的特殊部门,在默认情况下,Sentinel 通过飞鸽传书以每秒一次的频率向所有武当弟子、掌门与哨兵(包括 Master、Slave、其他 Sentinel 在内)发送 PING 命令,如果 slave 没有在在规定时间内响应「哨兵」的 PING 命令,「哨兵」就认为这哥们可能嗝屁了,就会将他记录为「下线状态」;
假如 master 掌门没有在规定时间响应 「哨兵」的 PING 命令,哨兵就判定掌门下线,开始执行「自动切换 master 掌门」的流程。
PING 命令的回复有两种情况:
有效回复:返回 +PONG、-LOADING、-MASTERDOWN 任何一种;无效回复:有效回复之外的回复,或者指定时间内返回任何回复。
为了防止掌门「假死」,「哨兵」设计了「主观下线」和「客观下线」两种暗号。
主观下线
哨兵利用 PING 命令来检测掌门、 slave 的生命状态。如果是无效回复,哨兵就把这个哥们标记为「主观下线」。如果检测到的是武当小弟,也就是 slave 角色。那么就直接标记「主观下线」。
因为 master 掌门还在,slave 的嗝屁对整个武当影响不大。依然可以对外开会,比武论剑、吃香喝辣……
如果检测到是master 掌门完蛋,这时候哨兵不能这么简单的标记「主观下线」,开启新掌门选举。
因为有可能出现误判,掌门并没有嗝屁,一旦启动了掌门切换,后续的选主、通知开发布会,slave 花时间与新 master 同步数据都会消耗大量资源。
所以「哨兵」要降低误判的概率,误判一般会发生在集群网络压力较大、网络拥塞,或者是主库本身压力较大的情况下。
既然一个人容易误判,那就多个人一起投票判断。哨兵机制也是类似的,采用多实例组成的集群模式进行部署,这就是哨兵集群。引入多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。
同时,多个哨兵的网络同时不稳定的概率较小,由它们一起做决策,误判率也能降低。
客观下线
判断 master 是否下线不能只有一个「哨兵」说了算,只有过半的哨兵判断 master 已经「主观下线」,这时候才能将 master 标记为「客观下线」,也就是说这是一个客观事实,掌门真的嗝屁了,华佗再世也治不好了。
只有 master 被判定为「客观下线」,才会进一步触发哨兵开始主从切换流程。
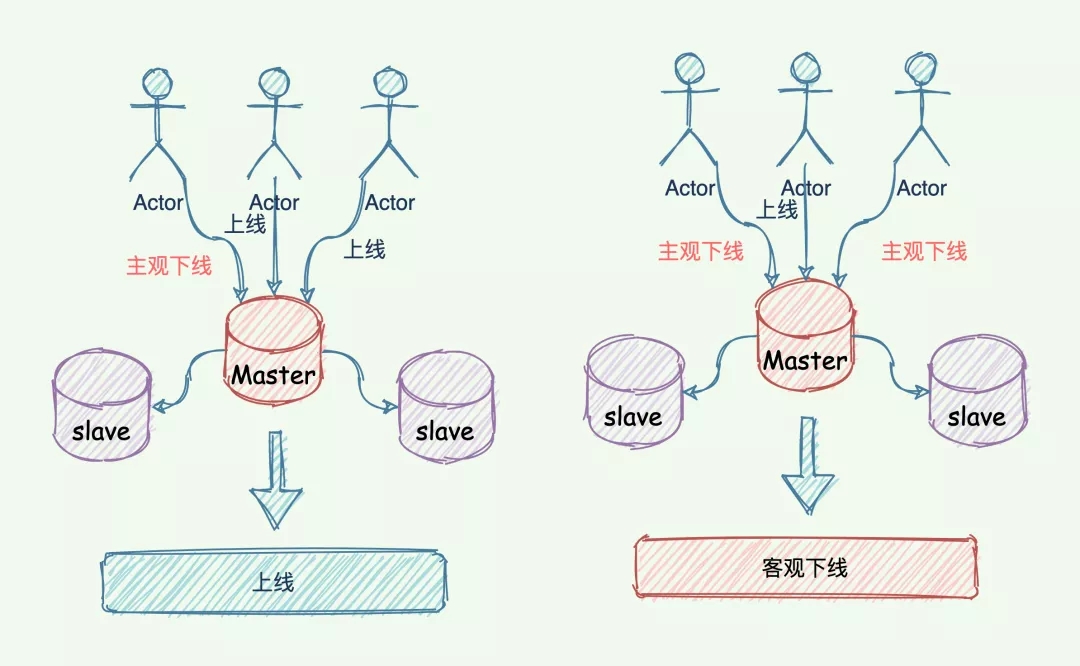
主观下线与客观下线的区别
简单来说,主观下线是哨兵自己认为节点宕机,而客观下线是不但哨兵自己认为节点宕机,而且该哨兵与其他哨兵沟通后,达到一定数量的哨兵都认为该哥们嗝屁了。
这里的「一定数量」是一个法定数量(Quorum),是由哨兵监控配置决定的,解释一下该配置:
# sentinel monitor <master-name> <master-host> <master-port> <quorum> |
这条配置项用于告知哨兵需要监听的主节点:
- sentinel monitor:代表监控。
- mymaster:代表
主节点的名称,可以自定义。- 127.0.0.1 6379:代表监控的
主节点 ip,6379 代表端口。- 2:
法定数量,代表只有两个或两个以上的哨兵认为主节点不可用的时候,才会把 master 设置为客观下线状态,然后进行failover 操作。
自动切换主库
「哨兵」的第二个任务,选择新 master 掌门。需要从武当弟子中按照一定规则选择一个牛逼人物作为新掌门,完成选任掌门后,新 master 带领众弟子一起吃香喝辣。
按照一定的「筛选条件」 + 「打分」 策略,选出「最强王者」担任掌门,也就是通过一些条件海选过滤一些「无能之辈」,接着将通过海选的靓仔全都打分排名,将最高者选为新 master。
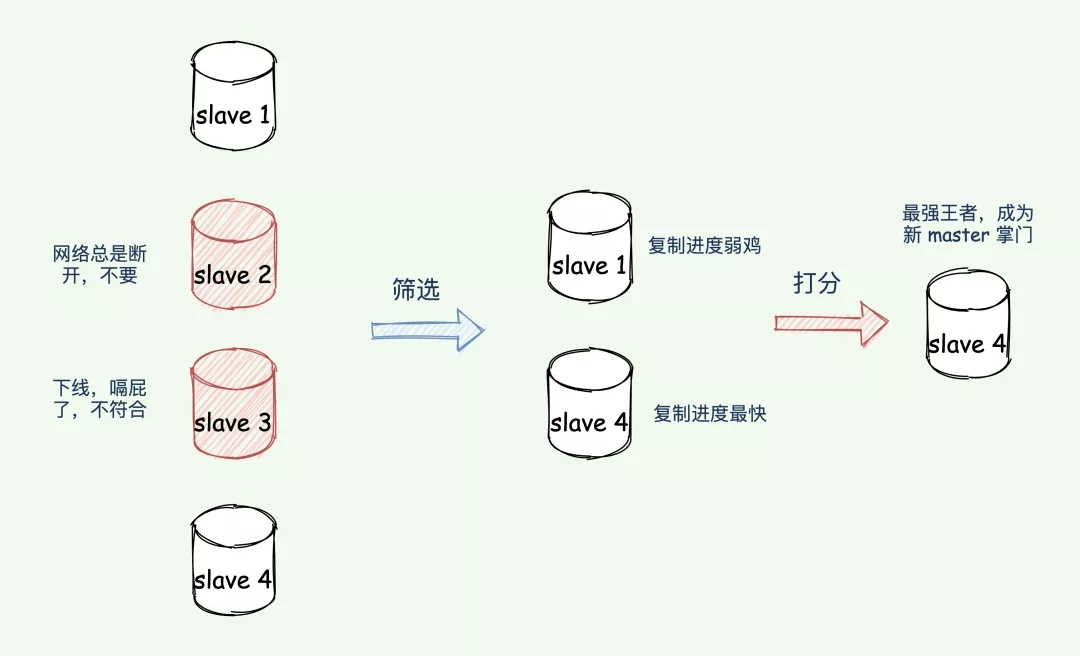
筛选条件
- 从库当前在线状态,下线的直接丢弃;
- 评估之前的网络连接状态
down-after-milliseconds * 10:如果从库总是和主库断连,而且断连次数超出了一定的阈值(10 次),我们就有理由相信,这个从库的网络状况并不是太好,就可以把这个从库筛掉了。
打分
过滤掉不合适的 slave 之后,则进入打分环节。打分会按照三个规则进行三轮打分,规则分别为:
slave 优先级,通过 slave-priority 配置项,给不同的从库设置不同优先级(后台有人没办法),优先级高的直接晋级为新 master 掌门。- slave_repl_offset与 master_repl_offset进度差距(谁的武功与之前掌门的功夫越接近谁就更牛逼),如果都一样,那就继续下一个规则。其实就是
比较 slave 与旧 master 复制进度的差距;- slave runID,在优先级和复制进度都相同的情况下,
ID 号最小的从库得分最高,会被选为新主库。(论资排辈,根据 runID 的创建时间来判断,时间早的上位);
通知
重新选举新 master 掌门这种事情,何等大事,怎能不告知天下。再者其他 slave 弟子也要知道新掌门是谁,一起追随新掌门吃香喝辣大保健。
最后一个任务,「哨兵」将新 「master 掌门」的连接信息发送给其他 slave 武当弟子,并且让 slave 执行 replacaof 命令,和新「master 掌门」建立连接,并进行数据复制学习新掌门的所有武功。
除此之外,「哨兵」还需要将新掌门的连接信息通知整个武林(客户端),使得让所有想拜访、讨教的人能找到新任掌门,这样诸多事宜才能交给新掌门做决定(将读写请求转移到新 master)。
哨兵的主要任务与实现目标
工作原理
「哨兵」部门并不是一个人,多个人共同组成一个「哨兵集群」,即使有一些「哨兵」被老王打死了,其他的「哨兵」依然可以共同协作完成监控、新掌门选举以及通知 slave 、master 以及每一个武林人士(客户端)。
在配置哨兵集群的时候,哨兵配置中只设置了监控的 master IP 和 port,并没有配置其他哨兵的连接信息。
sentinel monitor <master-name> <master-host> <master-port> <quorum> |
哨兵之间是如何知道彼此的?如何知道slave并监控他们的?由哪一个「哨兵」执行主从切换呢?
pub/sub 实现哨兵间通信和发现 slave
哨兵之间可以相互通信约会搞事情,主要归功于 Redis 的pub/sub 发布/订阅机制。
哨兵与 master 建立通信,利用 master 提供发布/订阅机制发布自己的信息,比如身高体重、是否单身、IP、端口……
master 有一个 __sentinel__:hello 的专用通道,用于哨兵之间发布和订阅消息。这就好比是 __sentinel__:hello 微信群,哨兵利用master建立的微信群发布自己的消息,同时关注其他哨兵发布的消息。
当多个哨兵实例都在主库上做了发布和订阅操作后,它们之间就能知道彼此的 IP 地址和端口,从而相互发现建立连接。
Redis 通过频道的方式对消息进行分别管理,这里的频道其实就是不同的微信群。
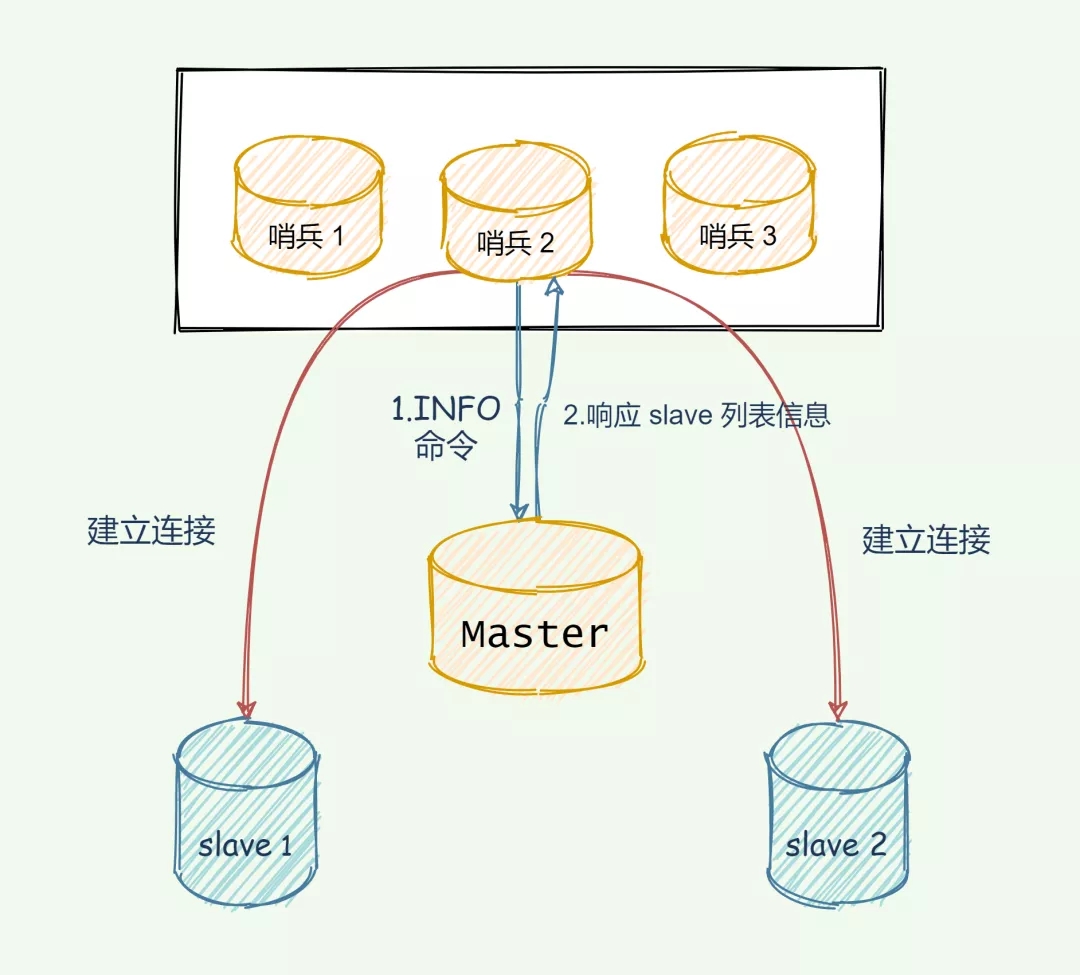
哨兵之间建立连接形成集群还不够,还需要跟slave建立连接,不然没法监控他们,无法对主从库进行心跳判断。
除此之外,如果发生了主从切换也得通知slave重新跟新master建立连接执行数据同步。
关键还是利用 master 来实现,哨兵向 master 发送 INFO 命令, master 掌门自然是知道自己门下所有的 salve 小弟的。所以 master 接收到命令后,便将 slave 列表告诉哨兵。
哨兵根据 master 响应的 slave 名单信息与每一个 salve 建立连接,并且根据这个连接持续监控哨兵。
如图所示,哨兵 2 向 Master 发送 INFO 命令,Master 就把 slave 列表返回给哨兵 2,哨兵 2 便根据 slave 列表连接信息与每一个 slave 建立连接,并基于此连接实现持续监控。
剩下的哨兵也同理基于此实现监控。
选择哨兵执行主从切换
哨兵这么多,那到底让哪一个哨兵来执行新 master 切换呢?
这个跟哨兵判断 master “客观下线”类似,也是通过投票的方式选出来的。
任何一个哨兵判断 master “主观下线”后,就会给其他哨兵基友发送 is-master-down-by-addr 命令,好基友则根据自己跟 master 之间的连接状况分别响应 Y 或者 N ,Y 表示赞成票, N 就是反对。
如果某个哨兵获得了大多数哨兵的“赞成票”之后,就可以标记 master 为 “客观下线”,赞成票数是通过哨兵配置文件中的 quorum 配置项设定。
sentinel monitor <master-name> <master-host> <master-port> <quorum> |
比如一共 3 个哨兵组成集群,那么 quorum 就可以配置成 2,当一个哨兵获得了 2 张赞成票,就可以标记 master “客观下线”,当然这个票包含自己的那一票。
获得多数赞成票的哨兵可以向其他哨兵发送命令,申明自己想要执行主从切换。并让其他哨兵进行投票,投票过程就叫做 “Leader 选举”。
想要成为 “Leader”没那么简单,得有两把刷子。需要满足以下条件:
- 获得其他哨兵基友过半的赞成票;
- 赞成票的数量还要
大于等于配置文件的 quorum 的值。
如果哨兵集群有 2 个实例,此时,一个哨兵要想成为 Leader,必须获得 2 票,而不是 1 票。所以,如果有个哨兵挂掉了,那么,此时的集群是无法进行主从库切换的。因此,通常我们至少会配置3个哨兵实例。这也是为啥哨兵集群部署成单数的原因,双数的话多余浪费。
通过 pub/sub 实现客户端事件通知
新 master 选出来了,要怎么公示天下呢?
当然是召开新闻发布会呀,邀请消息相关类型的媒体报道传播,感兴趣的人自然就去关注订阅相关事件,并根据事件做出行动。
在 Redis 也是类似,通过 pub/sub 机制发布不同事件,让客户端在这里订阅消息。客户端可以订阅哨兵的消息,哨兵提供的消息订阅频道有很多,不同频道包含了主从库切换过程中的不同关键事件。
也就是在不同的“微信群”发布不同的事件,让对该事件感兴趣的人进群即可。
- master 下线事件
+sdown:进入“主观下线”状态;
-sdown:退出“主观下线”状态;
+odown:进入“客观下线”状态;
-odown:退出“客观下线”状态;
- slave 重新配置事件
+slave-reconf-sent:哨兵发送 replicaof 命令重新配置从库;
+slave-reconf-inprog:slave 配置了新 master,但是尚未进行同步;
+slave-reconf-done:slave 配置了新 master,并与新 master 完成了数据同步;
- 新主库切换
+switch-master:master 地址发生了变化。
知道了这些频道之后,就可以让客户端从哨兵这里订阅消息了。客户端读取哨兵的配置文件后,可以获得哨兵的地址和端口,和哨兵建立网络连接。
然后,我们可以在客户端执行订阅命令,来获取不同的事件消息。
举个栗子:如下指令订阅“所有实例进入客观下线状态的事件”
SUBSCRIBE +odown |
注意事项与配置说明
发现了没,Redis 的 pub/sub 发布订阅机制尤其重要,有了 pub/sub 机制,哨兵和哨兵之间、哨兵和从库之间、哨兵和客户端之间就都能建立起连接了,各种事件的发布也是通过这个机制实现。
- down-after-milliseconds
Sentinel 配置文件中的 down-after-milliseconds 选项指定了 Sentinel 判断实例进入主观下线所需的时间长度:如果一个实例在 down-after-milliseconds 毫秒内,连续向 Sentinel 返回无效回复,那么 Sentinel 会修改这个实例所对应数据,以此来表示这个实例已经进入主观下线状态。
要保证所有哨兵实例的配置是一致的,尤其是主观下线的判断值 down-after-milliseconds。因为这个值在不同的哨兵实例上配置不一致,导致哨兵集群一直没有对有故障的主库形成共识,也就没有及时切换主库,最终的结果就是集群服务不稳定。
- down-after-milliseconds * 10
down-after-milliseconds 是我们认定主从库断连的最大连接超时时间。如果在 down-after-milliseconds 毫秒内,主从节点都没有通过网络联系上,我们就可以认为主从节点断连了。如果发生断连的次数超过了 10 次,就说明这个从库的网络状况不好,不适合作为新主库。
集群
为什么需要 Cluster
最近遇到一个糟心的问题,Redis 需要保存 800 万个键值对,占用 20 GB 的内存。
我就使用了一台 32G 的内存主机部署,但是 Redis 响应有时候非常慢,使用 INFO 命令查看 latest_fork_usec 指标(最近一次 fork 耗时),发现特别高。
主要是 Redis RDB 持久化机制导致的,Redis 会 Fork 子进程完成 RDB 持久化操作,fork 执行的耗时与 Redis 数据量成正相关。
而 Fork 执行的时候会阻塞主线程,由于数据量过大导致阻塞主线程过长,所以出现了 Redis 响应慢的表象。
随着业务规模的拓展,数据量越来越大。主从架构升级单个实例硬件难以拓展,且保存大数据量会导致响应慢问题,有什么办法可以解决么?
保存大量数据,除了使用大内存主机的方式,我们还可以使用切片集群。一台机器无法保存所有数据,那就多台分担。
使用 Redis Cluster 集群,主要解决了大数据量存储导致的各种慢问题,同时也便于横向拓展。
Redis 数据增多的两种拓展方案:
垂直扩展(scale up)、水平扩展(scale out)。
- 垂直拓展:
升级单个 Redis 的硬件配置,比如增加内存容量、磁盘容量、使用更强大的 CPU。- 水平拓展:
横向增加 Redis 实例个数,每个节点负责一部分数据。
比如需要一个内存 24 GB 磁盘 150 GB 的服务器资源,有以下两种方案: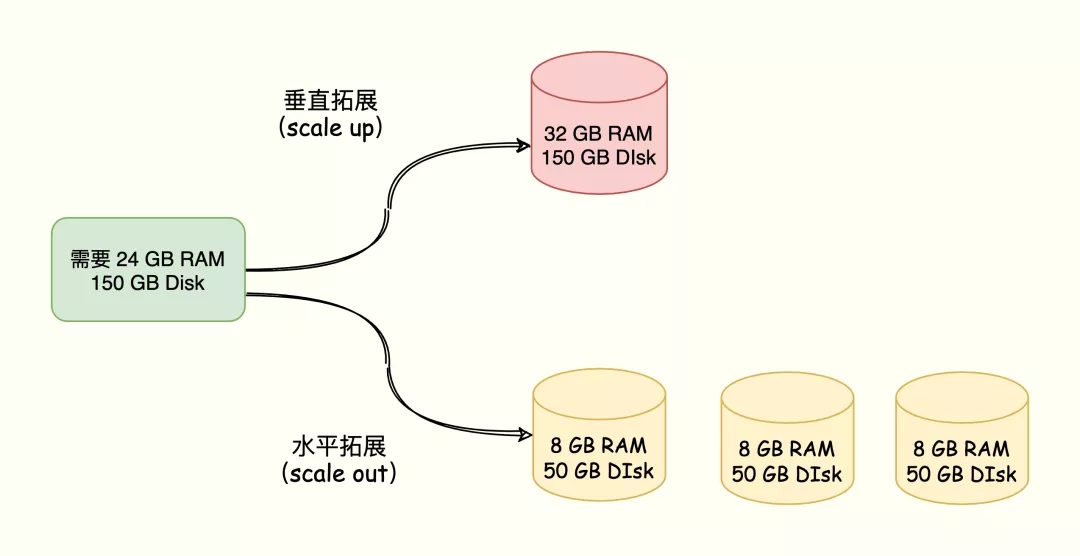
在面向百万、千万级别的用户规模时,横向扩展的 Redis 切片集群会是一个非常好的选择。
那这两种方案都有什么优缺点呢?
垂直拓展部署简单,但是当数据量大并且使用 RDB 实现持久化,会造成阻塞导致响应慢。另外受限于硬件和成本,拓展内存的成本太大,比如拓展到 1T 内存。水平拓展便于拓展,同时不需要担心单个实例的硬件和成本的限制。但是,切片集群会涉及多个实例的分布式管理问题,需要解决如何将数据合理分布到不同实例,同时还要让客户端能正确访问到实例上的数据。
什么是 Cluster 集群
Redis 集群是一种分布式数据库方案,集群通过分片(sharding)来进行数据管理,并提供复制和故障转移功能。
将数据划分为16384的 slots,每个节点负责一部分槽位。槽位的信息存储于每个节点中。
它是去中心化的,如图所示,该集群有三个 Redis 节点组成,每个节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样。
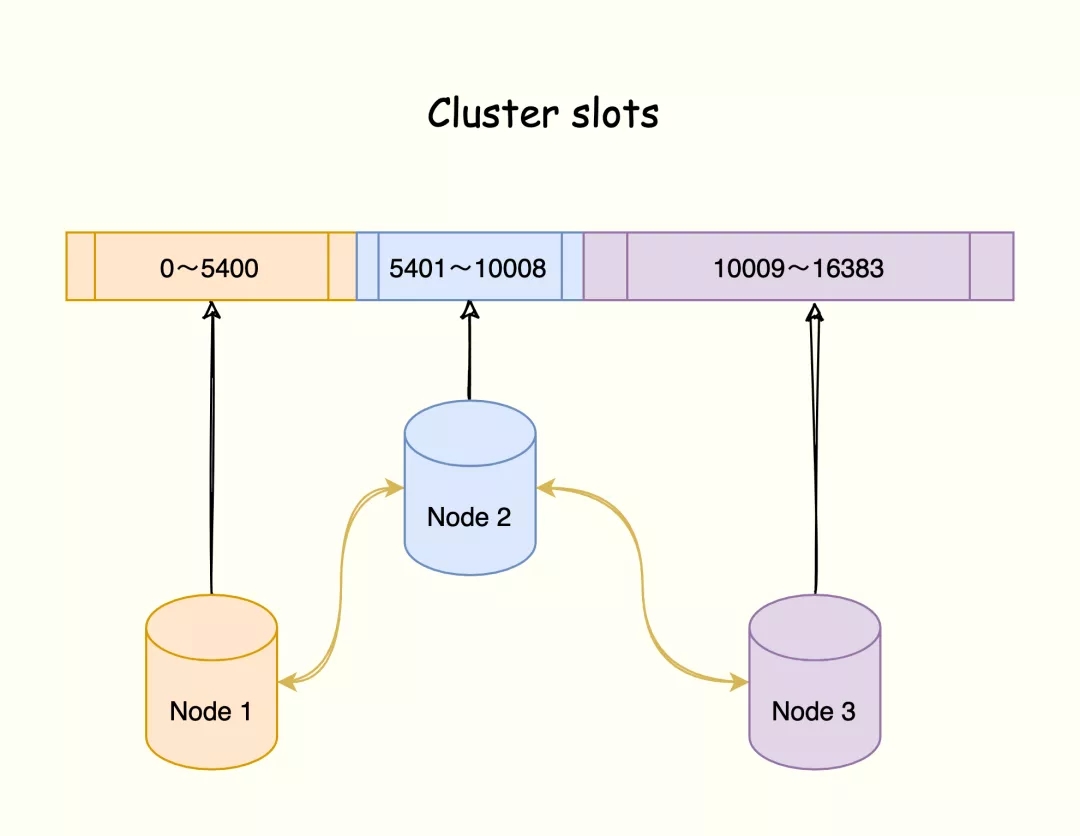
三个节点相互连接组成一个对等的集群,它们之间通过 Gossip协议相互交互集群信息,最后每个节点都保存着其他节点的 slots 分配情况。
Gossip 的中文意思就是流言蜚语,该协议就像流言蜚语一样,利用一种随机、带有传染性的方式,将信息传播到整个网络中,并在一定时间内,使得系统内的所有节点数据一致。这个就是实现了最终一致性的协议。
节点间的握手
一个 Redis 集群通常由多个节点(node)组成,在刚开始的时候,每个节点都是相互独立的,它们都处于一个只包含自己的集群当中,要组建一个真正可工作的集群,我们必须将各个独立的节点连接起来,构成一个包含多个节点的集群。
连接各个节点的工作可以通过CLUSTER MEET命令完成:
CLUSTER MEET <ip> <port> 。 |
向一个节点 node 发送 CLUSTER MEET 命令,可以让 node 节点与 ip 和 port 所指定的节点进行握手(handshake),当握手成功时,node 节点就会将 ip 和 port 所指定的节点添加到 node 节点当前所在的集群中。
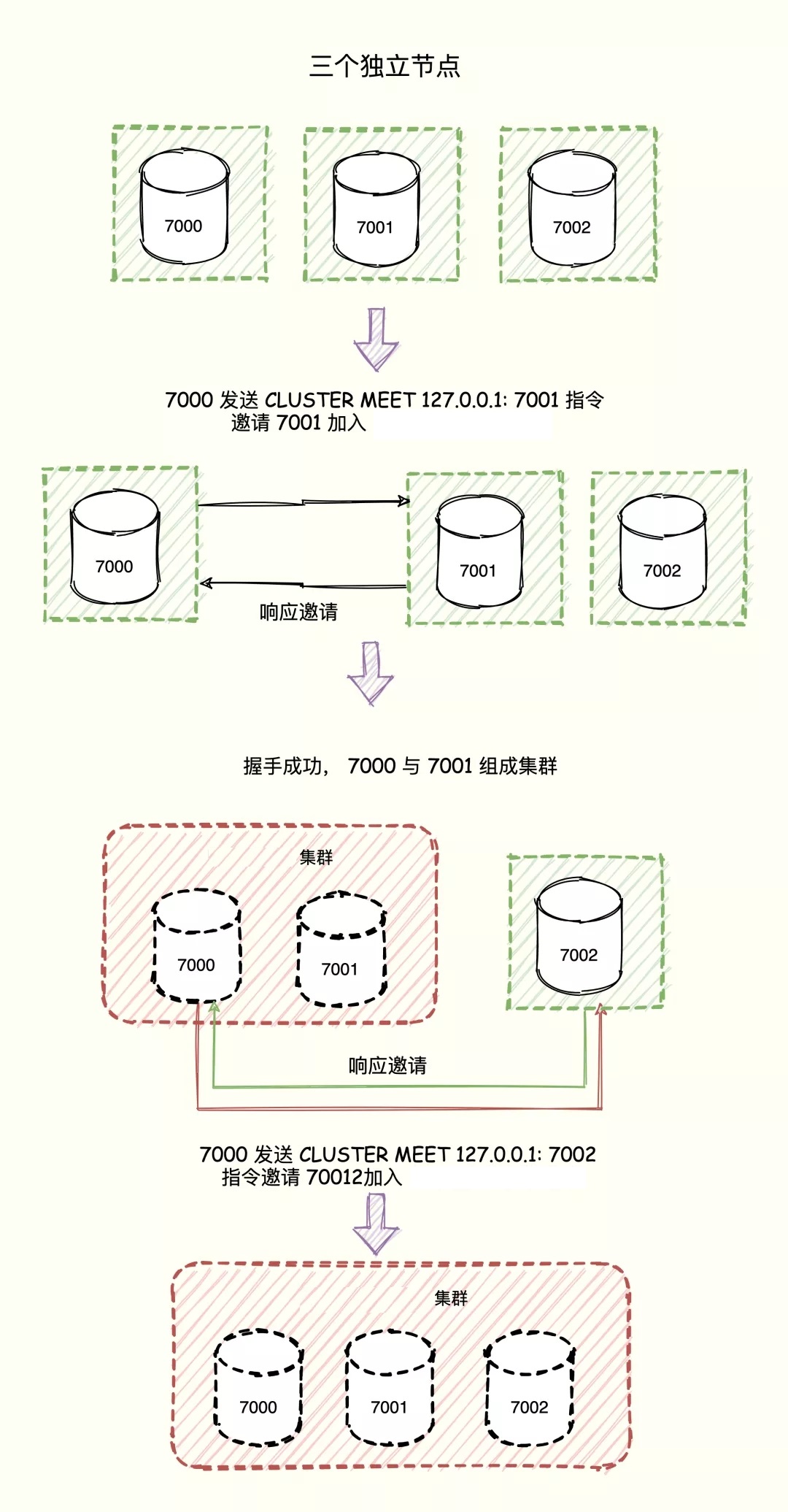
实现原理
数据切片后,需要将数据分布在不同实例上,数据和实例之间如何对应上呢?
Redis 3.0 开始,官方提供了 Redis Cluster 方案实现了切片集群,该方案就实现了数据和实例的规则。Redis Cluster 方案采用哈希槽(Hash Slot),来处理数据和实例之间的映射关系。
将数据分成多份存在不同实例上
集群的整个数据库被分为 16384 个槽(slot),数据库中的每个键都属于这 16384 个槽的其中一个,集群中的每个节点可以处理 0 个或最多 16384 个槽。
Key 与哈希槽映射过程可以分为两大步骤:
- 根据键值对的 key,使用 CRC16 算法,计算出一个 16 bit 的值;
- 将 16 bit 的值对 16384 执行取模,得到 0 ~ 16383 的数表示 key 对应的哈希槽。
Cluster 还允许用户强制某个 key 挂在特定槽位上,通过在 key 字符串里面嵌入 tag 标记,这就可以强制 key 所挂在的槽位等于 tag 所在的槽位。
哈希槽与 Redis 实例映射
哈希槽又是如何映射到 Redis 实例上呢?
在 部署集群的样例中通过 cluster create 创建,Redis 会自动将 16384 个 哈希槽平均分布在集群实例上,比如 N 个节点,每个节点上的哈希槽数 = 16384 / N 个。
除此之外,可以通过 CLUSTER MEET 命令将 7000、7001、7002 三个节点连在一个集群,但是集群目前依然处于下线状态,因为三个实例都没有处理任何哈希槽。
可以使用 cluster addslots 命令,指定每个实例上的哈希槽个数。
为啥要手动制定呢?
能者多劳嘛,加入集群中的 Redis 实例配置不一样,如果承担一样的压力,对于垃圾机器来说就太难了,让牛逼的机器多支持一点。
三个实例的集群,通过下面的指令为每个实例分配哈希槽:实例 1负责 0 ~ 5460 哈希槽,实例 2 负责 5461~10922 哈希槽,实例 3 负责 10923 ~ 16383 哈希槽。
redis-cli -h 172.16.19.1 –p 6379 cluster addslots 0,5460 |
键值对数据、哈希槽、Redis 实例之间的映射关系如下:
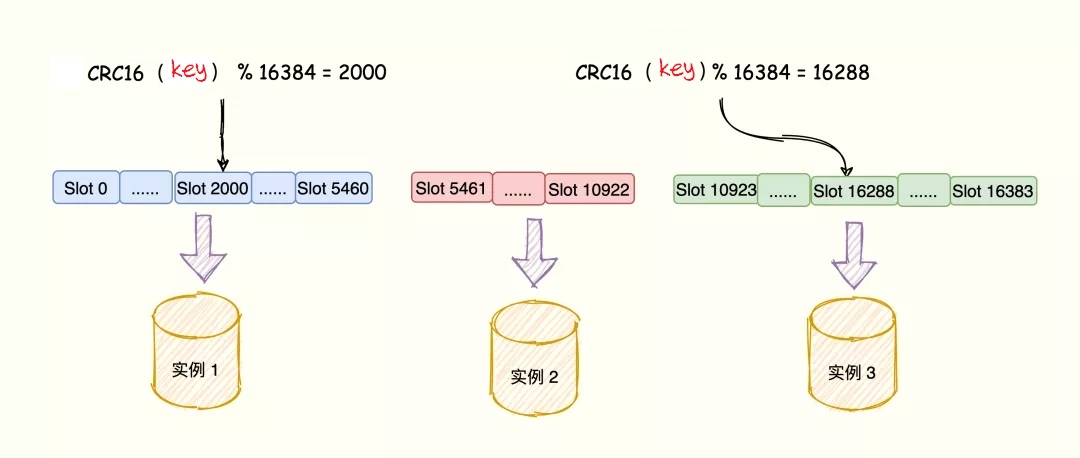
Redis 键值对的 key 经过 CRC16 计算后再对哈希槽总个数 16384 取模,模数结果分别映射到实例 1 与实例 3 上。
注:
当 16384 个槽都分配完全,Redis 集群才能正常工作。
复制与故障转移
Redis 集群如何实现高可用呢?Master 与 Slave 还是读写分离么?
Master 用于处理槽,Slave节点则通过主从复制方式同步主节点数据。
当 Master 下线,Slave 代替主节点继续处理请求。主从节点之间并没有读写分离, Slave 只用作 Master 宕机的高可用备份。
Redis Cluster 可以为每个主节点设置若干个从节点,单主节点故障时,集群会自动将其中某个从节点提升为主节点。
如果某个主节点没有从节点,那么当它发生故障时,集群将完全处于不可用状态。
不过 Redis 也提供了一个参数cluster-require-full-coverage可以允许部分节点故障,其它节点还可以继续提供对外访问。
比如 7000 主节点宕机,作为 slave 的 7003 成为 Master 节点继续提供服务。当下线的节点 7000 重新上线,它将成为当前 70003 的从节点。
故障检测
哨兵通过监控、自动切换主库、通知客户端实现故障自动切换,Cluster 又如何实现故障自动转移呢?
一个节点认为某个节点失联了并不代表所有的节点都认为它失联了。只有当大多数负责处理 slot 节点都认定了某个节点下线了,集群才认为该节点需要进行主从切换。
Redis 集群节点采用 Gossip 协议来广播自己的状态以及自己对整个集群认知的改变。比如一个节点发现某个节点失联了 (PFail),它会将这条信息向整个集群广播,其它节点也就可以收到这点失联信息。
如果一个节点收到了某个节点失联的数量 (PFail Count) 已经达到了集群的大多数,就可以标记该节点为确定下线状态 (Fail),然后向整个集群广播,强迫其它节点也接收该节点已经下线的事实,并立即对该失联节点进行主从切换。
故障转移
当一个 Slave 发现自己的主节点进入已下线状态后,从节点将开始对下线的主节点进行故障转移。
- 从下线的 Master 及节点的 Slave 节点列表选择一个节点成为新主节点。
- 新主节点会撤销所有对已下线主节点的 slot 指派,并将这些 slots 指派给自己。
- 新的主节点向集群广播一条PONG消息,这条PONG消息可以让集群中的其他节点立即知道这个节点已经由从节点变成了主节点,并且这个主节点已经接管了原本由已下线节点负责处理的槽。
- 新的主节点开始接收处理槽有关的命令请求,故障转移完成。
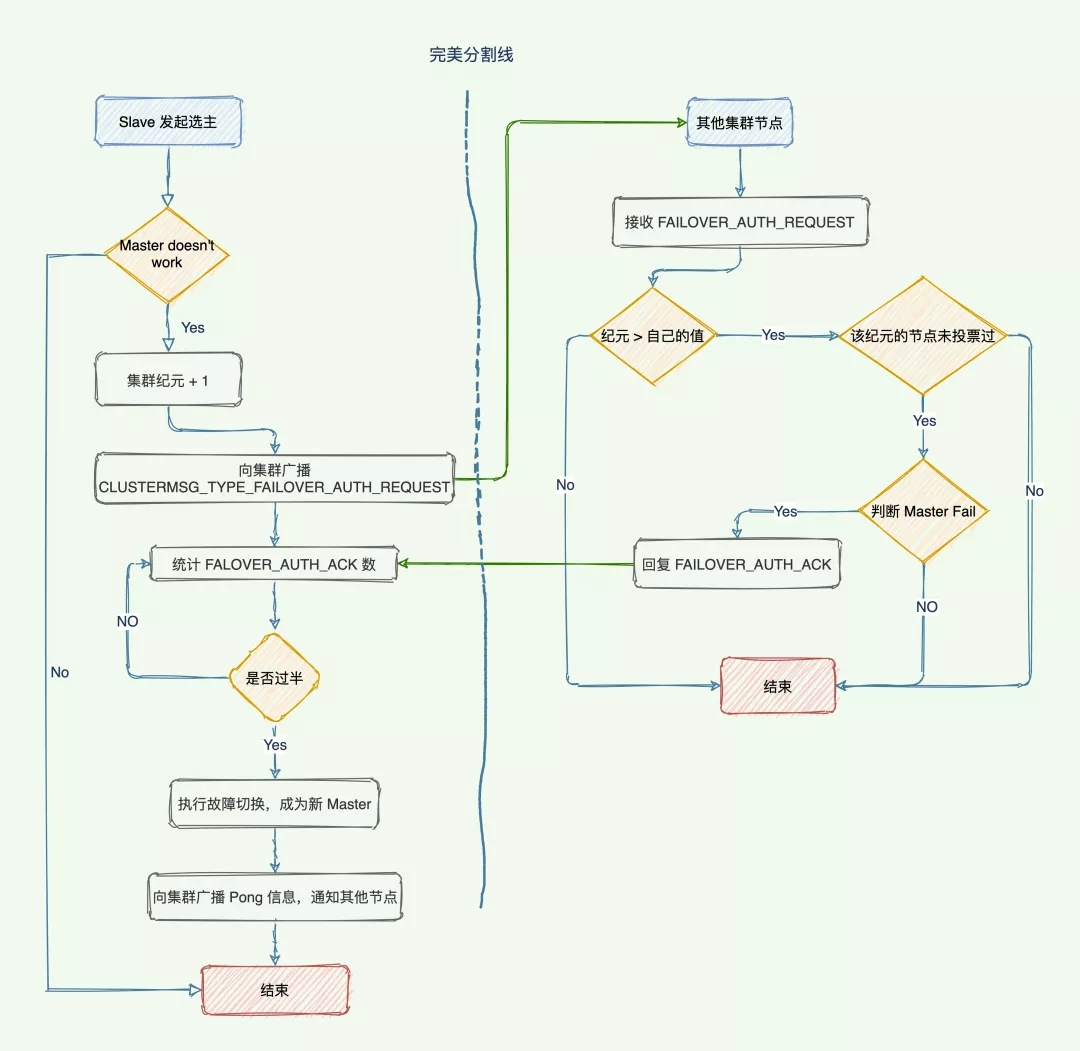
选主流程
新的主节点如何选举产生的?
- 集群的配置纪元 +1,是一个自曾计数器,初始值0,每次执行故障转移都会 +1。
- 检测到主节点下线的从节点向集群广播一条
CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息,要求所有收到这条消息、并且具有投票权的主节点向这个从节点投票。 - 这个主节点尚未投票给其他从节点,那么主节点将向要求投票的从节点返回一条
CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,表示这个主节点支持从节点成为新的主节点。 - 参与选举的从节点都会接收
CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,如果收集到的票 >= (N/2) + 1支持,那么这个从节点就被选举为新主节点。 - 如果在一个配置纪元里面没有从节点能收集到足够多的支持票,那么集群进入一个新的配置纪元,并再次进行选举,直到选出新的主节点为止。
跟哨兵类似,两者都是基于 Raft 算法来实现的,流程如图所示:
用表保存键值对和实例的关联关系可行么
Redis Cluster 方案通过哈希槽的方式把键值对分配到不同的实例上,这个过程需要对键值对的 key 做 CRC 计算并对 哈希槽总数取模映射到实例上。如果用一个表直接把键值对和实例的对应关系记录下来(例如键值对 1 在实例 2 上,键值对 2 在实例 1 上),这样就不用计算 key 和哈希槽的对应关系了,只用查表就行了,Redis 为什么不这么做呢?
使用一个全局表记录的话,假如键值对和实例之间的关系改变(重新分片、实例增减),需要修改表。如果是单线程操作,所有操作都要串行,性能太慢。
多线程的话,就涉及到加锁,另外,如果键值对数据量非常大,保存键值对与实例关系的表数据所需要的存储空间也会很大。
而哈希槽计算,虽然也要记录哈希槽与实例时间的关系,但是哈希槽的数量少得多,只有 16384 个,开销很小。
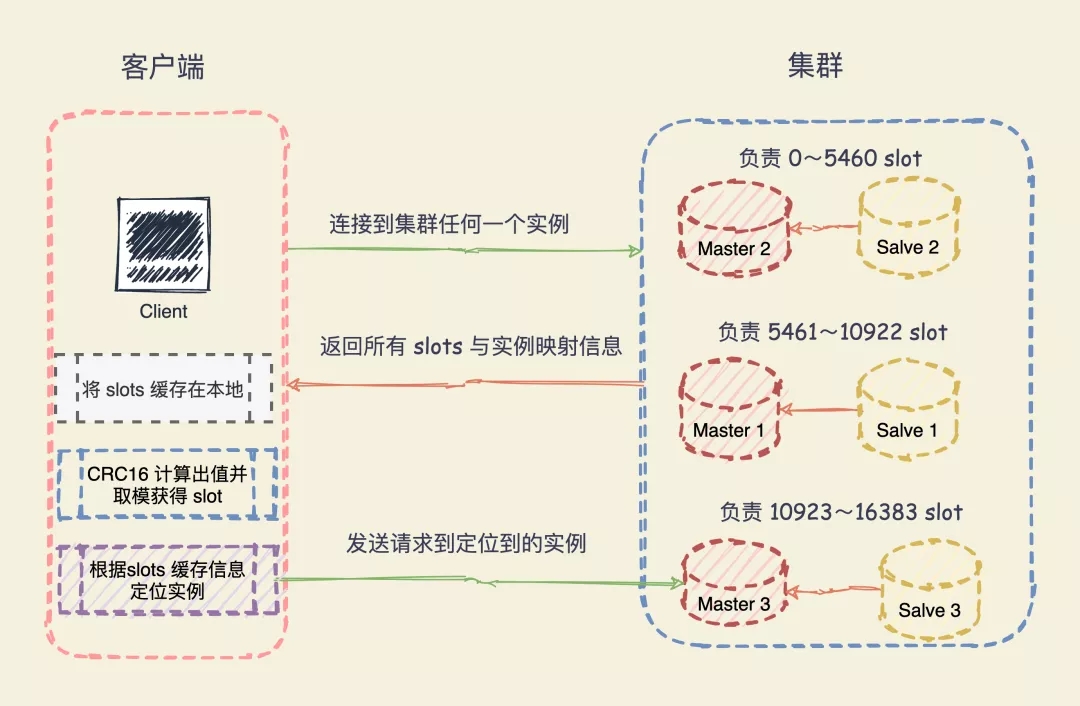
客户端如何定位数据所在实例
Redis 实例会将自己的哈希槽信息通过 Gossip 协议发送给集群中其他的实例,实现了哈希槽分配信息的扩散。
这样,集群中的每个实例都有所有哈希槽与实例之间的映射关系信息。
在切片数据的时候是将 key 通过 CRC16 计算出一个值再对 16384 取模得到对应的 Slot,这个计算任务可以在客户端上执行发送请求的时候执行。
但是,定位到槽以后还需要进一步定位到该 Slot 所在 Redis 实例。
当客户端连接任何一个实例,实例就将哈希槽与实例的映射关系响应给客户端,客户端就会将哈希槽与实例映射信息缓存在本地`。
当客户端请求时,会计算出键所对应的哈希槽,在通过本地缓存的哈希槽实例映射信息定位到数据所在实例上,再将请求发送给对应的实例。
重新分配哈希槽
哈希槽与实例之间的映射关系由于新增实例或者负载均衡重新分配导致改变了咋办?
集群中的实例通过 Gossip 协议互相传递消息获取最新的哈希槽分配信息,但是,客户端无法感知。
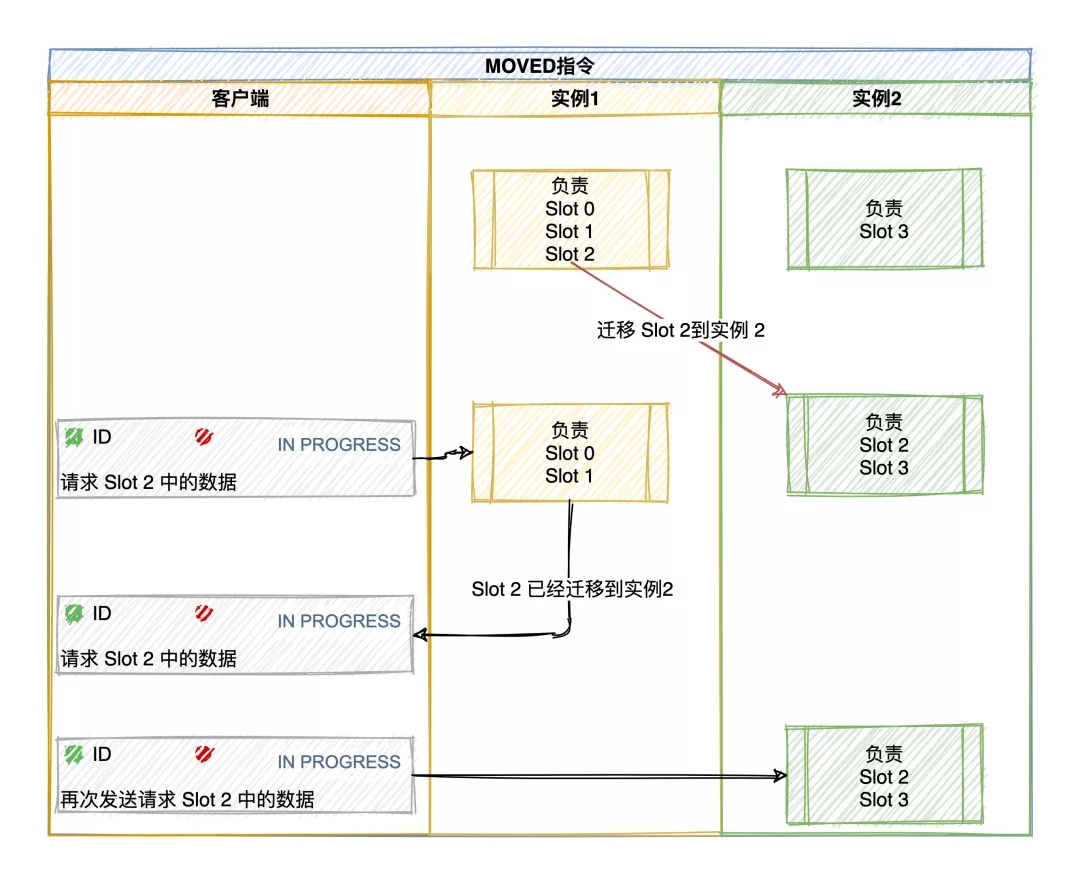
Redis Cluster 提供了重定向机制:客户端将请求发送到实例上,这个实例没有相应的数据,该 Redis 实例会告诉客户端将请求发送到其他的实例上。
Redis 如何告知客户端重定向访问新实例呢?
分为两种情况:MOVED 错误、ASK 错误。
MOVED 错误
MOVED 错误(负载均衡,数据已经迁移到其他实例上):当客户端将一个键值对操作请求发送给某个实例,而这个键所在的槽并非由自己负责的时候,该实例会返回一个 MOVED 错误指引转向正在负责该槽的节点。
GET key:value |
该响应表示客户端请求的键值对所在的哈希槽 16330 迁移到了 172.17.18.2 这个实例上,端口是 6379。这样客户端就与 172.17.18.2:6379 建立连接,并发送 GET 请求。
同时,客户端还会更新本地缓存,将该 slot 与 Redis 实例对应关系更新正确。
ASK 错误
如果某个 slot 的数据比较多,部分迁移到新实例,还有一部分没有迁移咋办?
如果请求的 key 在当前节点找到就直接执行命令,否则就需要 ASK 错误响应了,槽部分迁移未完成的情况下,如果需要访问的 key 所在 Slot 正在从从 实例 1 迁移到 实例 2,实例 1 会返回客户端一条 ASK 报错信息:客户端请求的 key 所在的哈希槽正在迁移到实例 2 上,你先给实例 2 发送一个 ASKING 命令,接着发送操作命令。
GET key:value |
比如客户端请求定位到 key = value 的槽 16330 在实例 172.17.18.1 上,节点 1 如果找得到就直接执行命令,否则响应 ASK 错误信息,并指引客户端转向正在迁移的目标节点 172.17.18.2。
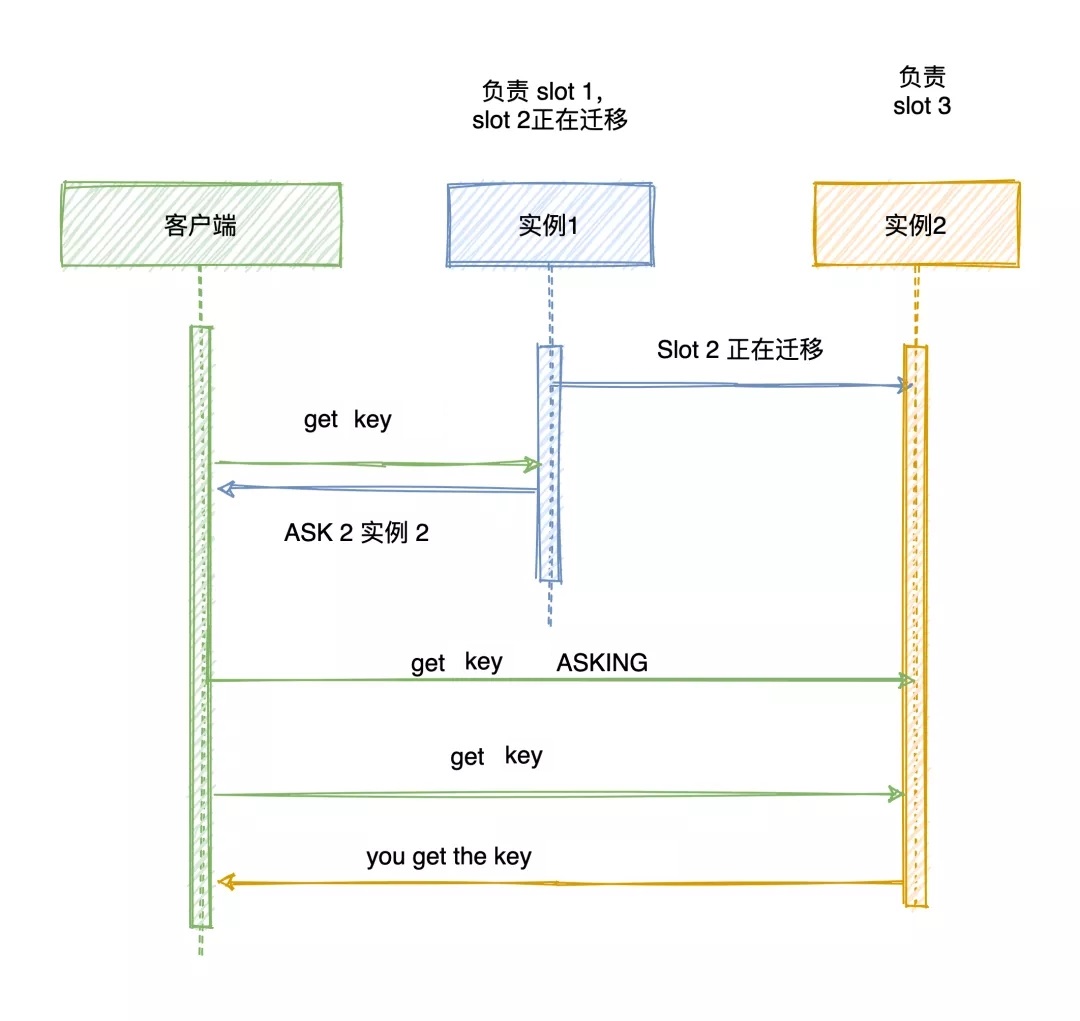
注:ASK 错误指令并不会更新客户端缓存的哈希槽分配信息。
所以客户端再次请求 Slot 16330 的数据,还是会先给 172.17.18.1 实例发送请求,只不过节点会响应 ASK 命令让客户端给新实例发送一次请求。
MOVED指令则更新客户端本地缓存,让后续指令都发往新实例。
集群可以设置多大
有了 Redis Cluster,再也不怕大数据量了,我可以无限水平拓展么?
答案是否定的,Redis 官方给的 Redis Cluster 的规模上线是 1000 个实例。
到底是什么限制了集群规模呢?
关键在于实例间的通信开销,Cluster 集群中的每个实例都保存所有哈希槽与实例对应关系信息(Slot 映射到节点的表),以及自身的状态信息。
在集群之间每个实例通过 Gossip协议传播节点的数据,Gossip 协议工作原理大概如下:
从集群中随机选择一些实例按照一定的频率发送 PING 消息发送给挑选(随机)出来的实例,用于检测实例状态以及交换彼此的信息。PING 消息中封装了发送者自身的状态信息、部分其他实例的状态信息、Slot 与实例映射表信息。- 实例接收到 PING 消息后,响应 PONG 消息,消息包含的信息跟 PING 消息一样。
集群之间通过Gossip协议可以在一段时间之后每个实例都能获取其他所有实例的状态信息。
所以在有新节点加入,节点故障,Slot 映射变更都可以通过 PING,PONG 的消息传播完成集群状态在每个实例的传播同步。
Gossip 消息
发送的消息结构是clusterMsgDataGossip结构体组成:
typedef struct { |
所以每个实例发送一个 Gossip消息,就需要发送 104 字节。如果集群是 1000 个实例,那么每个实例发送一个 PING 消息则会占用 大约 10KB。
除此之外,实例间在传播 Slot 映射表的时候,每个消息还包含了 一个长度为 16384 bit 的 Bitmap。
每一位对应一个 Slot,如果值 = 1 则表示这个 Slot 属于当前实例,这个 Bitmap 占用 2KB,所以一个 PING 消息大约 12KB。
PONG与PING 消息一样,一发一回两个消息加起来就是 24 KB。集群规模的增加,心跳消息越来越多就会占据集群的网络通信带宽,降低了集群吞吐量。
实例的通信频率
发送 PING 消息的频率也会影响集群带宽吧?
Redis Cluster 的实例启动后,默认会每秒从本地的实例列表中随机选出 5 个实例,再从这 5 个实例中找出一个最久没有收到 PING 消息的实例,把 PING 消息发送给该实例。
随机选择 5 个,但是无法保证选中的是整个集群最久没有收到 PING 通信的实例,有的实例可能一直没有收到消息,导致他们维护的集群信息早就过期了,咋办呢?
Redis Cluster 的实例每 100 ms 就会扫描本地实例列表,当发现有实例最近一次收到 PONG 消息的时间 > cluster-node-timeout / 2。那么就立刻给这个实例发送 PING 消息,更新这个节点的集群状态信息。
当集群规模变大,就会进一步导致实例间网络通信延迟增加。可能会引起更多的 PING 消息频繁发送。
- 降低实例间的通信开销
- 每个实例每秒发送一条 PING消息,降低这个频率可能会导致集群每个实例的状态信息无法及时传播。
每 100 ms 检测实例 PONG消息接收是否超过 cluster-node-timeout / 2,这个是 Redis 实例默认的周期性检测任务频率,我们不会轻易修改。
所以,只能修改 cluster-node-timeout的值:集群中判断实例是否故障的心跳时间,默认 15 S。
所以,为了避免过多的心跳消息占用集群宽带,将 cluster-node-timeout调成 20 秒或者 30 秒,这样 PONG 消息接收超时的情况就会缓解。
但是,也不能设置的太大,太大就会导致实例发生故障,却要等待 cluster-node-timeout时长才能检测出这个故障,影响集群正常服务。
基础命令
在Resid安装目录下,使用redis-cli客户端连接Redis数据库
远程连接
redis-cli -h [ip] -p [host] -a [密码] |
keys pattern
获取所有与pattern匹配的key,返回所有与该key匹配的keys。Patterm参数解析:

127.0.0.1:6379> keys * |
del key1 key2…
删除一个或多个指定的key,返回值是删除key的个数
127.0.0.1:6379> del company |
exists key
判断该key是否存在,1代表存在,0代表不存在
127.0.0.1:6379> exists compnay |
type key
获取指定key的类型。该命令将以字符串的格式返回。 返回的字符串为string、list、set、hash,如果key不存在返回none
127.0.0.1:6379> type company |
select
一个Redis服务器可以包括多个数据库,客户端可以指定连接Redis中的哪个数据库,就好比一个mysql服务器中创建多个数据库,客户端连接时指定连接到哪个数据库。一个Redis实例最多可提供16个数据库,下标为0到15,客户端默认连接第0个数据库,也可以通过select命令选择哪个数据库。
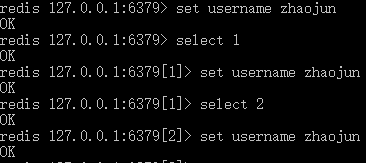
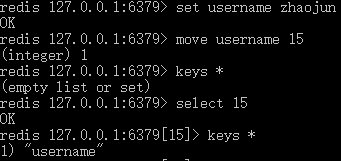
move
将key移到其他数据库;move key 15 : 将当前数据库中的key移到15号数据库中
info
获取 redis 服务器的统计信息
127.0.0.1:6379> info |
Help
HELP命令可以查看redis的一些命令的用法;当忘记某个命令的使用时很有用。
Redis的数据类型
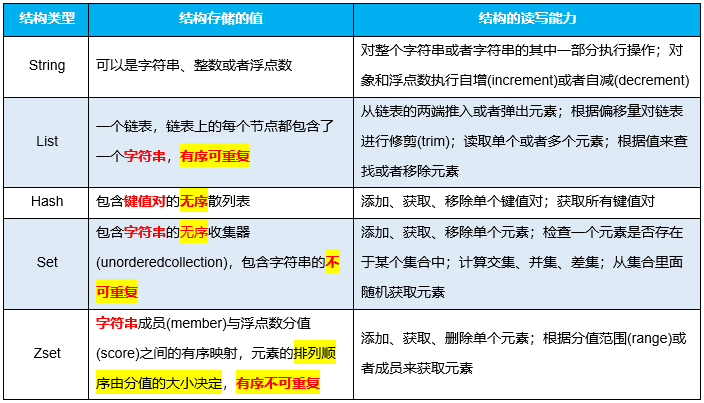
Redis的5种基本类型
redis是一种高级的key-value的存储系统,其中value支持五种数据类型:
- 字符串(String)
- 哈希(hash)
- 字符串列表(list)
- 字符串集合(set)
- 有序字符串集合(sorted ZSet)
在日常开发中主要使用比较多的有字符串、哈希、字符串列表、字符串集合四种类型,其中最为常用的是字符串类型。
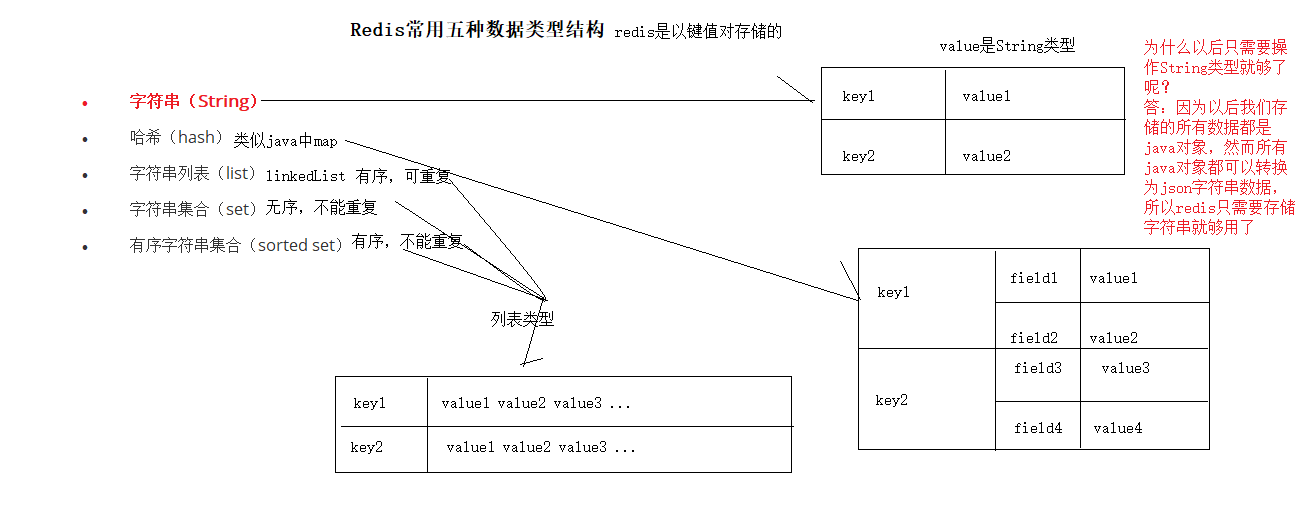
关于key的定义,注意如下几点:
- key不要太长,最好不要超过1024个字节,这不仅会消耗内存还会降低查找效率
- key不要太短,如果太短会降低key的可读性
- 在项目中,key最好有一个统一的命名规范(见名知意)
String(字符串)
概述
字符串类型是Redis中最为基础的数据存储类型,它在Redis中是二进制安全的,这便意味着字符串类型存入和获取的数据相同。在Redis中字符串类型的Value最多可以容纳的数据长度是512M。
常用命令
- set key value
设定key的value。指定字符串的value,如果该key存在则进行覆盖操作。总是返回”OK”
127.0.0.1:6379> set company "itcast" |
- get key
获取key的value。如果与该key关联的value不是String类型,redis将返回错误信息,因为get命令只能用于获取String value;如果该key不存在,返回(nil)。
127.0.0.1:6379> set name "itcast" |
- del key
删除指定key,返回影响的记录数
127.0.0.1:6379> del name |
Hash(哈希类型)
概述
Redis中的Hash类型可看成具有String Key和String Value的map容器。所以Hash类型非常适合于存储键值对的信息。如Username、Password和Age等。如果Hash中包含很少的字段,那么该类型的数据也将仅占用很少的内存空间。每一个Hash可以存储4294967295个键值对。
常用命令
- hset key field value
为指定的key设定field/value对(键值对)。返回影响的记录数
127.0.0.1:6379> hset myhash username haohao |
- hget key field
获取指定的key中的field的值
127.0.0.1:6379> hset myhash username haohao |
- hmset key field value [field1 value1 field2 value2…]
设置key中的多个filed/value
127.0.0.1:6379> hmset myhash username jack age 21 |
- hmget key fileds
获取key中的多个filed的值
127.0.0.1:6379> hmget myhash username age |
- hgetall key
获取key中所有map的key和value
127.0.0.1:6379> hset h_user id 1 |
- hdel key field [field … ]
可以删除一个或多个字段,返回值是被删除的字段个数
127.0.0.1:6379> hdel myhash username age |
- HEXISTS key field
查看哈希表 key 中,判断域field 是否存在
127.0.0.1:6379> hexists myhash name |
- HKEYS key和HVALS key
HKEYS key:获取哈希表Key的所有域field;HVALS key:获取哈希表key的所有域field对应的值
127.0.0.1:6379> hkeys h_user |
- HLEN key
返回哈希表 key 中域field的数量
127.0.0.1:6379> hlen h_user |
List(列表类型)
概述
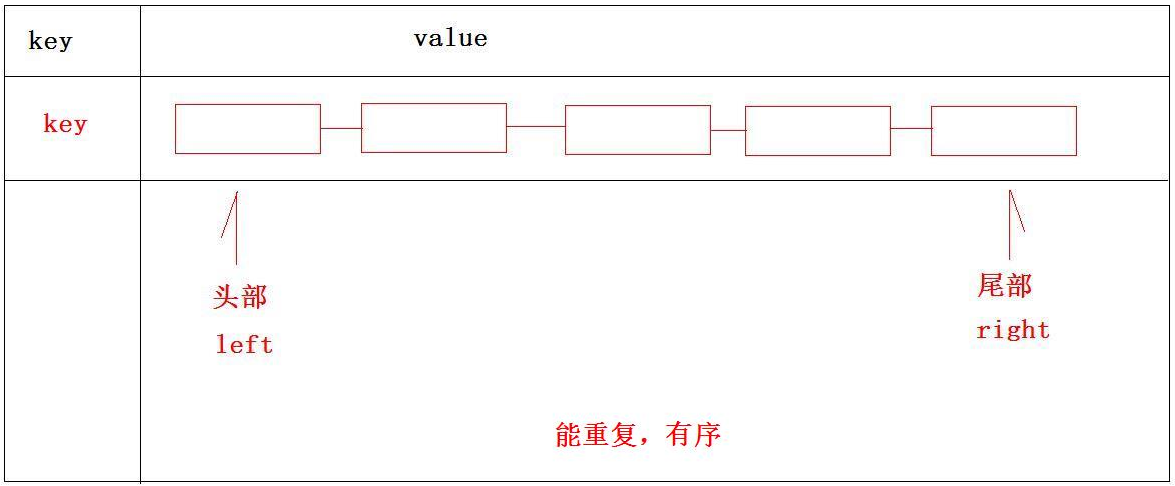
在Redis中,List类型是按照插入顺序排序的字符串链表(java中的linkedlist)。和数据结构中的普通链表一样,可以在其头部(left)和尾部(right)添加新的元素。在插入时,如果该键并不存在,Redis将为该键创建一个新的链表。与此相反,如果链表中所有的元素均被移除,那么该键也将会被从数据库中删除。List中可以包含的最大元素数量是4294967295,list类型允许有重复元素
常用命令
- lpush key value1 value2 …
如果该key不存在,该命令在插入的之前创建一个与该key关联的空链表,之后再向该链表的头部插入数据。插入成功,返回元素的个数。
127.0.0.1:6379> lpush mylist a b c |
注意:是左边添加,所以最终最左边的元素为c
- rpush key value1 value2 …
如果该key不存在,该命令在插入之前创建一个与该key对应的空链表,再从尾部插入数据。插入成功,返回元素的个数。
127.0.0.1:6379> rpush l_users d e |
注意:是右边添加,所以最终最右边的元素为e
- lrange key start end
获取链表中从start到end的元素的值,索引从0开始,如果为负数,-1表示倒数第一个元素,-2表示倒数第二个元素,以此类推。
127.0.0.1:6379> lrange l_users 0 -1 |
- lpop key,
从头部移除元素
返回并弹出指定的key关联的链表中的第一个元素,即头部元素。如果该key不存在,返回nil;若key存在,则返回链表的头部元素。
127.0.0.1:6379> lpush mylist a b c |
- rpop key,
从尾部移除元素
返回并弹出指定的key关联的链表中的最后一个元素,即尾部元素。如果该key不存在,返回nil;若key存在,则返回链表的尾部元素。
127.0.0.1:6379> lpush mylist a b c |
- LLEN key
返回指定key对应链表中元素的个数
127.0.0.1:6379> lrange l_users 0 -1 |
- LREM key count value
LREM命令会删除列表中前count个值为value的元素,返回实际删除的元素个数。根据count值的不同,该命令的执行方式会有所不同:
- 当
count>0时, LREM会从列表左边(头部)开始删除。- 当
count<0时, LREM会从列表后边(尾部)开始删除。- 当
count=0时, LREM删除所有值为value的元素。
127.0.0.1:6379> lpush l_users 1 2 3 |
删除列表l_users中2个值为3的元素
127.0.0.1:6379> lrem l_users 2 3 |
- LINDEX key index
获得指定索引的元素值
127.0.0.1:6379> lindex l_users 3 |
Set(无序集合)
概述
在Redis中,将Set类型看作为没有排序的字符集合,和List类型一样,也可以在该类型的数据值上执行添加、删除或判断某一元素是否存在等操作。set集合类型可包含的最大元素数量是4294967295,和List类型不同的是,set集合类型中不允许出现重复的元素,且无序。
常用命令
- sadd key values[value1 value2 …]
向set中无序添加一个或多个数据,如果该key的值已存在则不会重复添加
127.0.0.1:6379> sadd myset a b c |
- smembers key
获取set中所有的成员
127.0.0.1:6379> smembers myset |
- srem key members[member1、member2…]
删除set中指定的成员
127.0.0.1:6379> srem myset a b |
- SISMEMBER key member
判断元素是否存在集合中
127.0.0.1:6379> sismember myset c |
- SCARD key
获得集合中元素的个数
127.0.0.1:6379> scard myset |
Sorted ZSet(有序集合)
概述
在集合类型的基础上有序集合类型(sorted ZSet)为集合中的每个元素都关联一个分数,这使得我们不仅可以完成插入、删除和判断元素是否存在在集合中,还能够获得分数最高或最低的前N个元素、获取指定分数范围内的元素等与分数有关的操作。
有序集合和列表类型区别
- 相同点:
- 二者都是有序的。
- 二者都可以获得某一范围的元素。
- 不同点:
列表类型是通过链表实现的,获取靠近两端的数据速度极快,而当元素增多后,访问中间数据的速度会变慢。有序集合类型使用散列表实现,所以即使读取位于中间部分的数据也很快。- 列表中不能简单的
调整某个元素的位置,但是有序集合可以(通过更改分数实现)- 有序集合要比列表类型
更耗内存。
常用命令
增加元素:ZADD key score member [score member …]
向有序集合中加入一个元素和该元素的分数,如果该元素已经存在则会用新的分数替换原有的分数。返回值是新加入到集合中的元素个数,不包含之前已经存在的元素。
127.0.0.1:6379> zadd z_users 10 a 20 b 30 c |
获取指定区间元素:ZRANGE key start stop [WITHSCORES]
返回有序集合key 中,指定区间内的成员。其中成员的位置按 score 值递增 (从小到大) 来排序。start开始位置,stop结束位置(-1则为最后一个元素)
127.0.0.1:6379> zrange z_users 0 -1 |
- 按照
排名范围删除元素:ZREMRANGEBYRANK key start stop
删除排名(按分数排)范围在第3的元素
127.0.0.1:6379> zremrangebyrank z_users 2 2 |
- 按照
分数范围删除元素:ZREMRANGEBYSCORE key min max
删除分数范围为5-10(包括端点值5和10)的元素
127.0.0.1:6379> zremrangebyscore z_users 5 10 |
总结
Redis新的4种数据类型
Bitmaps(位操作字符串)
简介
现代计算机使用二进制(位)作为信息的基本单位,1个字节等于8位,例如“abc”字符串是有3个字节组成,但实际在计算机内存储时将其使用二进制表示,“abc”分别对应的ASCII码是:97、98、99,对应的二进制分别是01100001、01100010、01100011,如下图

合理地使用位操作能够有效地提高内存使用率和开发效率
- Redis提供了Bitmaps这个“数据类型”可以实现对位的操作:
Bitmaps本身不是一种数据类型,实际上它就是字符串(key-value),但是它可以对字符串的位进行操作,字符串中每个字符对应1个字节,也就是8位,一个字符可以存储8个bit位信息。- Bitmaps单独提供了一套命令, 所以在Redis中使用Bitmaps和使用字符串的方法不太相同。 可以把
Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。

常用命令
setbit:设置某个偏移量的值(0或1)
SETBIT key offset value |
- 设置offset偏移位的值为value,o
ffset的值是从0开始的,n代表第n+1个bit位置的。offset 参数必须大于或等于 0,小于 2^32(bit 映射被限制在 512 MB 之内)。- value的值只能为0或1
- 返回值:指定
偏移量原来储存的位。
redis> SETBIT bit 10086 1 |
如:每个独立用户是否访问过网站存放在bitmaps中,将访问的用户记做1,没有访问的用户记做0,用户id作为offset。现在有20个用户,userid=1,6,11,15,19的用户对网站进行了访问,那么当前bitmaps初始化结果如图

users:20220409这个bitmaps中表示2022-04-09这天独立访问的用户,如下
127.0.0.1:6379> setbit users:20220409 1 1 |
getbit:获取某个偏移位的值
GETBIT key offset |
获取key所对应的bitmaps中offset偏移位的值。- 返回值:0或者1
127.0.0.1:6379> flushdb #清空db,方便测试 |
bitcount:统计bit位都为1的数量
BITCOUNT key [start] [end] |
统计字符串被设置为1的bit数,一般情况下,给定的整个字符串都会被进行统计,通过指定额外的start或者end参数,可以让计数只在特定的位上进行,
start 和 end 参数,都可以使用负数值(比如 -1 表示最后一个位,而 -2 表示倒数第二个位,以此类推)。注:start、end是指bit组的字节的下标数,一个直接对应8个bit,所以[a,b]对应的offset范围是[8a,8b+7]
127.0.0.1:6379> flushdb # 清空db,方便测试 |
bittop:对一个多个bitmaps执行位操作
BITOP operation destkey key [key ...] |
- 对一个或多个保存二进制位的字符串 key 进行位元操作,并
将结果保存到 destkey 上。operation可以是AND 、 OR 、 NOT 、 XOR这四种操作中的任意一种:
BITOP AND destkey key [key ...],对一个或多个 key 求逻辑并,并将结果保存到 destkey 。BITOP OR destkey key [key ...],对一个或多个 key 求逻辑或,并将结果保存到 destkey 。BITOP XOR destkey key [key ...],对一个或多个 key 求逻辑异或,并将结果保存到 destkey 。BITOP NOT destkey key,对给定 key 求逻辑非,并将结果保存到 destkey 。
- 除了 NOT 操作之外,其他操作都可以接受一个或多个 key 作为输入。
- 返回值:保存到 destkey 的字符串的
长度,和输入 key 中最长的字符串长度相等。
redis> SETBIT bits-1 0 1 # bits-1 = 1001 |
bitmaps与set比较
假设网站有 1 亿用户, 每天独立访问的用户有 5 千万, 如果每天用集合类型和 Bitmaps 分别存储活跃用户可以得到表:
- set 和 Bitmaps 存储
一天活跃用户对比
| 数据类型 | 每个用户 id 占用空间 | 需要存储的用户量 | 全部内存量 |
|---|---|---|---|
| set集合 | 64 位 | 50000000 | 64 位 * 50000000 = 400MB (64 ÷ 8 * 50000000 ÷ 1000000 = 400MB) |
| Bitmaps | 1位 | 100000000 | 1 位 * 100000000 = 12.5MB (1 ÷ 8 * 100000000 ÷ 1000000 = 12.5MB) |
1 byte(字节) = 8 bit(位)、1 MB(兆字节) = 1000000 B(字节)
很明显, 这种情况下使用 Bitmaps 能节省很多的内存空间, 尤其是随着时间推移节省的内存还是非常可观的。
- set 和 Bitmaps 存储
独立用户空间对比
| 数据类型 | 一天 | 一月 | 一年 |
|---|---|---|---|
| set集合 | 400MB | 12GB | 144GB |
| Bitmaps | 12.5MB | 375MB | 4.5GB |
假如该网站每天的独立访问用户很少,例如只有 10 万(大量的僵尸用户), 那么两者的对比如下表所示,很显然, 这时候使用Bitmaps就不太合适了,因为基本上大部分位都是 0。
| 数据类型 | 每个 userid 占用空间 | 需要存储的用户量 | 全部内存量 |
|---|---|---|---|
| set集合 | 64 位 | 100000 | 64 位 * 100000 = 800KB |
| Bitmaps | 1 位 | 100000000 | 1 位 * 100000000 = 12.5MB |
HyperLoglog(基数统计)
简介
在工作当中,经常会遇到与统计相关的功能需求,比如统计网站 PV(PageView 页面访问量),可以使用 Redis 的 incr、incrby 轻松实现。但像 UV(UniqueVisitor 独立访客)、独立 IP 数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
- 解决基数问题有很多种方案:
- 数据存储在 MySQL 表中,使用 distinct count 计算不重复个数。
- 使用 Redis 提供的 hash、set、bitmaps 等数据结构来处理。
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。能否能够降低一定的精度来平衡存储空间?Redis 推出了 HyperLogLog。
Redis
HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是:在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集{1, 3, 5, 7, 5, 7, 8},那么这个数据集的基数集为{1, 3, 5 ,7, 8},基数 (不重复元素)为 5。 基数估计就是在误差可接受的范围内,快速计算基数。
常用命令
pfadd:添加多个元素
pfadd key element [element ...] |
- 向HyperLoglog类型的key中添加一个或者多个元素。
- 添加一个或者多个元素到key对应的集合中。
- 返回值:1:添加成功、0:添加失败
127.0.0.1:6379> flushdb # 清空db方便测试 |
pfcount:获取多个HLL合并后元素的个数
pfcount key1 key2 ... |
统计一个或者多个key去重后元素的数量。
127.0.0.1:6379> flushdb # 清空db方便测试 |
pfmerge:将多个HLL合并后元素放入另外一个HLL
pfmerge destkey sourcekey [sourcekey ...] |
将多个
sourcekey合并后放到destkey中。
127.0.0.1:6379> flushdb # 清空db方便测试 |
Geographic(地理信息)
简介
Reids3.2 中增加了对GEO类型的支持,GEO(Geographic)地理信息的缩写。该类型就是元素的二维坐标(经纬度),redis基于该类型提供了经纬度设置、查询、范围查询、距离查询,经纬度Hash等常见操作。
常见命令
geoadd:添加多个位置的经纬度
geoadd key longitude latitude member [longitude latitude member ...] |
longitude经度latitude纬度member名称
127.0.0.1:6379> flushdb #清空db,方便测试 |
两级无法直接添加,一般会下载城市数据,直接通过java程序一次性导入- 有效的
经纬度从-180度到180度,有效的维度从-85.05112878度到85.05112878度。- 当坐标位置
超出指定范围时,该命令将会返回一个错误。已经添加的数据,是无法再次往里面添加的。
geopos:获取多个位置的坐标值
geopos key member [member ...] |
127.0.0.1:6379> flushdb #清空db,方便测试 |
geodist:获取两个位置的直线距离
geodist key member1 member2 [m|km|ft|mi] |
单位:[m|km|ft|mi] ->> [米|千米|英里|英尺],
默认为米
127.0.0.1:6379> flushdb #清空db,方便测试 |
georadius:以给定的经纬度为中心,找出某一半径内的元素
georadius key longitude latitude radius m|km|ft|mi |
单位:[m|km|ft|mi] ->> [米|千米|英里|英尺],
默认为米
127.0.0.1:6379> flushdb #清空db,方便测试 |
Stream(消息队列)
简介
Redis Stream 是 Redis 5.0 版本新增加的数据类型,Redis 专门为消息队列设计的数据类型。
Stream 类型的消息队列,它不仅支持自动生成全局唯一 ID,而且支持以消费组形式消费数据。
常见命令
XADD:插入消息,保证有序,可以自动生成全局唯一 ID;
# 往名称为 mymq 的消息队列中插入一条消息,消息的键是 name,值是 xiaolin |
插入成功后会返回全局唯一的 ID:”1654254953808-0”。消息的全局唯一 ID 由两部分组成:
- 第一部分:”1654254953808”是数据插入时,以
毫秒为单位计算的当前服务器时间;- 第二部分:表示插入消息在当前毫秒内的消息序号,这是从 0 开始编号的。例如,”1654254953808-0”就表示在”1654254953808”毫秒内的第 1 条消息。
XREAD:用于读取消息,可以按 ID 读取数据;
可以指定一个消息 ID,并从这个消息ID的下一条消息开始进行读取(注意是输入消息 ID 的下一条信息开始读取,不是查询输入ID的消息)。
# 从 ID 号为1654254953807-0的消息开始,读取后续的所有消息(示例中一共 1 条)。 |
如果想要实现阻塞读(当没有数据时,阻塞住),可以调用 XRAED 时设定 block 配置项,比如,设置了 block 10000 的配置项,10000 的单位是毫秒,表明 XREAD 在读取最新消息时,如果没有消息到来,XREAD 将阻塞 10000 毫秒(即 10 秒),然后再返回。
# 命令最后的"$"符号表示读取最新的消息 |
XGROUP:创建消费组
创建一个名为 group1 的消费组,消费组消费的消息队列是 mymq
> XGROUP create mymq group1 0 |
XREADGROUP:按消费组形式读取消息;
消费组 group1 内的消费者 consumer1 从 mymq 消息队列中读取所有消息
# 命令最后的参数">",表示从第一条尚未被消费的消息开始读取 |
消息队列中的消息一旦被消费组里的一个消费者读取了,就不能再被该消费组内的其他消费者读取了。比如说,执行完刚才的 XREADGROUP 命令后,再执行一次同样的命令,此时读到的就是空值
> XREADGROUP group group1 consumer1 Stream mymq > |
使用消费组的目的是
让组内的多个消费者共同分担读取消息,所以,通常会让每个消费者读取部分消息,从而实现消息读取负载在多个消费者间是均衡分布的。
比如,执行下列命令,让group2中的consumer1、2、3各自读取一条消息。
# 让 group2 中的 consumer1 从 mymq 消息队列中消费一条消息 |
# 让 group2 中的 consumer2 从 mymq 消息队列中消费一条消息 |
# 让 group2 中的 consumer3 从 mymq 消息队列中消费一条消息 |
XPENDING和XACK:
XPENDING:可以用来查询每个消费组内所有消费者已读取但尚未确认的消息XACK:用于向消息队列确认消息处理已完成。
基于 Stream 实现的消息队列,如何保证消费者在发生故障或宕机再次重启后,仍然可以读取未处理完的消息?
Streams 会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息,直到消费者使用 XACK 命令通知 Streams"消息已经处理完成"。
如果消费者没有成功处理消息,它就不会给 Streams 发送 XACK 命令,消息仍然会留存。此时,消费者可以在重启后,用 XPENDING 命令查看已读取、但尚未确认处理完成的消息。
比如,来查看一下 group2 中各个消费者已读取、但尚未确认的消息个数
127.0.0.1:6379> XPENDING mymq group2 |
如果想查看某个消费者具体读取了哪些数据,可以执行:
# 查看 group2 里 consumer2 已从 mymq 消息队列中读取了哪些消息 |
可以看到,consumer2 已读取的消息的 ID 是 1654256265584-0。
一旦消息 1654256265584-0 被 consumer2 处理了,consumer2 就可以使用 XACK 命令通知 Streams,然后这条消息就会被删除。
> XACK mymq group2 1654256265584-0 |
当再使用XPENDING命令查看时,就可以看到,consumer2 已经没有已读取、但尚未确认处理的消息了。
> XPENDING mymq group2 - + 10 consumer2 |
与专业消息队列的差距
一个专业的消息队列,必须要做到两大块:
- 消息不丢。
- 消息可堆积。
Redis Stream 消息会丢失吗?
使用一个消息队列,其实就分为三大块:生产者、队列中间件、消费者,所以要保证消息就是保证三个环节都不能丢失数据。
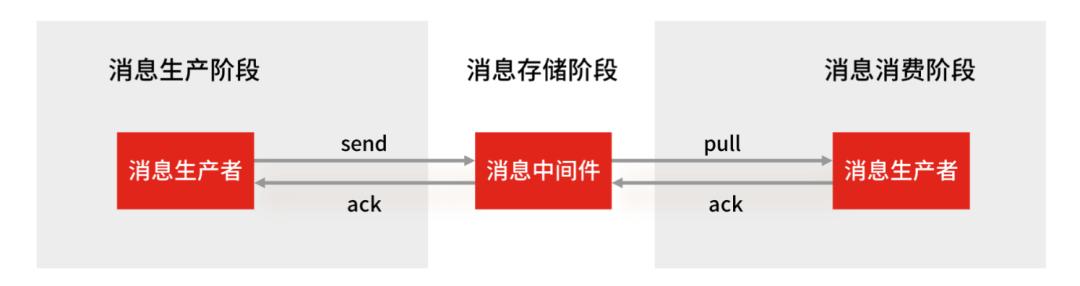
Redis Stream 消息队列能不能保证三个环节都不丢失数据?
- Redis
生产者会不会丢消息?
生产者会不会丢消息,取决于生产者对于异常情况的处理是否合理。从消息被生产出来,然后提交给 MQ 的过程中,只要能正常收到 ( MQ 中间件) 的 ack 确认响应,就表示发送成功,所以只要处理好返回值和异常,如果返回异常则进行消息重发,那么这个阶段是不会出现消息丢失的。
- Redis
消费者会不会丢消息?
不会,因为 Stream ( MQ 中间件)会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息,但是未被确认的消息。消费者可以在重启后,用XPENDING命令查看已读取、但尚未确认处理完成的消息。等到消费者执行完业务逻辑后,再发送消费确认XACK命令,也能保证消息的不丢失。
- Redis
中间件会不会丢消息?
会,Redis 在以下 2 个场景下,都会导致数据丢失:
- AOF 持久化配置为每秒写盘,但这个
写盘过程是异步的,Redis宕机时会存在数据丢失的可能- 主从复制也是异步的,
主从切换时,也存在丢失数据的可能。
Redis Stream 消息可堆积吗?
Redis 的数据都存储在内存中,这就意味着一旦发生消息积压,则会导致 Redis 的内存持续增长,如果超过机器内存上限,就会面临被 OOM 的风险。所以Redis的Stream提供了可以指定队列最大长度的功能,就是为了避免这种情况发生。
但 Kafka、RabbitMQ 专业的消息队列它们的数据都是存储在磁盘上,当消息积压时,无非就是多占用一些磁盘空间。
结论
因此,把 Redis 当作队列来使用时,会面临的 2 个问题:
- Redis 本身可能会丢数据;
- 面对消息挤压,内存资源会紧张;
所以,能不能将 Redis 作为消息队列来使用,关键看业务场景:
- 如果你的业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的。
- 如果你的业务有海量消息,消息积压的概率比较大,并且不能接受数据丢失,那么还是用专业的消息队列中间件吧。
Redis的持久化
持久化概述
Redis的高性能是由于其将所有数据都存储在了内存中,为了使Redis在重启之后仍能保证数据不丢失,需要将数据从内存中同步到硬盘中,这一过程就是持久化。Redis支持两种方式的持久化,一种是RDB方式,一种是AOF方式。可以单独使用其中一种或将二者结合使用。
RDB持久化(默认支持,无需配置)
该机制是在指定的时间间隔内将内存中的数据集快照写入磁盘。AOF持久化
该机制将以日志的形式记录服务器所处理的每一个写操作,在Redis服务器启动之初会读取该文件来重新构建数据库,以保证启动后数据库中的数据是完整的。无持久化
可以通过配置的方式禁用Redis服务器的持久化功能,这样可以将Redis视为一个功能加强版的memcached了。- Redis可以
同时使用RDB和AOF
RDB持久化机制
优点
- 一旦采用该方式,那么整个Redis数据库将
只包含一个rdb文件,这对于文件备份而言是非常完美的。比如,可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,可以非常容易的进行恢复。- 对于灾难恢复而言,RDB是非常不错的选择。因为可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上
性能最大化。对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork(分叉)出子进程,之后再由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。相比于AOF机制,如果数据集很大,RDB的启动效率会更高
缺点
- 如果想保证数据的高可用性(就是内存数据不丢失),即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统
一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。- 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果
当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟
配置
在redis.windows.conf配置文件中有如下配置:
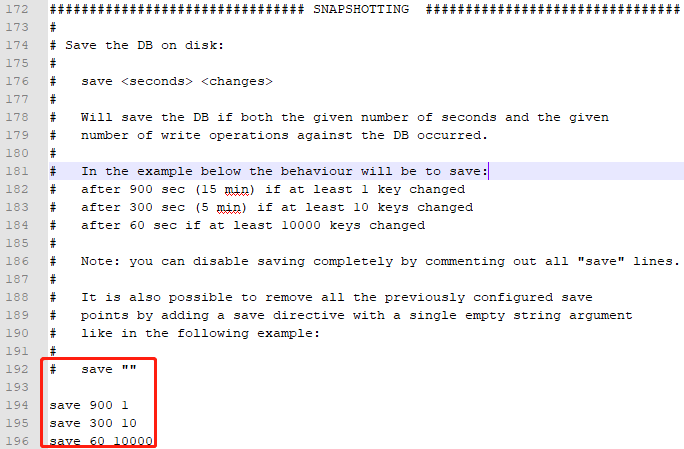
其中,上面配置的是RDB方式数据持久化时机,可以多个条件配合
AOF持久化机制
优点
- 该机制可以带来
更高的数据安全性,即数据持久性。Redis中提供了3种同步策略,即每秒同步、每修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。而每修改同步,可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。可以预见,这种方式在效率上是最低的。至于无同步,无需多言。- 由于该机制
对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。- 如果
日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性。- AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。
可以通过该文件完成数据的重建
缺点
- 对于相同数量的数据集而言,
AOF文件通常要大于RDB文件- 根据同步策略的不同,
AOF在运行效率上往往会慢于RDB
配置
开启AOF持久化
在redis.windows.conf配置文件中有如下配置:
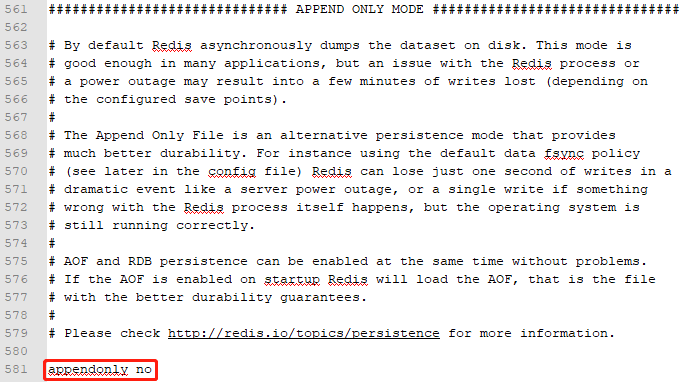
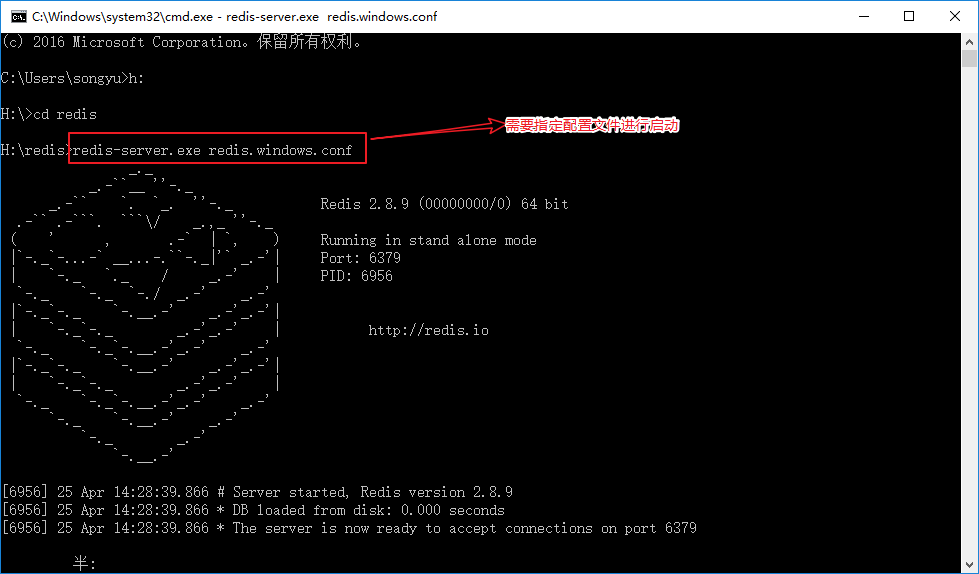
将appendonly修改为yes,开启aof持久化机制,默认会在目录下产生一个appendonly.aof文件,启动需要指定配置文件
AOF持久化时机
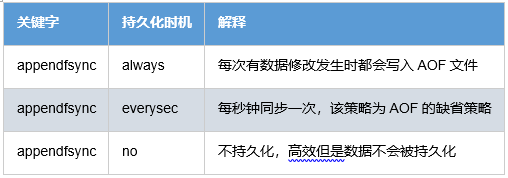
#appendfsync always |
上述配置为aof持久化的时机,解释如下:
过期与淘汰策略
长期将Redis作为缓存使用,难免会遇到内存空间存储瓶颈,当Redis内存超出物理内存限制时,Redis性能将急剧下降。此时如何淘汰无用数据释放空间,存储新数据就变得尤为重要了。
设置占用内存
- 文件配置
找到# maxmemory <bytes>,去掉#注释,设置maxmemory参数,maxmemory是bytes字节类型,注意转换,一般推荐Redis设置使用内存为最大物理内存的四分之三,Redis服务重启后不会失效
- 命令修改
使用redis-cli客户端命令修改,Redis服务重启后将失效
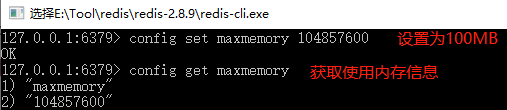
如果
不设置 最大内存大小或者设置 最大内存大小为0,在64位操作系统下不限制内存大小,在32位操作系统下最多使用3GB内存
过期策略
Redis采用的过期策略是:定期删除 + 惰性删除策略。
- 为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key。因此没有采用这一策略.
- 定期删除 + 惰性删除是如何工作的呢?
定期删除,redis默认每个100ms检查一次,随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
- 采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰策略。
淘汰策略
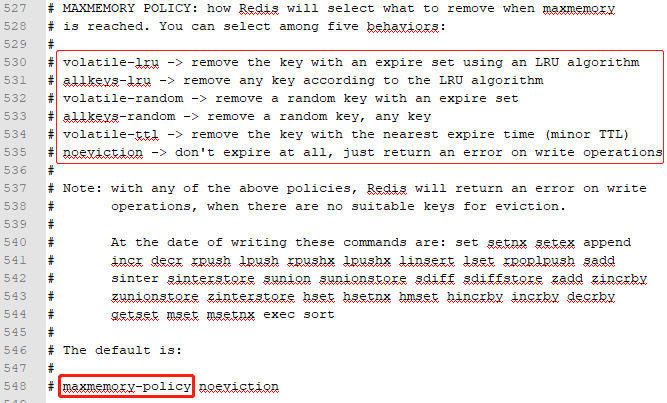
Redis定义了六种策略用来处理这种情况:
noeviction(默认策略):对于写请求不再提供服务,直接返回错误(DEL请求和部分特殊请求除外)allkeys-lru:从所有key中,使用LRU算法进行淘汰最近最少使用的数据allkeys-random:从所有key中,随机选择数据淘汰volatile-lru:从设置了过期时间的key中,使用LRU算法进行淘汰最近最少使用的数据volatile-random:从设置了过期时间的key中,随机选择数据淘汰volatile-ttl:在设置了过期时间的key中,根据key的过期时间进行淘汰,越早过期的越优先被淘汰
注:
- 当使用
volatile-lru、volatile-random、volatile-ttl这三种策略时,如果key没有设置 expire(过期时间),则和noeviction一样返回错误- 将key
设置过期时间实际上会消耗更多的内存,因此建议使用allkeys-lru策略从而更有效率的使用内存
文件设置
找到# maxmemory-policy,去掉#注释,在maxmemory-policy后设置淘汰策略,Redis重启后不会失效
命令修改
使用redis-cli客户端命令修改,Redis服务重启后将失效

LRU算法
LRU(Least Recently Used),即最近最少使用,是一种缓存置换算法。在使用内存作为缓存的时候,缓存的大小一般是固定的。当缓存被占满,这个时候继续往缓存里面添加数据,就需要淘汰一部分老的数据,释放内存空间用来存储新的数据。这个时候就可以使用LRU算法了。
核心思想是:如果一个数据在最近一段时间没有被用到,那么将来被使用到的可能性也很小,所以就可以被淘汰掉。
在Redis中的实现
近似LRU算法
Redis使用的是近似LRU算法,它跟常规的LRU算法还不太一样。近似LRU算法通过随机采样法淘汰数据,每次随机出5(默认)个key,从里面淘汰掉最近最少使用的key。
可以通过
maxmemory-samples参数修改采样数量
例:maxmemory-samples 10
maxmenory-samples配置的越大,淘汰的结果越接近于严格的LRU算法
Redis为了实现近似LRU算法,给每个key增加了一个额外增加了一个24bit的字段,用来存储该key最后一次被访问的时间。

Redis3.0的优化
Redis3.0对近似LRU算法进行了一些优化。新算法会维护一个候选池(大小为16),池中的数据根据访问时间进行排序,第一次随机选取的key都会放入池中,随后每次随机选取的key,只有在访问时间小于池中最小的时间才会放入池中,直到候选池被放满。当放满后,如果有新的key需要放入,则将池中最后访问时间最大(最近被访问)的移除。
当需要淘汰的时候,则直接从池中选取最近访问时间最小(最久没被访问)的key淘汰掉就行。
LFU算法
LFU算法是Redis4.0里面新加的一种淘汰策略。它的全称是Least Frequently Used,它的核心思想是根据key的最近被访问的频率进行淘汰,很少被访问的优先被淘汰,被访问的多的则被留下来。
LFU一共有两种策略:
volatile-lfu:在设置了过期时间的key中,使用LFU算法淘汰keyallkeys-lfu:在所有的key中,使用LFU算法淘汰数据
设置使用这两种淘汰策略跟前面讲的一样,不过要注意的一点是这两种策略只能在Redis4.0及以上设置,如果在Redis4.0以下设置会报错
LRU与LFU的区别
LFU算法能更好的表示一个key被访问的热度。假如你使用的是LRU算法,一个key很久没有被访问到,只刚刚是偶尔被访问了一次,那么它就被认为是热点数据,不会被淘汰,而有些key将来是很有可能被访问到的则被淘汰了(Redis不直接使用LRU算法的原因)。如果使用LFU算法则不会出现这种情况,因为使用一次并不会使一个key成为热点数据。
缓存设计
缓存穿透
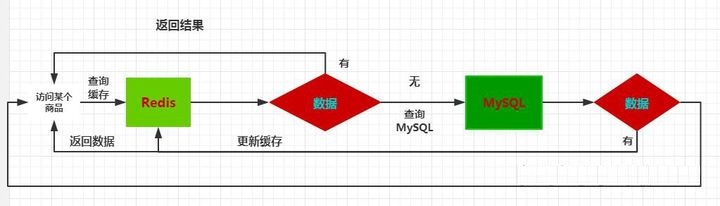
什么是缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到对应key的value,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。
在流量大时,要是有人利用不存在的key频繁攻击我们的应用,可能DB就挂掉了,这就是漏洞。
有什么解决方案来防止缓存穿透
- 缓存空值
如果一个查询返回的数据为空(不管是数据不存在,还是系统故障)我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过5分钟。通过这个设置的默认值存放到缓存,这样第二次到缓存中获取就有值了,而不会继续访问数据库
- 采用布隆过滤器BloomFilter
优势:占用内存空间很小,位存储;性能特别高,使用key的hash判断key存不存在
将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力在缓存之前在加一层BloomFilter,在查询的时候先去BloomFilter去查询key是否存在,如果不存在就直接返回,存在再去查询缓存,缓存中没有再去查询数据库
总结
缓存击穿访问了不存在的数据,跳过了合法数据的redis数据缓存阶段,每次访问数据库,导致对数据库服务器造成压力。通常此类数据的出现量是一个较低的值,当出现此类情况以毒攻毒,并及时报警。应对策略应该在临时预案防范方面多做文章。无论是黑名单还是白名单,都是对整体系统的压力,警报解除后尽快移除。
缓存击穿
什么是缓存击穿
在平常高并发的系统中,大量的请求同时查询一个key时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。这种现象我们称为缓存击穿
问题排查
- Redis中某个key过期,该key访问量巨大
- 多个数据请求从服务器直接压到Redis后,均未命中
- Redis在短时间内发起了大量对数据库中同一数据的访问
解决方案
使用互斥锁(mutex key)
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。在redis2.6.1之前版本未实现setnx的过期时间,下面给出两种版本代码参考:
// 2.6.1前单机版本锁 |
// 2.6.1后单机版本锁 |
// memcache代码 |
提前使用互斥锁(mutex key)
在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。
当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中。
// memcache伪代码如下: |
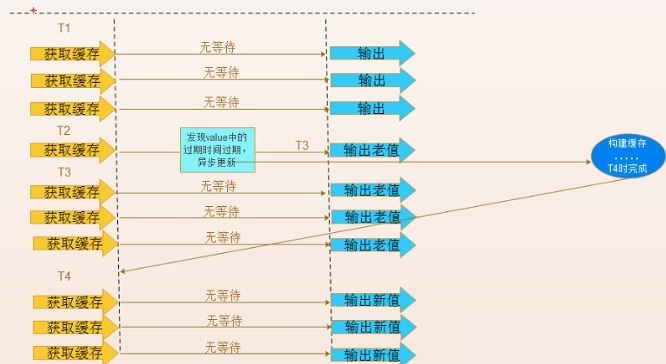
永远不过期
这里的“永远不过期”包含两层意思:
- 从redis上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
- 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
String get(final String key) { |
资源保护
采用netflix的hystrix,可以做资源的隔离保护主线程池,如果把这个应用到缓存的构建也未尝不可。
四种解决方案:没有最佳只有最合适
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 简单分布式锁(Tim yang) | 1. 思路简单 2. 保证一致性 |
1. 代码复杂度增大 2. 存在死锁的风险 3. 存在线程池阻塞的风险 |
| 加另外一个过期时间(Tim yang) | 保证一致性 | 同上 |
| 不过期(本文) | 异步构建缓存,不会阻塞线程池 | 1. 不保证一致性。 2. 代码复杂度增大(每个value都要维护一个timekey)。 3. 占用一定的内存空间(每个value都要维护一个timekey)。 |
| 资源隔离组件hystrix(本文) | hystrix技术成熟,有效保证后端。 hystrix监控强大。 |
部分访问存在降级策略。 |
总结
缓存击穿就是单个高热数据过期的瞬间,数据访问量较大,未命中redis后,发起了大量对同一数据的数据库访问,导致对数据库服务器造成压力。应对策略应该在业务数据分析与预防方面进行,配合运行监控测试与即时调整策略,毕竟单个key的过期监控难度较高,配合雪崩处理策略即可。
缓存雪崩
什么是缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。由于原有缓存失效,新缓存未到期间所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。
缓存雪崩问题排查
- 在一个较短的时间内,缓存中较多的key集中过期
- 此周期内请求访问过期的数据,redis未命中,redis向数据库获取数据
- 数据库同时接收到大量的请求无法及时处理
- Redis大量请求被积压,开始出现超时现象
- 数据库流量激增,数据库崩溃
- 重启后仍然面对缓存中无数据可用
- Redis服务器资源被严重占用,Redis服务器崩溃
- Redis集群呈现崩塌,集群瓦解
- 应用服务器无法及时得到数据响应请求,来自客户端的请求数量越来越多,应用服务器崩溃
- 应用服务器,redis,数据库全部重启,效果不理想
有什么解决方案来防止缓存雪崩?
更多的页面静态化处理
构建多级缓存架构
Nginx缓存+redis缓存+ehcache缓存检测Mysql严重耗时业务进行优化
对数据库的瓶颈排查:例如超时查询、耗时较高事务等灾难预警机制
- 监控redis服务器性能指标
- CPU占用、CPU使用率
- 内存容量
- 查询平均响应时间
- 线程数
- 限流、降级
短时间范围内牺牲一些客户体验,限制一部分请求访问,降低应用服务器压力,待业务低速运转后再逐步放开访问 - LRU与LFU切换
- 数据有效期策略调整
- 根据业务数据有效期进行分类错峰,A类90分钟,B类80分钟,C类70分钟
- 过期时间使用
固定时间+随机值(时间值)的形式,稀释集中到期的key的数量
- 超热数据使用永久key
- 定期维护(自动+人工)
对即将过期数据做访问量分析,确认是否延时,配合访问量统计,做热点数据的延时 - 加锁
总结
缓存雪崩就是瞬间过期数据量太大,导致对数据库服务器造成压力。如能够有效避免过期时间集中,可以有效解决雪崩现象的出现(约40%),配合其他策略一起使用,并监控服务器的运行数据,根据运行记录做快速调整。
缓存预热
什么是缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题。用户直接查询事先被预热的缓存数据。如图所示:
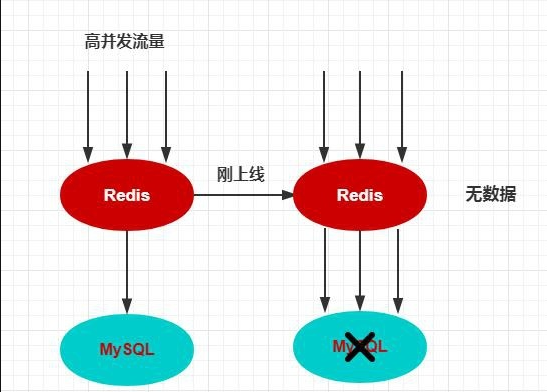
如果不进行预热, 那么Redis初识状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
问题排查
- 请求数量较高
- 主从之间数据吞吐量较大,数据同步操作频度较高
有什么解决方案
- 前置准备工作:
- 日常例行统计数据访问记录,统计访问频度较高的热点数据
- 利用LRU数据删除策略,构建数据留存队列
例如:storm与kafka配合
- 准备工作:
- 将统计结果中的数据分类,根据级别,redis优先加载级别较高的热点数据
- 利用分布式多服务器同时进行数据读取,提速数据加载过程
- 热点数据主从同时预热
- 实施:
- 使用脚本程序固定触发数据预热过程
- 如果条件允许,使用了
CDN(内容分发网络),效果会更好
总结
缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据
缓存降级
降级的情况,就是缓存失效或者缓存服务挂掉的情况下,我们也不去访问数据库。我们直接访问内存部分数据缓存或者直接返回默认数据。
举例来说:
对于应用的首页,一般是访问量非常大的地方,首页里面往往包含了部分推荐商品的展示信息。这些推荐商品都会放到缓存中进行存储,同时我们为了避免缓存的异常情况,对热点商品数据也存储到了内存中。同时内存中还保留了一些默认的商品信息。如下图所示:
注:降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。
Jedis的基本使用
介绍
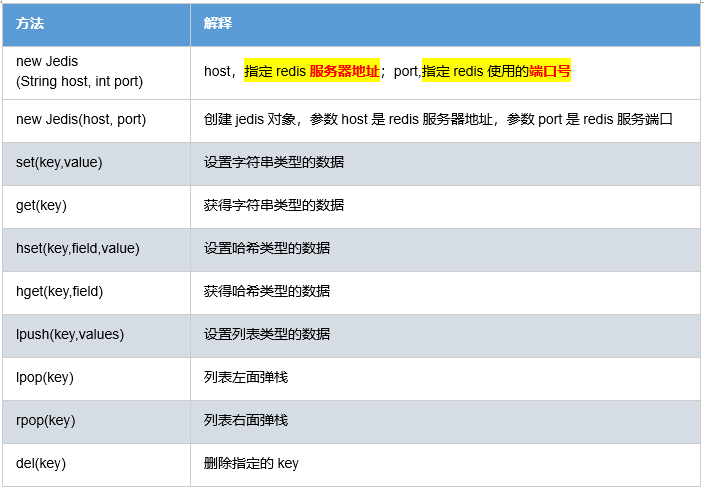
Redis不仅是使用命令来操作,现在基本上主流的语言都有客户端支持,比如java、C、C#、C++、php、Node.js、Go等。 在官方网站里列一些Java的客户端,有Jedis、Redisson、Jredis、JDBC-Redis、等其中官方推荐使用Jedis和Redisson。 在企业中用的最多的就是Jedis,Jedis同样也是托管在github上,地址:
Jedis基本上实现了所有的Redis命令,并且还支持连接池、集群等高级的用法,而且使用简单,使得在Java中使用Redis服务将变得非常的简单,Maven依赖:
<dependency> |
基本操作
常用API
代码操作
import redis.clients.jedis.Jedis; |
连接池的使用
基本概念
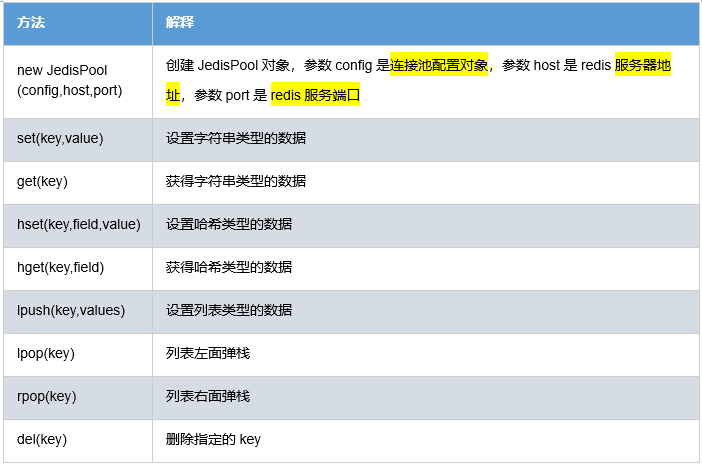
jedis连接资源的创建与销毁是很消耗程序性能,所以jedis为我们提供了jedis的池化技术,jedisPool在创建时初始化一些连接资源存储到连接池中,使用jedis连接资源时不需要创建,而是从连接池中获取一个资源进行redis的操作,使用完毕后,不需要销毁该jedis连接资源,而是将该资源归还给连接池,供其他请求使用。
常用API
代码操作
import redis.clients.jedis.Jedis; |
连接池工具类
配置文件
jedis.properties
maxTotal=100 |
工具类
import redis.clients.jedis.Jedis; |
测试代码
import com.itheima.util.JedisUtils; |
Servelet整合Redis
需求
- Redis实战之查询所有省份
访问index.jsp页面,使用ajax请求加载省份列表,用户第一次访问数据库获取,以后都从redis里面获取。
- province(数据库表)

写入测试数据
insert into `province`(`pid`,`pname`) values (1,'广东省'),(2,'湖南省'),(3,'吉林省'),(4,'广西省'); |
- 分析
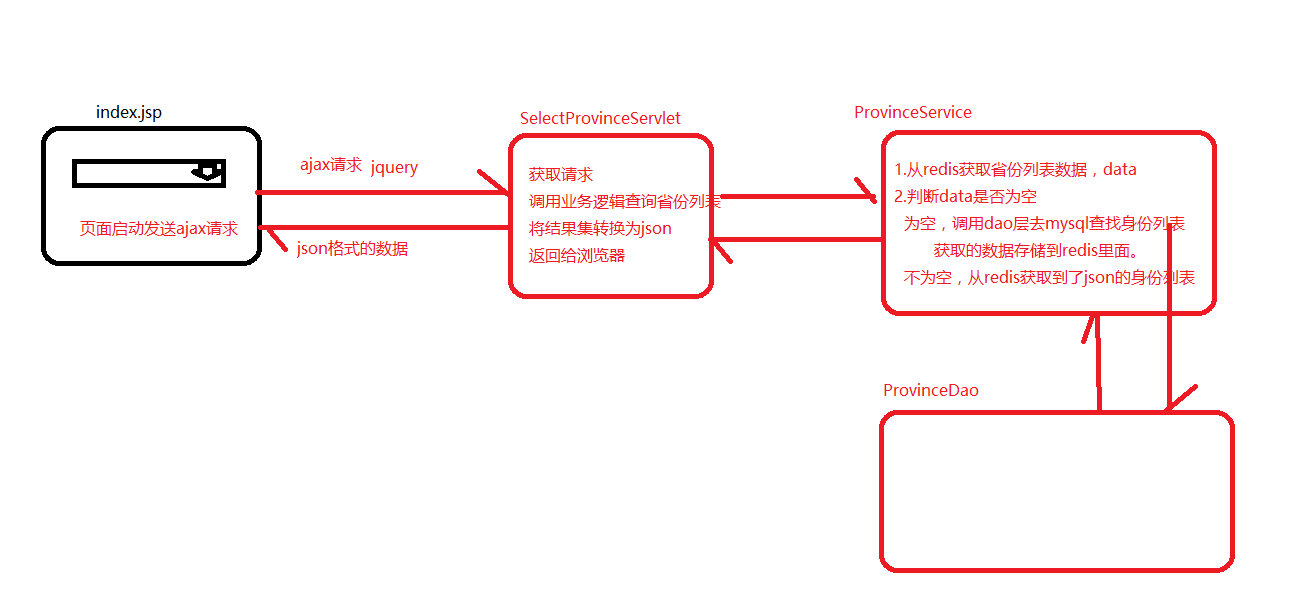
配置文件
druid.properties
driverClassName=com.mysql.jdbc.Driver |
jedis.properties
maxTotal=100 |
实体类
Province.java
public class Province { |
工具类
JdbcUtils.java
import com.alibaba.druid.pool.DruidDataSourceFactory; |
JedisUtils.java
import redis.clients.jedis.Jedis; |
过滤器
CharchaterFilter.java
import javax.servlet.*; |
页面
index.jsp
<%@ page contentType="text/html;charset=UTF-8" language="java" %> |
逻辑
SelectProvinceServelt
import com.itheima.service.ProvinceService; |
ProvinceService
import com.fasterxml.jackson.databind.ObjectMapper; |
ProvinceDao
import com.itheima.model.Province; |
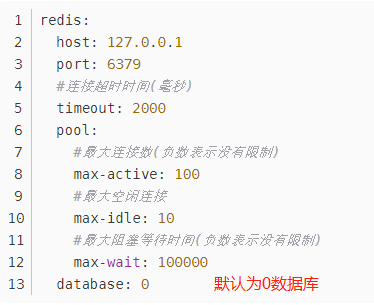
SpringBoot整合Redis
依赖
<dependency> |
spring-boot-starter-redis
(springboot版本1.4版本前)
spring-boot-starter-data-redis(1.4版本后)
配置
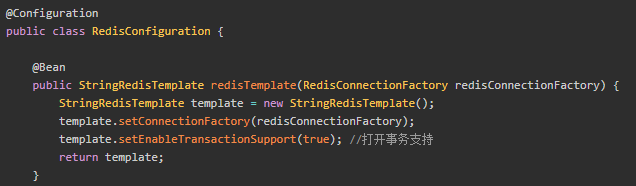
Redis事务
springboot 2.0之前的版本,会发生在刚开始运行的时候发送几次请求操作redis之后,后面被阻塞的情况(redis默认8个连接池),原因是针对打开事务支持的template,只是解绑了连接,根本没有做close的操作。
注:该问题只会出现在springboot 2.0之前的版本;
2.0之后springboot连接Redis改成了lettuce,并重新实现,问题已经不存在
@Transanctional注解支持Redis事务
Spring中要使用@Transanctional首先要配transactionManager,但是Spring没有专门针对Redis的事务管理器实现,而是所有调用RedisTemplate的方法最终都会调用到RedisConnctionUtils这个类的方法上面,在这个类里面会判断是不是进入到事务里面,也就是说Redis的事务管理的功能是由RedisConnctionUtils内部实现的。
根据官方文档,要
想用Redis事务,也必须把JDBC捎上。POM文件中必须带上数据库的依赖
配置
在Spring中要使用Redis注解式事务,首先要设置RedisTemplate的enableTransactionSupport属性为true,然后配置一个jdbc的事务管理器。这点非常重要,一旦这样配置,所有使用这个template的Redis操作都必须走注解式事务,要不然会导致连接一直占用,不关闭。
注:此处代码使用
StringRedisTemplate,可换为RedisTemplate

再次发送请求,无论点多少次,Redis的连接数始终维持在1个不变。在看程序的输出日志里面也发现了,事务结束后连接被正常释放。因为使用了JDBC的事务管理器,所以还顺便做了一次数据库事务的开启和提交。还有一点值得注意的是,跟数据库一样,使用注解来做事务管理,Spring也会主动管理Redis事务的提交和回滚,也就是在之前发送一条MULTI命令,成功后发送EXEC,失败后发送DISCARD
建议
- 升级到springboot 2.0以上版本,如果因为项目原因无法升级看下面的建议
- 如果使用Redis事务的场景不多,完全可以自己管理,不需要使用spring的注解式事务。如下面这样使用
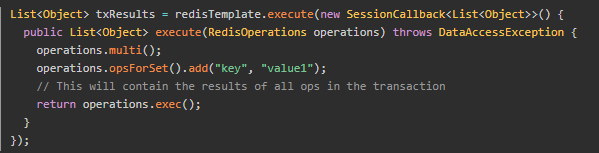
如果一定要使用spring提供的注解式事务,建议初始化两个RedisTemplate Bean,分别设置enableTransactionSupport属性为true和false。针对需要事务和不需要事务的操作使用不同的template。
从个人角度,我不建议使用redis事务,因为redis对于事务的支持并不是关系型数据库那样满足ACID。
Redis事务只能保证ACID中的隔离性和一致性,无法保证原子性和持久性。而我们使用事务最重要的一个理由就是原子性,这一点无法保证,事务的意义就去掉一大半了。所以事务的场景可以尝试通过业务代码来实现
StringRedisTemplate 和 RedisTemplate
选择
主要是根据Redis存储的数据类型需求决定,key一般都是String,但是value可能不一样,一般有两种,String和 Object;
- 如果
k-v都是String类型,我们可以直接用StringRedisTemplate,这个是官方建议的,也是最方便的,直接导入即用,无需多余配置!- 如果
k-v是Object类型,则需要自定义RedisTemplate
区别
注:RedisTemplate是线程安全的,开箱即用,可以在多个实例中重复使用
- StringRedisTemplate继承了RedisTemplate。
RedisTemplate是一个泛型类,而StringRedisTemplate则不是。- StringRedisTemplate只能对key=String,value=String的键值对进行操作,
RedisTemplate可以对任何类型的key-value键值对操作。 各自序列化的方式不同,但最终都是得到了一个字节数组;StringRedisTemplate使用的是StringRedisSerializer类;RedisTemplate使用的是JdkSerializationRedisSerializer类。反序列化,则是一个得到String,一个得到Object
RedisTemplate用法
注:TimeUnit是java.util.concurrent包下面的一个类,表示给定单元粒度的时间段
| 常用的颗粒度常量 | 含义 |
|---|---|
| TimeUnit.DAYS | 天 |
| TimeUnit.HOURS | 小时 |
| TimeUnit.MINUTES | 分钟 |
| TimeUnit.SECONDS | 秒 |
String数据结构
操作String数据
redisTemplate.opsForValue() |
Set设置
set(K key, V value);

set(K key, V value, long timeout, TimeUnit unit);
设置变量值的过期时间

set(K key, V value, long offset);
覆写(overwrite)给定 key 所储存的字符串值,从指定位置开始的值

setBit(K key, long offset, boolean value)
key键对应值的ascii码,将offset(偏移) (从左向右数)位置上的值变为value,false为0,true为1
template.opsForValue().set("bitTest","a"); |
setIfAbsent(K key, V value)
先判断Key是否存在,不存在则新增并返回true;存在则返回false
System.out.println(template.opsForValue().setIfAbsent("multi1","multi1")); |
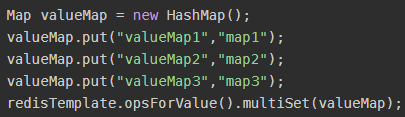
multiSet(Map<? extends K,? extends V> map)
设置map集合到redis
multiSetIfAbsent(Map<? extends K,? extends V> map)
设置map集合到redis,如果map存在则返回false,不存在则创建并返回true
Get获取
get(Object key);
获取key键对应的值。

get(K key, long start, long end)
截取key键对应值得字符串,从开始下标位置开始到结束下标的位置(包含结束下标)的字符串

getBit(K key, long offset)
获取键对应值的ascii码,在offset处的位值
template.opsForValue().set("bitTest","a"); |
getAndSet(K key, V value);
设置键的字符串值并返回其旧值

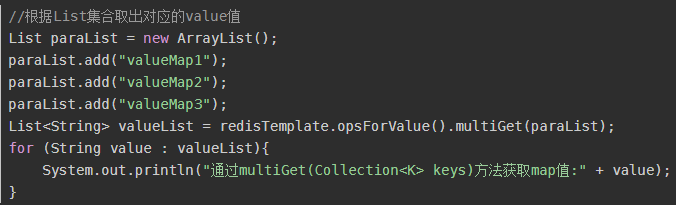
multiGet(Collection<K> keys)
根据集合取出对应的value值。
Append 追加、Size长度
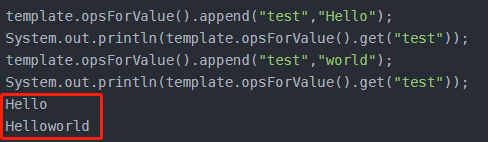
append Integer append(K key, String value);
- 如果key
已经存在并且是一个字符串,则该命令将该值追加到字符串的末尾。 - 如果键
不存在,则它被创建并设置为空字符串,因此APPEND在这种特殊情况下将类似于SET。
size Long size(K key);
返回key所对应的value值得长度

increment 增量
increment(K key, double delta)
以增量的方式将double值存储在变量中

increment(K key, long delta)
以增量的方式将long值存储在变量中

List数据结构
操作List数据
redisTemplate.opsForList() |
设置
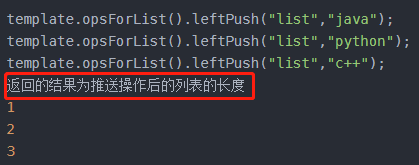
Long leftPush(K key, V value);
将所有指定的值,从左边插入存储在键列表的头部。如果键不存在,则先将其创建为空列表再插入。
Long leftPushAll(K key, V... values);
批量把一个数组各元素从左边插入到列表中

Long leftPushIfPresent(K key, V value);
只有当key存在时才将value插入到列表中,并返回列表长度;当key不存在时,不会创建Key并返回0
System.out.println(template.opsForList().leftPushIfPresent("leftPushIfPresent","aa")); |
System.out.println(template.opsForList().leftPush("leftPushIfPresent","aa")); |
Long rightPush(K key, V value);
将所有指定的值,从右边插入存储在键列表的头部。如果键不存在,则先将其创建为空列表再插入。
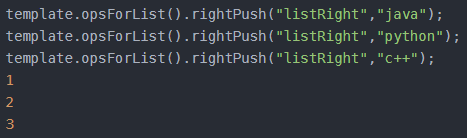
Long rightPushAll(K key, V... values);
批量把一个数组各元素从右边插入到列表中

void set(K key, long index, V value);
在列表中index的位置设置value值
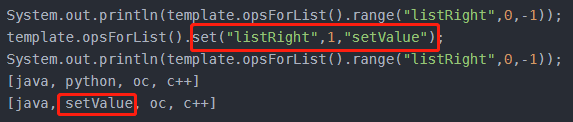
获取
List<V> range(K key, long start, long end);
从指定偏移开始到偏移结束,返回存储在键中的列表的指定元素。索引从零开始
System.out.println(template.opsForList().range("list",0,-1)); |
V index(K key, long index);
根据下标获取列表中的值,下标从0开始

Long size(K key);
返回存储在键中的列表的长度。如果键不存在,则将其解释为空列表,并返回0。当key存储的值不是列表时返回错误

截取
void trim(K key, long start, long end);
从键中指定偏移开始至偏移结束来截取元素,索引从0开始
System.out.println(template.opsForList().range("list",0,-1)); |
移除
Long remove(K key, long count, Object value);
count > 0:从头到尾查找键列表,删除第一个等于value的元素。count < 0:从尾到头查找键列表,删除第一个等于value的元素count = 0:删除等于value的所有元素
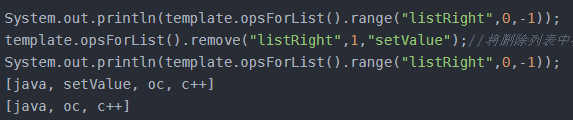
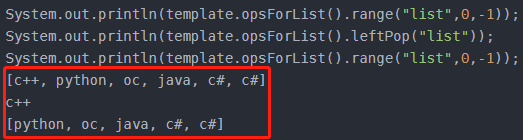
V leftPop(K key);
移除最左边的一个元素,返回此元素
V leftPop(K key, long timeout, TimeUnit unit);
移除最左边的一个元素,返回此元素;如果列表没有元素会一直阻塞列表,直到等待超时或发现可弹出元素为止
V rightPop(K key);
移除最右边的一个元素,返回此元素
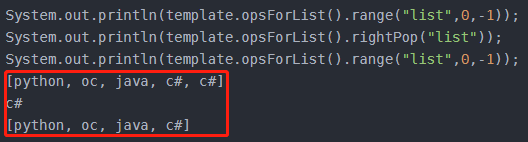
V rightPop(K key, long timeout, TimeUnit unit);
移除最右边的一个元素,返回此元素,如果列表没有元素会一直阻塞列表,直到等待超时或发现可弹出元素为止
V rightPopAndLeftPush(K sourceKey, K destinationKey);
用于移除第一个列表的最后一个元素,并将该元素添加到第二个列表,并返回第一个列表数据
System.out.println(template.opsForList().range("list",0,-1)); |
V rightPopAndLeftPush(K sourceKey, K destinationKey, long timeout, TimeUnit unit);
用于移除第一个列表的最后一个元素,并将该元素添加到第二个列表并返回第一个列表数据,如果列表没有元素会一直阻塞列表,直到等待超时或发现可弹出元素为止
Hash数据机构
操作Hash数据,相当于无序键值对集合
redisTemplate.opsForHash() |
设置
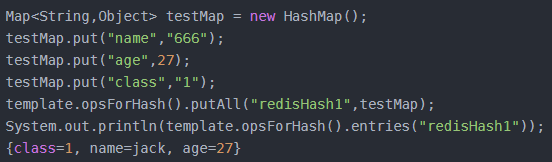
void putAll(H key, Map<? extends HK, ? extends HV> m);
使用map中提供的多个散列字段设置到key对应的散列表中
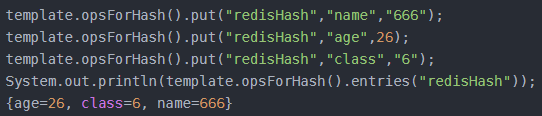
void put(H key, HK hashKey, HV value);
给指定key设置散列hashKey的值
获取
Map<HK, HV> entries(H key);
获取整个哈希存储

List<HV> values(H key);
获取整个哈希存储的值

HV get(H key, Object hashKey);
从哈希中获取指定Key的值

Set<HK> keys(H key);
获取哈希中所有的key

Long size(H key);
获取哈希中所对应散列表key的个数

Cursor<Map.Entry<HK, HV>> scan(H key, ScanOptions options);
使用Cursor在key的hash中迭代,相当于迭代器。
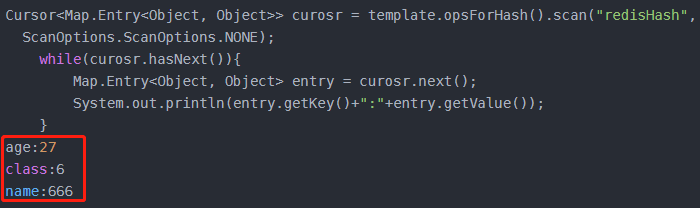
移除
Long delete(H key, Object... hashKeys);
删除哈希中指定的Key

判断
Boolean hasKey(H key, Object hashKey);
判断指定的Key在哈希中是否存在

Set数据结构
操作Set数据,相当于无序集合
redisTemplate.opsForSet() |
设置
Long add(K key, V... values);
无序集合中添加元素,返回添加个数

也可以直接在add里面添加多个值 如:
template.opsForSet().add("setTest","aaa","bbb") |
获取
Long size(K key);
获取无序集合的长度

Set<V> members(K key);
返回集合中的所有成员

V randomMember(K key);
随机获取key无序集合中的一个元素
System.out.println("setTest:" + template.opsForSet().members("setTest")); |
List<V> randomMembers(K key, long count);
获取多个key无序集合中的元素(不去重),count表示个数
System.out.println("randomMembers:" + template.opsForSet().randomMembers("setTest",5)); |
Set<V> distinctRandomMembers(K key, long count);
获取key无序集合中的元素(去重),count表示个数
System.out.println("randomMembers:" + template.opsForSet().distinctRandomMembers("setTest",5)); |
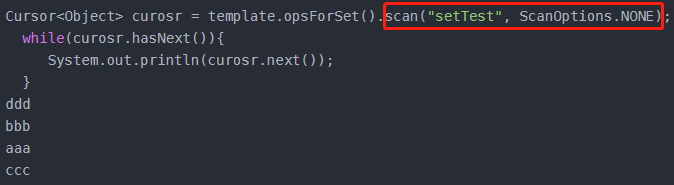
Cursor<V> scan(K key, ScanOptions options);
遍历set
移除
Long remove(K key, Object... values);
移除集合中一个或多个成员,返回移除个数

V pop(K key);
随机移除一个元素,并返回此元素

移动
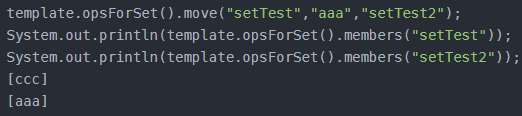
Boolean move(K key, V value, K destKey);
将key中的元素value移动到 destKey中
判断
Boolean isMember(K key, Object o);
判断member元素是否是集合 key 的成员

交集
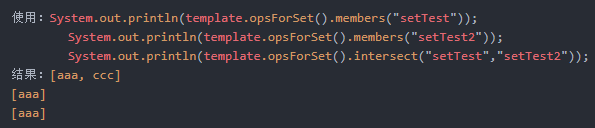
Set<V> intersect(K key, K otherKey);
求key无序集合与otherKey无序集合的交集
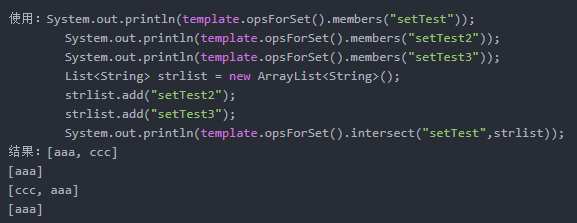
Set<V> intersect(K key, Collection<K> otherKeys);
求key无序集合与多个otherKey无序集合的交集
Long intersectAndStore(K key, K otherKey, K destKey);
求key无序集合与otherKey无序集合的交集,并把值存储到destKey无序集合中
System.out.println("setTest:" + template.opsForSet().members("setTest")); |
Long intersectAndStore(K key, Collection<K> otherKeys, K destKey);
求key无序集合与多个otherKey无序集合的交集,并把值存储到destKey无序集合中
System.out.println("setTest:" + template.opsForSet().members("setTest")); |
并集
Set<V> union(K key, K otherKey);
key无序集合与otherKey无序集合的并集
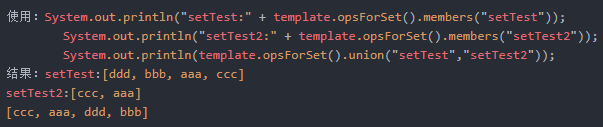
Set<V> union(K key, Collection<K> otherKeys);
key无序集合与多个otherKey无序集合的并集
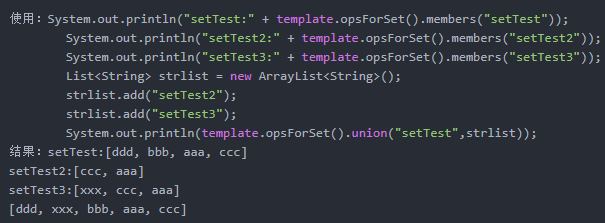
Long unionAndStore(K key, K otherKey, K destKey);
key无序集合与otherkey无序集合的并集,并把值存储到destKey无序集合中
System.out.println("setTest:" + template.opsForSet().members("setTest")); |
Long unionAndStore(K key, Collection<K> otherKeys, K destKey);
key无序集合与多个otherkey无序集合的并集,并把值存储到destKey无序集合中
System.out.println("setTest:" + template.opsForSet().members("setTest")); |
差集
Set<V> difference(K key, K otherKey);
key无序集合与otherKey无序集合的差集
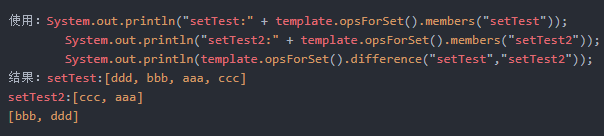
Set<V> difference(K key, Collection<K> otherKeys);
key无序集合与多个otherKey无序集合的差集
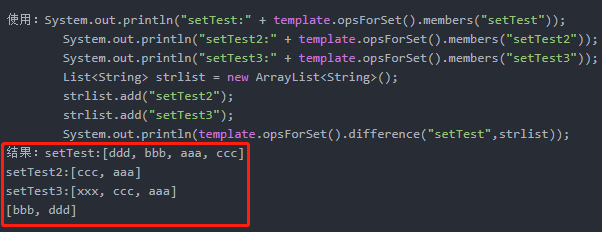
Long differenceAndStore(K key, K otherKey, K destKey);
key无序集合与otherkey无序集合的差集,并把值存储到destKey无序集合中
System.out.println("setTest:" + template.opsForSet().members("setTest")); |
Long differenceAndStore(K key, Collection<K> otherKeys, K destKey);
key无序集合与多个otherkey无序集合的差集,并把值存储到destKey无序集合中
System.out.println("setTest:" + template.opsForSet().members("setTest")); |
ZSet数据结构
操作ZSet数据,相当于有序集合,有序集成员按分数值递增(从小到大)顺序排列
redisTemplate.opsForZSet() |
设置
Boolean add(K key, V value, double score);
新增一个有序集合并设置分值score,存在的话为false,不存在的话为true

Long add(K key, Set<TypedTuple<V>> tuples);
新增一个有序集合
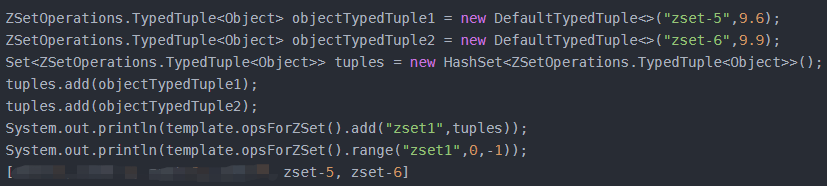
Double incrementScore(K key, V value, double delta);
增加元素的score值,并返回增加后的值

获取
Set<V> range(K key, long start, long end);
通过索引区间返回有序集合成指定区间内的成员,其中有序集成员按分数值递增(从小到大)顺序排列

Set<V> reverseRange(K key, long start, long end);
通过索引区间返回有序集合成指定区间内的成员,其中有序集成员按分数值递减(从大到小)顺序排列

Set<TypedTuple<V>> rangeWithScores(K key, long start, long end);
通过索引区间返回有序集合成指定区间内的成员对象,其中有序集成员按分数值递增(从小到大)顺序排列
Set<ZSetOperations.TypedTuple<Object>> tuples = template.opsForZSet().rangeWithScores("zset1",0,-1); |
Set<TypedTuple<V>> reverseRangeWithScores(K key, long start, long end);
与rangeWithScores调用方法一样,其中有序集成员按分数值递减(从大到小)顺序排列
Set<V> rangeByScore(K key, double min, double max);
通过分数返回有序集合指定区间内的成员,其中有序集成员按分数值递增(从小到大)顺序排列

Set<TypedTuple<V>> rangeByScoreWithScores(K key, double min, double max);
通过分数返回有序集合指定区间内的成员对象,其中有序集成员按分数值递增(从小到大)顺序排列
Set<ZSetOperations.TypedTuple<Object>> tuples = template.opsForZSet().rangeByScoreWithScores("zset1",0,5); |
Set<TypedTuple<V>> reverseRangeByScoreWithScores(K key, double min, double max);
与rangeByScoreWithScores调用方法一样,其中有序集成员按分数值递减(从大到小)顺序排列
Set<V> rangeByScore(K key, double min, double max, long offset, long count);
通过分数返回有序集合指定区间内的成员,并在索引范围内,其中有序集成员按分数值递增(从小到大)顺序排列

Set<V> reverseRangeByScore(K key, double min, double max, long offset, long count);
与rangeByScore调用方法一样,其中有序集成员按分数值递减(从大到小)顺序排列
Set<TypedTuple<V>> rangeByScoreWithScores(K key, double min, double max, long offset, long count);
通过分数返回有序集合指定区间内的成员对象,并在索引范围内,其中有序集成员按分数值递增(从小到大)顺序排列
Set<ZSetOperations.TypedTuple<Object>> tuples = template.opsForZSet().rangeByScoreWithScores("zset1",0,5,1,2); |
Set<TypedTuple<V>> reverseRangeByScoreWithScores(K key, double min, double max, long offset, long count);
与rangeByScoreWithScores调用方法一样,其中有序集成员按分数值递减(从大到小)顺序排列
Long rank(K key, Object o);
返回有序集中指定成员的排名,其中有序集成员按分数值递增(从小到大)顺序排列

Long reverseRank(K key, Object o);
返回有序集中指定成员的排名,其中有序集成员按分数值递减(从大到小)顺序排列
System.out.println(template.opsForZSet().range("zset1",0,-1)); |
Set<V> rangeByScore(K key, double min, double max);
通过分数返回有序集合指定区间内的成员,其中有序集成员按分数值递增(从小到大)顺序排列
System.out.println(template.opsForZSet().rangeByScore("zset1",0,5)); |
Long zCard(K key);
获取有序集合的成员数

Long count(K key, double min, double max);
通过分数返回有序集合指定区间内的成员个数

Long size(K key);
获取有序集合的成员数,内部调用的就是zCard方法

Double score(K key, Object o);
获取指定成员的score值

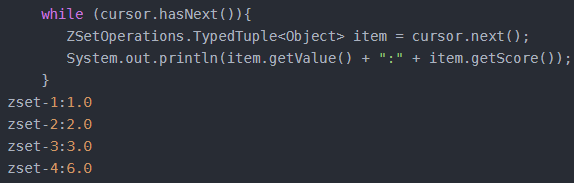
Cursor<TypedTuple<V>> scan(K key, ScanOptions options);
遍历zset
Cursor<ZSetOperations.TypedTuple<Object>> cursor = template.opsForZSet().scan("zzset1", ScanOptions.NONE); |
移除
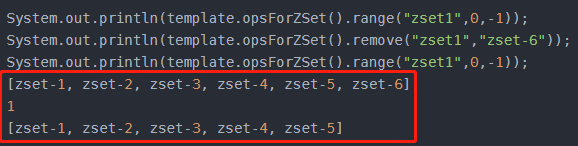
Long remove(K key, Object... values);
从有序集合中移除一个或者多个元素
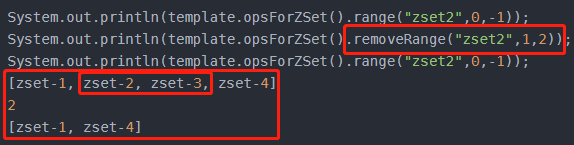
Long removeRange(K key, long start, long end);
移除指定索引位置的成员,其中有序集成员按分数值递增(从小到大)顺序排列
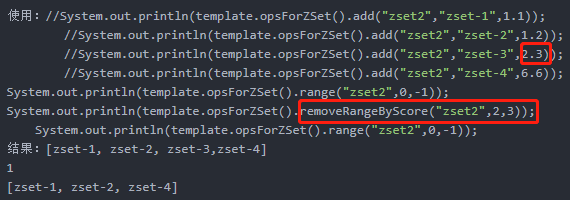
Long removeRangeByScore(K key, double min, double max);
根据指定的score值范围来移除成员
并集
Long unionAndStore(K key, K otherKey, K destKey);
求key有序集和otherKey有序集的并集,并把值存储在新的 destKey中,key相同的话会把score值相加,其中有序集成员按分数值递增(从小到大)顺序排列
System.out.println(template.opsForZSet().add("zzset1","zset-1",1.0)); |
Long unionAndStore(K key, Collection<K> otherKeys, K destKey);
求key有序集和多个有序集的并集,并把值存储在新的 destKey中,key相同的话会把score值相加,其中有序集成员按分数值递增(从小到大)顺序排列
System.out.println(template.opsForZSet().add("zzset3","zset-1",1.0)); |
交集
Long intersectAndStore(K key, K otherKey, K destKey);
求key有序集合和otherKey有序集的交集,并将结果集存储在新的destKey有序集合中,key相同的话会把score值相加,其中有序集成员按分数值递增(从小到大)顺序排列
System.out.println(template.opsForZSet().intersectAndStore("zzset1","zzset2","destZset33")); |
Long intersectAndStore(K key, Collection<K> otherKeys, K destKey);
求key有序集合和多个otherKeys有序集的交集,并将结果集存储在新的destKey有序集合中,key相同的话会把score值相加,其中有序集成员按分数值递增(从小到大)顺序排列
List<String> stringList = new ArrayList<String>(); |
模糊查询
redis替代业务数据存储,会想到模糊匹配的问题,redis是支持模糊匹配的,以下两张图的数据源举例
通配符:
*,?,[]
*:通配任意多个字符?:通配单个字符[]:通配括号内的某一个字
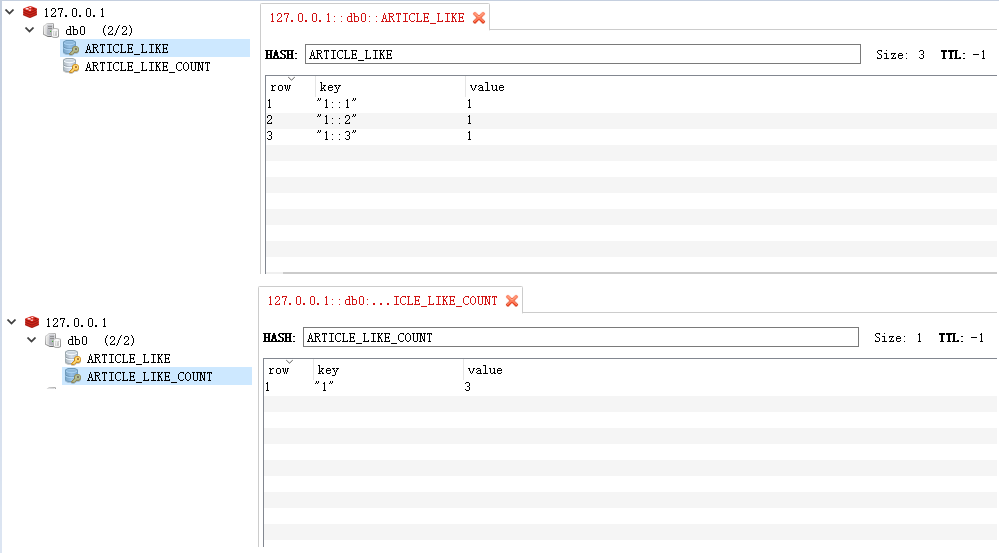
查询Key
Set<K> keys(@NotNull K pattern)

注:由于Redis是单线程,keys命令是以阻塞的方式执行的,keys是以遍历的方式实现的复杂度是 O(n),Redis库中的key越多,查找实现代价越大,产生的阻塞时间越长
查询Hash数据中的HK
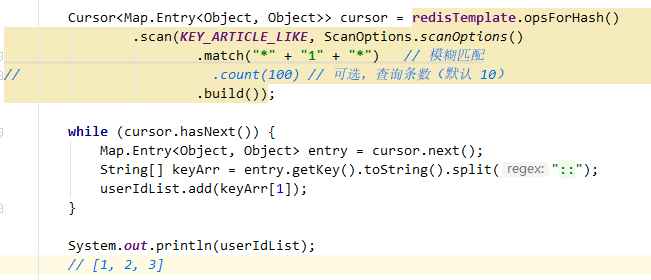
序列化
在相应的key明明存在的情况下,模糊查询就是查找不出来,那数据序列化肯定有问题,查询数据应如下图
需要配置RedisTemplate的序列化,解决如下
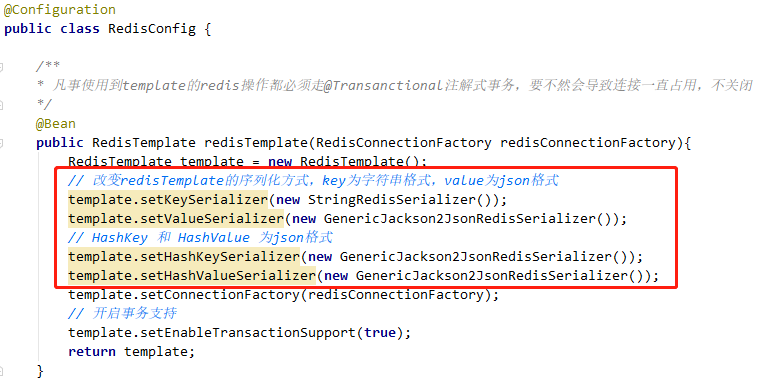
发布订阅
Redis在2.0.0版本开始支持Redis发布订阅(pub/sub),就是一种简易的MQ消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。可用于实现及时性,且可靠性低的功能。
Redis的发布订阅机制包括三部分,发布者、订阅者和Channel(主题或者队列)。
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
命令行实现
订阅主题
Redis采用SUBSCRIBE channel命令订阅某个主题,返回的参数subscribe表示已经成功订阅主题,第二个参数表示订阅的主题名称,第三个表示当前订阅数
127.0.0.1:6379> SUBSCRIBE ORDER-PAY-SUCCESS |
模式匹配订阅
模式匹配功能是允许客户端订阅匹配某种模式的频道,Redis采用PSUBSCRIBE channel命令订阅匹配某种模式的所有频道,通配符如下
?:表示1个占位符*:表示任意个占位符(包括0)?*:表示1个以上的占位符。
127.0.0.1:6379> PSUBSCRIBE ORDER-PAY-* |
发布消息
Redis采用PUBLISH channel message命令在某个主题上发布消息,返回的参数是接收到消息的订阅者个数
127.0.0.1:6379> PUBLISH ORDER-PAY-SUCCESS DD202109071525 |
取消订阅
Redis采用UNSUBSCRIBE channel或PUNSUBSCRIBE channel命令取消某个主题的订阅,由于Redis的订阅操作是阻塞式的,因此一旦客户端订阅了某个频道或模式,就将会一直处于订阅状态直到退出。在 SUBSCRIBE,PSUBSCRIBE,UNSUBSCRIBE 和 PUNSUBSCRIBE 命令中,其返回值都包含了该客户端当前订阅的频道和模式的数量,当这个数量变为0时,该客户端会自动退出订阅状态。
127.0.0.1:6379> UNSUBSCRIBE ORDER-PAY-SUCCESS |
测试
首先三个订阅者订阅ORDER-PAY-SUCCESS主题,当发送者在这个主题内发送订单号时,所有的订阅者都会收到这个主题的消息。

SpringBoot实现
依赖和配置与SpringBoot整合Redis章节一致,在此不再累述
- 配置消息监听
import org.springframework.context.annotation.Bean; |
- 发送消息
import org.junit.Test; |
- 接收消息
import org.springframework.stereotype.Component; |
- 结果
接收消息:DD1631005025949 |
Stream
Redis Stream是 Redis 5.0 版本新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
Redis Stream在此不展开叙述,有兴趣可查阅相关文章
使用规范
键值对使用规范
有两点需要注意:
- 好的 key 命名,才能提供可读性强、可维护性高的key,便于定位问题和寻找数据。
- value要避免出现bigkey、选择高效的序列化和压缩、使用对象共享池、选择高效恰当的数据类型
key 命名规范
规范的 key命名,在遇到问题的时候能够方便定位。Redis属于没有Scheme的 NoSQL数据库。
所以要靠规范来建立其Scheme语意,就好比根据不同的场景我们建立不同的数据库。
把「业务模块名」作为前缀(好比数据库 Scheme),通过「冒号」分隔,再加上「具体业务名」。
这样我们就可以通过 key 前缀来区分不同的业务数据,清晰明了。
总结起来就是:「业务名:表名:id」
key 太长的话有什么问题么?
key 是字符串,底层的数据结构是 SDS,SDS 结构中会包含字符串长度、分配空间大小等元数据信息。
字符串长度增加,SDS 的元数据也会占用更多的内存空间。
所以当字符串太长的时候,可以采用适当缩写的形式。
不要使用 bigkey
因为 Redis 是单线程执行读写指令,如果出现bigkey 的读写操作就会阻塞线程,降低 Redis 的处理效率。
bigkey包含两种情况:
- 键值对的 value很大,比如 value保存了 2MB的 String数据;
- 键值对的 value是集合类型,元素很多,比如保存了 5 万个元素的 List 集合。
虽然 Redis 官方说明了 key和string类型 value限制均为512MB。
防止网卡流量、慢查询,string类型控制在10KB以内,hash、list、set、zset元素个数不要超过 5000。
如果业务数据就是这么大咋办?
可以通过 gzip 数据压缩来减小数据大小
/** |
如果集合类型的元素的确很多,可以将一个大集合拆分成多个小集合来保存。
使用高效序列化和压缩方法
为了节省内存,可以使用高效的序列化方法和压缩方法去减少 value的大小。
protostuff和 kryo这两种序列化方法,就要比 Java内置的序列化方法效率更高。
上述的两种序列化方式虽然省内存,但是序列化后都是二进制数据,可读性太差。
通常会序列化成 JSON或者 XML,为了避免数据占用空间大,可以使用压缩工具(snappy、 gzip)将数据压缩再存到 Redis 中。
使用整数对象共享池
Redis 内部维护了 0 到 9999 这 1 万个整数对象,并把这些整数作为一个共享池使用。
即使大量键值对保存了 0 到 9999 范围内的整数,在 Redis 实例中,其实只保存了一份整数对象,可以节省内存空间。
需要注意的是,有两种情况是不生效的:
Redis 中设置了 maxmemory,而且启用了 LRU策略(allkeys-lru 或 volatile-lru策略),那么,整数对象共享池就无法使用了。
因为 LRU 需要统计每个键值对的使用时间,如果不同的键值对都复用一个整数对象就无法统计了。
- 如果
集合类型数据采用ziplist编码,而集合元素是整数,这个时候,也不能使用共享池。
因为 ziplist 使用了紧凑型内存结构,判断整数对象的共享情况效率低。
命令使用规范
生产禁用的指令
Redis 是单线程处理请求操作,如果执行一些涉及大量操作、耗时长的命令,就会严重阻塞主线程,导致其它请求无法得到正常处理。
KEYS:该命令需要对 Redis 的全局哈希表进行全表扫描,严重阻塞 Redis 主线程;
应该使用 SCAN 来代替,分批返回符合条件的键值对,避免主线程阻塞。
FLUSHALL:删除 Redis 实例上的所有数据,如果数据量很大,会严重阻塞 Redis 主线程;FLUSHDB:删除当前数据库中的数据,如果数据量很大,同样会阻塞 Redis 主线程。
加上 ASYNC 选项,让 FLUSHALL,FLUSHDB 异步执行。
也可以直接禁用,用rename-command命令在配置文件中对这些命令进行重命名,让客户端无法使用这些命令。
慎用 MONITOR 命令
MONITOR 命令会把监控到的内容持续写入输出缓冲区。
如果线上命令的操作很多,输出缓冲区很快就会溢出了,这就会对 Redis 性能造成影响,甚至引起服务崩溃。
所以,除非十分需要监测某些命令的执行(例如,Redis 性能突然变慢,想查看下客户端执行了哪些命令)才使用。
慎用全量操作命令
比如获取集合中的所有元素(HASH 类型的 hgetall、List 类型的 lrange、Set 类型的 smembers、zrange 等命令)。
这些操作会对整个底层数据结构进行全量扫描 ,导致阻塞 Redis 主线程。
如果业务场景就是需要获取全量数据咋办?
有两个方式可以解决:
- 使用 SSCAN、HSCAN等命令分批返回集合数据;
- 把大集合拆成小集合,比如按照时间、区域等划分。
数据保存规范
冷热数据分离
虽然 Redis 支持使用 RDB 快照和 AOF 日志持久化保存数据,但是,这两个机制都是用来提供数据可靠性保证的,并不是用来扩充数据容量的。
不要什么数据都存在 Redis,应该作为缓存保存热数据,这样既可以充分利用 Redis 的高性能特性,还可以把宝贵的内存资源用在服务热数据上。
业务数据隔离
不要将不相关的数据业务都放到一个 Redis 中。一方面避免业务相互影响,另一方面避免单实例膨胀,并能在故障时降低影响面,快速恢复。
设置过期时间
在数据保存时,建议根据业务使用数据的时长,设置数据的过期时间。
写入 Redis 的数据会一直占用内存,如果数据持续增多,就可能达到机器的内存上限,造成内存溢出,导致服务崩溃。
控制单实例的内存容量
建议设置在 2~6 GB 。这样一来,无论是 RDB 快照,还是主从集群进行数据同步,都能很快完成,不会阻塞正常请求的处理。
防止缓存雪崩
避免集中过期 key 导致缓存雪崩。
运维规范
- 使用
Cluster 集群或者哨兵集群,做到高可用; - 实例
设置最大连接数,防止过多客户端连接导致实例负载过高,影响性能。 不开启 AOF 或开启 AOF 配置为每秒刷盘,避免磁盘 IO 拖慢 Redis 性能。- 设置
合理的 repl-backlog,降低主从全量同步的概率 - 设置
合理的 slave client-output-buffer-limit,避免主从复制中断情况发生。 - 根据实际场景设置
合适的内存淘汰策略。 - 使用
连接池操作 Redis。
监控指标
监控指标包括性能指标 Performance、内存指标 Memory、基本活动指标 Basic activity、持久性指标 Persistence、错误指标 Error五类
性能指标 Performance
| Name | Description |
|---|---|
| latency | Redis响应一个请求的时间 |
| instantaneous_ops_per_sec | 平均每秒处理请求总数 |
| hi rate(calculated) | 缓存命中率(计算出来的 |
内存指标 Memory
| Name | Description |
|---|---|
| used_memory | 已使用内存 |
| mem_fragmentation_ratio | 内存碎片率 |
| evicted_keys | 由于最大内存限制被移除的key的数量 |
| blocked_clients | 由于BLPOP,BRPOP,or BRPOPLPUSH而备阻塞的客户端 |
基本活动指标 Basic activity
| Name | Description |
|---|---|
| connected_clients | 客户端连接数 |
| conected_laves | slave数量 |
| master_last_io_seconds_ago | 最近一次主从交互之后的秒数 |
| keyspace | 数据库中的key值总数 |
持久性指标 Persistence
| Name | Description |
|---|---|
| rdb_last_save_time | 最后一次持久化保存磁盘的时间戳 |
| rdb_changes_sice_last_save | 自最后一次持久化以来数据库的更改数 |
错误指标 Error
| Name | Description |
|---|---|
| ejected_connections | 由于达到maxclient限制而被拒绝的连接数 |
| keyspace_misses | key值查找失败(没有命中)次数 |
| master_link_down_since_seconds | 主从断开的持续时间(以秒为单位) |
监控方式
redis-benchmark
Redis自带性能测试工具redis-benchmark,基本命令如下:
redis-benchmark [option] [option value] |
注:该命令是在 redis 的目录下执行的,而不是 redis 客户端的内部指令。
可选参数如下所示:
| 选项 | 描述 | 默认值 |
|---|---|---|
| -h | 指定服务器主机名 | 127.0.0.1 |
| -p | 指定服务器端口 | 6379 |
| -s | 指定服务器socket | |
| -c | 指定并发连接数 | 50 |
| -n | 指定请求数 | 10000 |
| -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| -k | 1=keep alive 0=reconnect | 1 |
| -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| -P | 代表每个请求pipeline的数据量 | 1 |
| -q | 仅仅显示每秒执行的请求信息。 | |
| –csv | 以 CSV 格式输出,便于后续处理, 如导出到Excel | |
| -l(L 的小写字母) | 生成循环,永久执行测试 | |
| -t | 仅运行以逗号分隔的测试命令列表。 | |
| -I(i的大写字母) | Idle 模式。仅打开 N 个 idle 连接并等待。 |
同时执行 10000 个请求来检测性能:
$ redis-benchmark -n 10000 -q |
测试命令详解:
| 命令 | 描述 |
|---|---|
| SET | 将字符串值value关联到key; |
| GET | 返回key所关联的字符串值,如果key存储的值不是字符串类型,返回一个错误; |
| INCR | 将key中存储的数字值增一。不能转换为数字则报错; |
| LPUSH | 将一个或多个值value插入到列表key的表头; |
| RPUSH | 将一个或多个值value插入到列表key的表尾; |
| LPOP | 移除并返回列表key的头元素; |
| RPOP | 移除并返回列表key的尾元素; |
| SADD | 将一个或多个member元素加入到集合set当中,已经存在于集合的member元素将被忽略; |
| SPOP | 移除并返回集合中的一个随机元素; |
| LPUSH | 将一个或多个value插入到列表key的表头; |
| LRANGE_100 | 返回列表key中指定区间内的元素,前100条元素; |
| LRANGE_300 | 返回列表key中指定区间内的元素,前300条元素; |
| LRANGE_500 | 返回列表key中指定区间内的元素,前500条元素; |
| LRANGE_600 | 返回列表key中指定区间内的元素,前600条元素; |
| MSET | 同时设置一个或多个key-value对,value为字符串。 |
PING_INLINE 和 PING_BULK
在统一请求协议之前,Redis使用一个不同的协议来发送命令,这个协议仍然被支持因为通过telnet它很容易手写。在这个协议中存在两种命令:
- inline 命令:命令很简单,就是用空格把参数分隔开来的字符串。二进制安全是不可能的。
- bulk 命令:bulk命令和inline命令几乎是一样的,但是最后一个参数为了能够接受二进制安全的内容,所以需要以特殊的方式进行处理。
- 实例分析
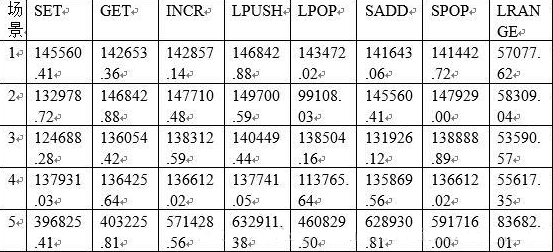
| 场景 | 描述 |
|---|---|
| 1 | 单一key,模拟50客户端,每秒的请求数 |
| 2 | 随机key,模拟50客户端,每秒的请求数 |
| 3 | 随机key,模拟100客户端,每秒的请求数 |
| 4 | 随机key,模拟10客户端,每秒的请求数 |
| 5 | 随机key,模拟50客户端,并发执行,每秒的请求数 |
从表格可看出:
- 对于相同客户端的情况下,随机key的每秒请求数,SET和LPOP减少,GET、INCR、LPUSH、SADD、SPOP和LRANGE增加了;
- 在随机生成key值的情况下,SET、SADD操作随着客户端数增加,每秒请求数减少;考虑到cache命中的情况,其他命令变化趋势没有规律;
- 其他条件一致,并发执行情况下,各种命令都是有大幅度增加。
结论:在真实环境下,应对大数据,大并发,可以通过增加缓存大小,并发执行来提高吞吐量。
redis-stat
可视化监控工具redis-stat,优缺点如下:
优点:基于redis的INFO命令,较使用MONITOR的监控工具对redis服务器性能影响较小;
缺点:如果同时监控多个redis实例,不能单独显示每一个实例的数据信息,貌似是总和。
官网提供了两种安装方式,一种是通过Ruby gem安装,第二种方式是通过下载Jar包直接运行,需要本地有Java环境。
- Ruby安装
# 安装ruby |
不出意外的话,就安装成功了。运行
redis-stat --server --daemon --auth=redis密码(如果有的话) |
就可以在后台启动redis-stat,浏览器输入如下地址访问:
http://Redis IP:63790 |
- Jar包安装
下载Jar包
https://github.com/junegunn/redis-stat/releases/download/0.4.14/redis-stat-0.4.14.jar |
上传Jar包到需要监控的服务器后,运行如下命令(注:服务器防火墙需要开放端口63790)
java -jar redis-stat-0.4.14.jar --server --auth=redis密码 |
最后浏览器输入访问地址即可
http://Redis IP:63790 |
- 用法与参数描述
# redis-stat [HOST[:PORT][/PASS] ...] [INTERVAL [COUNT]] |
选项参数
-a, --auth=PASSWORD 设置密码 |
|参数 |描述 |
| —– | —– |
|time | 更新参数时间|
|us(used_cpu_user) | Redis 服务器使用的用户 CPU|
|sy(used_cpu_sys) | Redis 服务器使用的系统 CPU|
|cl(connected_clients) | 客户端连接数(不包括从站的连接数)|
|bcl(blocked_clients) | 阻塞呼叫中挂起的客户端数量(BLPOP,BRPOP,BRPOPLPUSH)|
|mem(used_memory) | Redis 使用其分配程序分配的字节总数(标准 libc,jemalloc 或替代分配程序,如 tcmalloc|
|rss(used_memory_rss) | 从操作系统的角度,返回Redis已分配的内存总量(俗称常驻集大小)。这个值和top、ps等命令的输出一致,包含了used_memory和内存碎片,从系统角度,显示Redis进程占用的物理内存总量.|
|keys| 保存的键大小|
|cmd/s(total_commands_processed_per_ses) | 服务器已每秒执行的命令数量|
|exp/s(expired_keys_per_second) | 因为过期而每秒被自动删除的数据库键数量|
|evt/s(evicted_keys_per_second) | 因为最大内存容量限制而每秒被驱逐(evict)的键数量|
|hit%/s(keyspace_hits_ratio_per_second) | 查找数据库键成功的次数比例|
|hit/s(keyspace_hits_per_second) | 查找数据库键成功的次数|
|mis/s(keyspace_misses_per_second) | 查找数据库键每秒失败的次数|
|aofcs(aof_current_size) | AOF 文件目前的大小|
redis-faina
使用redis自带命令monitor的输出结果做分析的python脚本,在命令行下使用,可以做实时分析使用。
- 安装
该工具是用python写的,不需要安装什么依赖包,只需要将redis-faina.py下载即可:
git clone https://github.com/facebookarchive/redis-faina.git |
用法与选项参数
# cd redis-faina/ |
redis-faina的两种用法:
- 通过redis MONITOR命令以及管道进行分析
# redis-cli -p port MONITOR | head -n <NUMBER OF LINES TO ANALYZE> | ./redis-faina.py [options] |
- 读取文件中MONITOR日志进行分析
redis-cli -p port MONITOR | head -n <10000> > 导出的文件路径 |
输出如下:
Overall Stats |
注:由于redis MONITOR输出的只有请求开始的时间,所以在一个非常繁忙的redis实例中,根据该请求的开始时间以及下一个请求的开始时间,可以大概估算出一个请求的执行时间。由此可以看出,
redis-faina统计的时间并不是十分精确的,尤其在分析一个非常闲的redis实例时,分析的结果可能差的很多
redislive
RedisLive是由python编写的开源图形化监控工具,非常轻量级,核心服务部分只包含一个web服务和一个基于redis自带的info命令以及monitor命令的监控服务。
工作原理基于 Redis 的 INFO 和 MONITOR 命令,通过向 Redis 实例发送 INFO 和 MONITOR 命令来获取Redis实例当前的运行数据。
还支持多实例监控,切换方便,而且配置起来也非常容易。监控信息支持redis存储和持久化存储(sqlite)两种方式。
- 安装pip工具
yum install epel-release -y |
- 下载源码
通过 Git 下载最新的 RedisLive 源代码:
git clone https://github.com/kumarnitin/RedisLive.git |
- 安装python依赖包
进入RedisLive 目录,查看requirements.txt 文件
argparse==1.2.1 |
RedisLive 依赖的 Python 扩展包都已经写在 requirements.txt 文件中了。指定豆瓣源来安装python依赖包
pip install -r requirements.txt -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com |
- 修改配置文件
进入 RedisLive/src 目录,可以看到 redis-live.conf.example文件
{ |
| 名称 | 描述 |
|---|---|
| RedisServers | 监控的 Redis 实例列表,RedisLive 支持同时监控多个 Redis 实例 |
| RedisStatsServer | 用来存储监控数据的 Redis 实例,此配置不同于 RedisServers,RedisLive 并不监控 RedisStatsServer,RedisStatsServer 只是用作存储监控数据使用 |
| DataStoreType | 监控数据的存储方案,可以配置为redis或者sqlite |
| SqliteStatsStore | 存储监控数据的 sqlite 配置 |
复制redis-live.conf.example文件,并命名为redis-live.conf
cp redis-live.conf.example redis-live.conf |
编辑redis-live.conf文件
{ |
- 启动服务
RedisLive 的运行包括两个部分(在 RedisLive/src 目录),redis-monitor.py用于向 Redis 实例发送 INFO 和 MONITOR 命令并获取其返回,redis-live.py用于运行 Web 服务器
# 启动监控,duration是心跳时间 &放置在后台执行 |
duration参数指定了监控脚本的运行持续时间,例如设置为 30 秒,即经过 30 秒后,监控脚本会自动退出,并在终端打印 shutting down… 的提示。可以采用 crontab 来定时执行脚本任务:
# 每5分钟进入/RedisLive/src/目录,执行启动监控脚本,并设置心跳时间为 30 秒 |
>/dev/null 2>&1的含义?
>符号为重定向;/dev/null代表空设备文件;1表示标准输出,默认为1,所以">/dev/null"等同于"1>/dev/null";2表示标准错误;&表示等同于的意思,2>&1表示2的输出重定向等同于1;
>/dev/null 2>&1的意思就是:标准输出重定向到空设备文件,也就是不输出任何信息到终端;标准错误输出重定向等同于标准输出,因为之前标准输出已经重定向到了空设备文件,所以标准错误输出也重定向到空设备文件。
打开浏览器,在地址栏输入 http://localhost:8888/index.html,便可以看到 Redis 实例的监控数据。
redis-cli
slowlog
slowlog是redis用于记录记录慢查询执行时间的日志系统。由于slowlog只保存在内存中,因此slowlog的效率很高,完全不用担心会影响到redis的性能。Slowlog是Redis从2.2.12版本引入的一条命令。
在redis.conf中有关于slowlog的设置:
# 只有query执行时间大于slowlog-log-slower-than的才会定义成慢查询,才被slowlog进行记录,单位:微秒,默认是10000微妙,也就是10ms |
用法:
- get:获取慢查询日志,也可以使用SLOWLOG GET N命令获取指定的条数
127.0.0.1:6379> SLOWLOG GET 1 |
- len:获取慢查询日志条目数
127.0.0.1:6379> SLOWLOG LEN |
- reset:重置慢查询日志
info
可以一次性获取所有的信息,也可以按块获取信息
| 块信息 | 描述 |
|---|---|
| server | 服务器运行的环境参数 |
| clients | 已连接客户端信息 |
| memory | 服务器运行内存统计数据 |
| persistence | RDB 和 AOF 持久化的相关信息 |
| stats | 一般统计数据 |
| Replication | 主从复制相关信息 |
| CPU | CPU使用情况 |
| cluster | 集群信息 |
| keyspace | 数据库相关的统计信息息 |
终端info命令使用
./redis-cli info 按块获取信息 | grep 需要过滤的参数 |
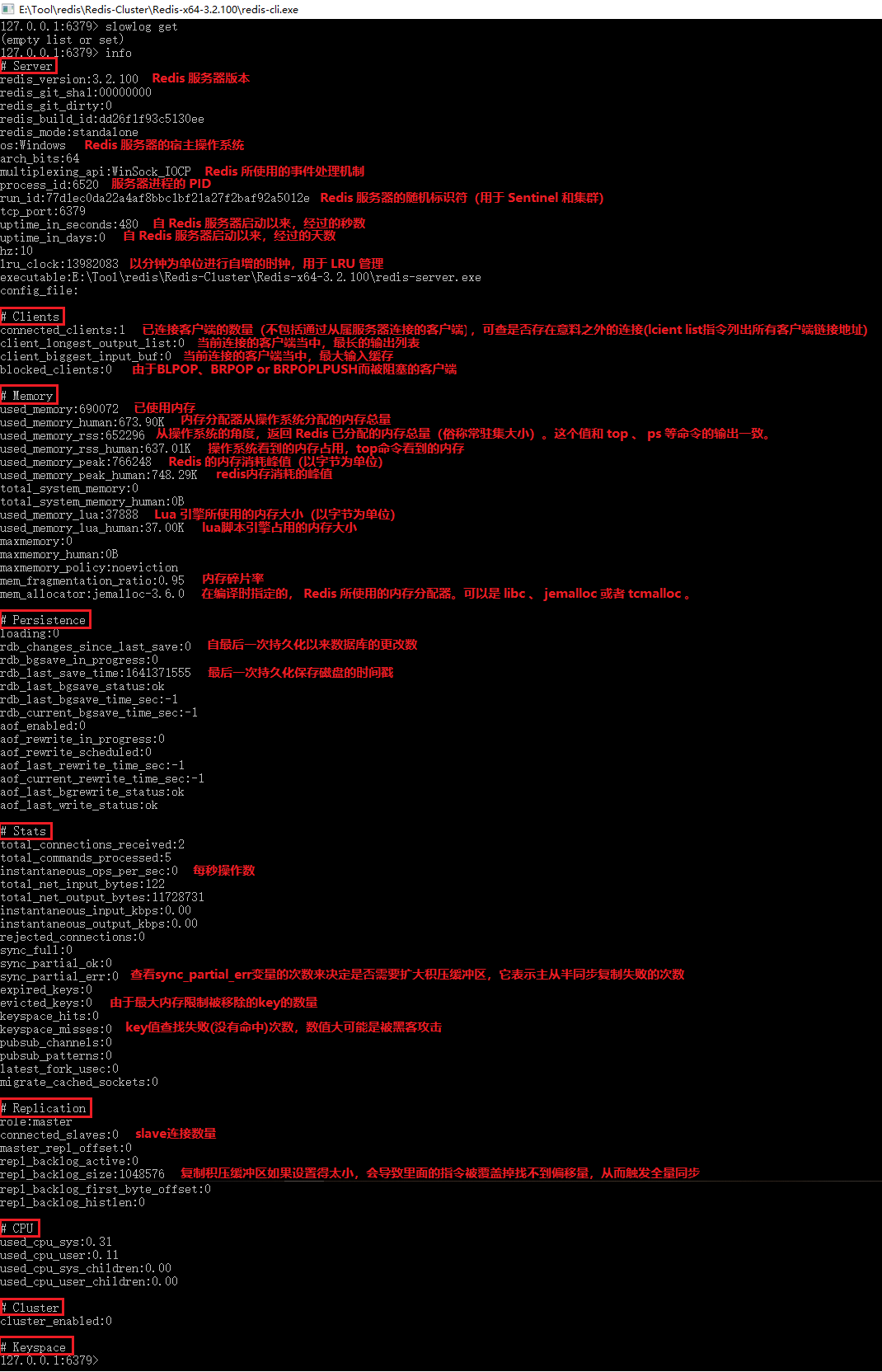
在理想情况下,
used_memory_rss 的值应该只比 used_memory稍微高一点儿。
- 当
rss > used,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。内存碎片的比率可以通过mem_fragmentation_ratio的值看出。- 当
used > rss时,表示Redis的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟。- 当 Redis 释放内存时,分配器可能会,也可能不会,将内存返还给操作系统。如果 Redis 释放了内存,却没有将内存返还给操作系统,那么
used_memory的值可能和操作系统显示的 Redis 内存占用并不一致。查看used_memory_peak的值可以验证这种情况是否发生。





